
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- arbitrary scale
- graph neural network
- ADE20K
- INR
- Graph
- SegFormer
- GNN in image
- SISR
- Feature reuse
- Cityscapes
- implicit representation
- CrossNet
- Cell-tissue
- hypergraph
- Tissue segmentation
- LIIF
- session-based recommendation
- ConvNeXt
- FRFSR
- TRANSFORMER
- Reference-based SR
- Reference Super-Resolution
- Super-Resolution
- Referense Super Resoltuion
- deep learning
- GNN
- Cell detection
- Zero-Shot sr
- TAAM
- DIINN
- Today
- Total
딥러닝 분석가 가리
Single Image Super-Resolution via a Dual Interactive Implicit Neural Network Review 본문
Single Image Super-Resolution via a Dual Interactive Implicit Neural Network Review
AI가리 2023. 11. 3. 13:12"Single Image Super-Resolution via a Dual Interactive
Implicit Neural Network"
Abstract
이 논문에서는, 임의의 크기로 SR 하기 위해 implicit neural network(INR)을 사용한 SISR을 소개한다. 이것을 하기 위해, 이미지내의 위치와 연관된 특징을 이미지의 상호간의 픽셀 속성들에 map 해주는 디코딩 함수를 통해 이미지를 표현한다. 픽셀의 위치가 연속적인 표현이 되므로, 제안하는 방법은 이미지가 다양한 해상도에서 임의의 위치를 참조할 수 있다. 특정 이미지의 해상도를 검색하려면, 출력 이미지에서 픽셀의 중심을 각각 지정하는 위치의 그리드에 디코딩 함수를 적용한다. 다른 기술과 대조적으로, dual interactive neural network는 content와 positional 특징의 결합을 없앤다. 결과적으로, single 모델을 사용해 선택적 크기를 출력하는 SR 문제를 해결한 implicit representation 이미지를 얻는다. Benchmark 데이터셋에서 SotA를 보여주며 접근 방법이 효율적이고 유용한것을 입증한다.
Introduction
Single image super-resolution (SISR)은 low-resolution (LR)로 부터 high-resolution (HR)로 복원하는 연구로 두가지 목적이 있다. 첫번째는 영상의 시각적 화질을 개선시키기 위해서이고, 두번째는 기계가 인식하기 위해 영상의 표현을 향상시키는것이다. SISR은 다양한 분야에서 활용되고 있으며, ill-posed 문제를 해결하기위해 많은 연구가 이루어지고 있다.
최근 딥러닝 방법의 SISR은 높은 성능을 보인다. Perception 시스템에서 이미지는 2D 배열의 픽셀로 표현된다. 이는 quality, sharpness, memory 공간들이 이미지의 해상도에 의해 통제된다. 결과적으로, 생성되는 HR 이미지의 크기는 훈련데이터에 의해 고정된다. 예를들어, 신경망이 HR 이미지 복원은 2배 크기로만 하는것을 수행한다면 이는 2배 크기로만 복원시킬 수 있다. 그러므로 다양한 resolution을 위해 여러 모델을 훈련시키는것 대신에, 임의의 크기를 처리하는 단일 SISR 구조를 갖는 것은 실용성 측면에서 매우 유용할 수 있다. 이는 특히 제한된 자원을 사용해 어려운 작업을 실행해야 하는 다수의 on-board 카메라를 갖은 임베디드 vision 플랫폼에 사용된다.
좌표 기반의 표현이라고 알려진 implicit neural representation은 3D shape를 모델링 하는 분야에서 연구되고 있다. 이러한것에 영감을 받아, 2D image에 INR을 학습하는 것은 implicit 시스템이 임의의 해상도를 출력할 수 있으므로, SISR 문제에 대한 자연스러운 해결책이다. 이 아이디어는 몇몇의 연구에서 먼저 언급 되었지만, 이 연구에서는 SISR을 위헤 더 expressive neural network를 제안한다.
Contribution
- 영상의 content feature는 modulation branch에서 처리되고 positional feature는 synthesis branch에서 처리되는, 두 feature가 상호작용하면서, 새로운 dual interactive implicit neural network (DIINN) 제안
- Pixel-level 표현을 가진 implicit neural network를 배움, 가장 가까운 LR pixel에 대해 locally 연속적인 SR 합성을 가능하게 함

Dual Interactive Implicit Neural Network
네트워크는 encoder와 dual interactive implicit decoder로 이루어져있으며 이는 그림 2와 같다. Encoder는 이미지의 content를 학습하여 deep feature map을 출력한다. Implicit decoder는 인코더에서 제공되는 연관된 feature에 따라, 이미지 공간 내의 임의의 query location에서 신호(r, g, b값)를 예측한다. Target 해상도를 위해 SR 출력 이미지의 모든 pixel의 신호를 query한다. 네트워크는 다음 식과 같이 표현할 수 있다.
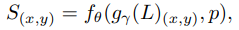
S_(x,y)는 (x,y)에서의 SR 예측 신호, L은 LR 이미지, g_ γ()는 encoder 함수, g_ γ(L)_(x,y)는 (x,y)에서 추출된 feature (content feature), p는 positional features, f_θ()는 implicit decoder 함수이다. 제안하는 방법은 이미지의 픽셀을 점이 아닌 정사각형으로 간주하고 픽셀의 위치는 그 중심을 참조한다.

Encoder
Encoder는 decoder에게 이미지의 각 query location과 연관된 content feature representation을 공급한다. Encoder는 이전 연구들과 비슷한 CNN 구조를 사용한다. 입력은 LR 이미지, 출력은 이미지의 공간적 content를 보존한 deep feature map이다. 입력의 크기는 출력의 크기와 같으므로, query 위치에 대한 좌표 집합이 주어지면 interpolation을 통해 해당하는 feature를 sampling 할 수 있다.
Feature Unfolding. 이전 연구들을 따라, interpolation하기 전에 kernel 크기를 3으로 한 feature unfolding을 적용해 featuer map을 더 부유하게 한다. Implicit decoder가 연속적인 queries를 처리하고 예측은 locally 연속적이기 때문에, 추가적인 smoothness constraint 뿐만 아니라 artifacts를 피하기위해 nearest interpolation을 사용한다. 임의의 query location에 대해, encoder는 deep feature map의 인접한 feature를 decoder에게 효율적으로 공급한다.
Decoder
Decoder는 target 해상도의 SR 이미지에 있는 각 pixel의 신호를 예측한다. Implicit decoder는 encoder로 부터 나온 content feature와 예측을 위한 positional feature를 둘다 사용한다. SISR의 경우, query 위치의 positional features는 일반적으로 가장 가까운 LR pixel(가운데)과의 상대적 위치에 대한 정보 및 scale factor에 대한 정보를 포함한다. 이미지 중심에 대해 pixel의 위치를 참조하는 좌표를 global 좌표라고 부른다. 반대로 pixel의 위치를 가장 가까운 LR pixel에 대해 참조하는 좌표를 local 좌표라고 부른다. 제안하는 방법에서, global 좌표는 local 좌표가 decoder에 대한 입력으로 사용되는 동안 각 pixel을 uniquely 식별하고 가장 가까운 LR pixel을 계산할 수 있도록 한다. 이에 대한 예는 그림 3과 같다. (Global: HR, Local: LR)

Modulated Periodic Activations Network. 최근 periodic activation 함수를 가진 neural network는 고화질의 영상을 만드는데 좋은 성능을 보였다. 그래서 SISR task를 처리하기 위해 decoder에 periodic activation neural network로 알려진 dual MLP 구조를 사용한다. Decoder는 N개의 layer로 구성되고 다음 식과 같이 정의될 수 있다.
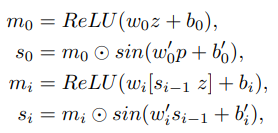
- 기존의 실험에서 이미지 재구성의 z vector는 patch를 나타내고 반면에 제안하는 방법에서는 LR 이미지의 pixel을 나타낸다. 일반적으로 coarse-grain feature는 high level의 의미론적 정보와 연관되어 지는데 이는 low-level의 세부사항을 잃어버린 정보로써 SISR에서 치명적이다. 게다가, pixel-level의 표현은 SISR 연구에서 아주 잘 나타났기 때문에, finest-grain 표현 (pixel-level)을 선택한다.
- 식 (4)에서 synthesis layer 이전의 출력(modulation layer 이전의 출력 대신에)과 modulation layer에 입력되기 이전의 latent feature vector를 concat 한다. Synthesis network의 출력이 다른 query location을 향해 점진적으로 더 정제 되므로 latent feature vector가 residual feedback 역할을 하는 동안 modulation network에 더 나은 정보를 제공한다고 한다. 이러한 구조의 이점은 실험결과에서 보여준다.
LIIF와 비교하면 제안하는 방법은 decoder에 더 표현력이 뛰어난 neural network를 사용하므로 성능이 더 향상된다. Content feature와 positional feature가 연결되어 single-branch decoder로 공급되는 LIIF와 달리, 이 특징을 분리하고 두 branch 간의 상호작용을 하며 두 branch를 사용한다.
Architecture Details. Encoder로 RDN을 사용한다. Decoder는 256개의 hidden unit을 가진 4개의 MLP layer로 구성된다. MLP는 kernel size가 1이고 channel이 256인 convolutional layer를 사용한다. Encoder를 거친 LR 이미지는 LR 이미지와 같은 크기를 가진 64 channel의 deep feature map이 된다. 다음, encoder의 출력에 nearest interpolation을 수행하여 target resolution과 같은 크기가 되도록 키운다. 식 (2)의 z는 upsampled deep feature map을 입력으로 받는다. 그런 다음, 전역 좌표의 2D grid를 구성하고 각각의 local 좌표를 계산하여 x 및 y에 대해 2개의 channel을 같는 target 해상도와 동일한 spatial size tensor를 생성한다. 1 / upscale_ratio 를 추가로 첨부하고 concatenated를 p로 정의한다. 식 (3)에서 이 concatenated tensor는 입력이다. 마지막으로, 예측된 SR 이미지를 생성하기위해 synthesis network (s_N-1)의 출력을 1×1 kernel convolutional layer를 통과 시킨다.
Experiments
Datasets and Metrics
- Train : DIV2K, Test : DIV2K(val), Set5, Set14, BSDS100, Urban100
- Metrics : PSNR, SSIM, LR-PSNR(compared with SR(downsample) and HR(downsample))
Training Details
- Scale factor {2, 3, 4}, Input : minibatch HR(random cropp 48×48), Augment : horizontal, vertical diagonal flip
- Minibatch : 4, 3개의 scale에 걸쳐 12쌍의 LR 이미지와 HR 이미지가 도출
- Epochs : 1000, Optimizer : Adam, Learning rate : 1e-4 그리고 200 epoch 마다 절반으로 감소, Loss : L1
Benchmark Results
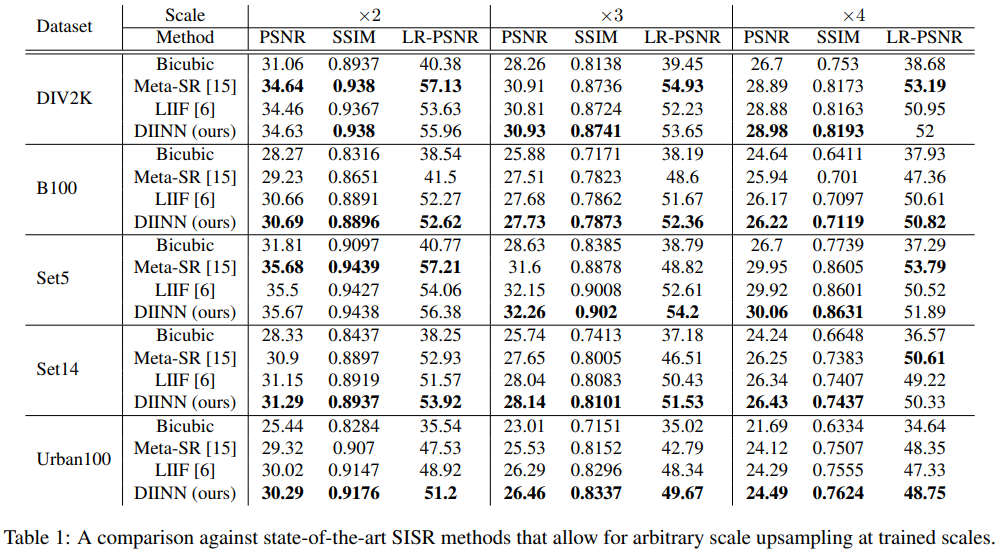
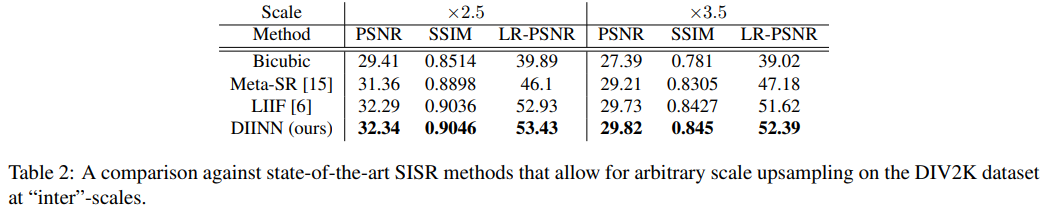
Arbitary scale upsampling이 가능한 Meta-SR, LIIF와 비교하며 결과는 표 1, 2, 3과 같다. 표 1은 ×2, ×3, ×4, 표 2는 inter scale ×2.5, ×3.5, 표 3은 outer scale ×6, ×8, ×10, ×15배 한 결과이다. HR은 각 크기에 맞게 down scale 되어 입력되고 SR은 HR과 같은 크기로 생성된다. 표 1에서는 DIV2K, Set5 데이터에서 ×2배 결과에서 제안하는 방법인 DIINN이 Meta-SR 보다 더 낮은 결과를 보인다. 표 2와 3에서는 DIINN이 가장 좋은 성능을 보였고, 표 4에는 inference 시간을 나타냈다. 표 1부터 4의 결과를 보면 DIINN이 다른 SotA 모델들 보다 성능과 일반화 면에서 더 뛰어나다는것을 보여준다.


Qualitative Results
그림 4는 bicubic, Meta-SR, LIIF, DIINN의 정성적 결과를 보여준다. SR 예측은 증가하는 scale factor에서 동일한 LR 입력으로 부터 모든 method를 통해 얻어진다. 기대와 같이, bicubic은 오직 LR을 smooths 하게 했으며 sharp한 detail은 살리지 못했다. Meta-SR은 artifact가 있으며, 특히 LR pixel의 경계면에 해당되는 부분에 많다. LIIF와 DIINN이 implicit decoder의 이점을 보여주기 때문에 상당히 더 나은 결과를 보였다. LIIF와 비교하면 DIINN이 sharper edge와 detail을 더 많이 생성한다. DIINN의 결과를 확대 해보면 Meta-SR과 같은 artifact를 발견할 수 있지만 이는 훨씬 더 적다. LIIF는 이러한 artifacts를 local ensemble이라 불리는 small window를 통해 예측을 평균화해서 극복한다. 하지만, 이 방법에서 높은 연산량으로 인해 가장자리가 무뎌진것을 발견한다. 반면 DIINN은 앞서 말한 artifact가 나타나지 않는다.

Ablation Study
구조에 대해 자세하게 설명하기 위해 dual implicit decoder에 대해 다양한 실험을 수행한다. 표 5에서 Urban100 데이터셋에 대한 6가지 결과에 대한 정량적 결과를 요약한다. 모델 (f)는 앞서 설명한 최종 모델이다.
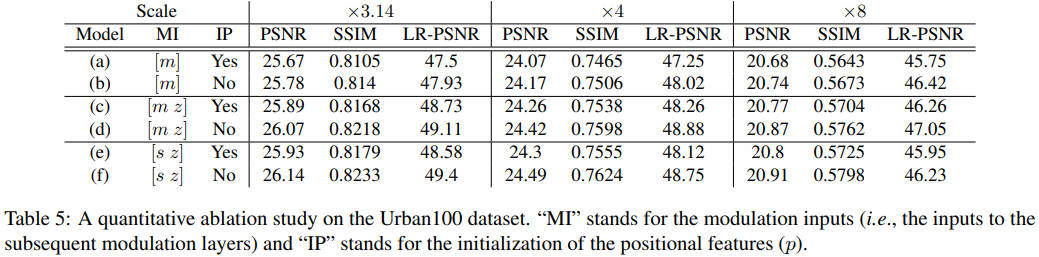
Modulation Inputs
먼저, modulation network의 입력을 다음과 같은 3가지 방법으로 조정한다.
- 모델 (a)와 (b)는 이전 modulation layer의 출력만 입력으로 받는 형태이다. 이는 content feature와의 residual connection이 제거된 형태이다. 이에 따른 식은 식 (6)과 같다.
- 모델 (c)와 (d)는 이전 modulation layer의 출력과 content feature의 concat을 입력으로 취한다. 이는 식 (7)과 같다.
- 모델 (e)와 (f)는 이전 synthesis layer의 출력 그리고 content feature를 concat한 것을 입력으로 취한다. 이는 앞서 설명한 식 (4)와 같다.
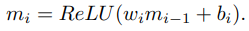
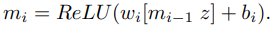
모델 (a)와 (c) 혹은 (b)와 (d)를 비교하면, content feature를 concat하는것이 SISR 성능 향상에 도움이 되는것을 볼 수 있다. 이러한 성능 향상은 modulation network에서 추가적인 파라미터가 있기 때문이다. 그럼에도 불구하고, 모델 (c)와 (e) 혹은 (d)와 (f)를 비교하면, 단순히 modulation layer의 출력 대신에 synthesis layer의 출력을 사용함으로써 추가적인 연산량의 증가 없이 PSNR과 SSIM 성능을 향상 시킬수 있다. 또한, LR-PSNR에 의해 측정된 LR 입력에 대한 SR 이미지의 일관성이 larger scale factor에 대해 모델 (e)와 (f)에 비해 (c)와 (d)가 더 낫다는 것에 주목한다.
Positional Features
다음, feature unfolding 연산이라고 소개된 방법과 positional feature를 연결하는 방법을 모색한다. Decoder의 앞에 sine activation을 사용한 dense layer를 추가한다(식 (2)를 수행하기 전). 아래 식은 positional과 content feature를 변형하기 위해 사용된다.
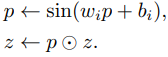
직관적으로, 이 layer가 해당 이웃의 각 LR pixel에 대한 가중치를 결정하기를 원하며, 이는 학습 가능한 distance weighting function으로 볼 수 있다. 표 5에서 보여지듯이, 모델에 추가적인 parameter로 더 많은 flexibility을 허용했음에도 불구하고 세가지 변형 (modulation input)에 걸친 개선을 관찰하지 못한다.
Conclusion
- SISR을 위한 implicit 표현을 학습하는 dual interactive implicit network, DIINN을 제안
- 제안한 DIINN은 해당 scale factor를 훈련하지 않아도 임의의 scale factor를 출력 가능
- DIINN이 SotA 성능을 달성
paper
'딥러닝 논문 리뷰' 카테고리의 다른 글
| NestedFormer Review (0) | 2024.04.03 |
|---|---|
| ConvNeXt : A ConvNet for the 2020s (0) | 2024.01.16 |
| Local Implicit Image Function (LIIF) Review (2) | 2023.10.30 |
| A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution Review (0) | 2023.09.02 |
| Spatial-Frequency Mutual Learning for Face Super-Resolution Review (0) | 2023.07.31 |



