
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- deep learning
- implicit representation
- Zero-Shot sr
- Referense Super Resoltuion
- Reference-based SR
- GNN in image
- CrossNet
- graph neural network
- ConvNeXt
- SISR
- GNN
- Feature reuse
- Cell-tissue
- Cityscapes
- TAAM
- LIIF
- Cell detection
- FRFSR
- Super-Resolution
- DIINN
- INR
- arbitrary scale
- session-based recommendation
- Tissue segmentation
- TRANSFORMER
- SegFormer
- hypergraph
- Graph
- ADE20K
- Reference Super-Resolution
- Today
- Total
딥러닝 분석가 가리
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution Review 본문
A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution Review
AI가리 2023. 9. 2. 22:06"A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution "
Abstract
Reference-based SR (RefSR)은 고해상도의 이미지를 사용해 저해상도의 영상을 SR 하는 방법으로 single image SR (SISR)의 한계점을 극복했다. 이전 RefSR의 연구는 두가지의 관점에 집중했다. 첫번째는 LR과 Ref 간의 정확한 matching을 하는것이고, 두번째는 Ref 이미지로 부터 유사한 texture와 정보를 효율적으로 전송 및 통합하는 것이다. 그럼에도 불구하고, perceptual loss와 adversial loss는 과소평가 되었다. Perceptual loss와 adversial loss는 texture를 전송하고 재구성하는데 효과가 있다. 그래서, perceptual loss와 adversial loss의 부정적 영향을 재사용하는, 다른 단계를 통해 texture를 재구성하는 과정을 단계적으로 가이드하는 feature resuse framework를 제안한다. Feature reuse framework는 어떠한 RefSR 모델에도 사용할 수 있고, 몇몇의 RefSR 방법에 제안하는 framework로 다시 훈련하여 성능을 높일 수 있다. 게다가, single 이미지 feature 임베딩 모듈과 texture-adaptive aggregation 모듈을 도입한다. Single image feature 임베딩 모듈은 입력된 LR이 스스로 재구성되도록 도와주고 엉뚱한 texture가 포함되도록 하는것을 억제시켜준다. Texture-adaptive aggregation 모듈은 dynamic filter를 사용해 LR 과 Ref간의 texture 정보를 인식하고 집계한다. 이것은 reference misuse을 줄이면서 reference texture의 활용도를 향상 시킨다.
Introduction
SISR의 접근법은 두가지로 나눌 수 있다.
- MSE와 MAE를 사용한 pixel-level error 최적화
- Perceptual loss와 adversarial loss를 활용한 visual 인식 기반 에러 최적화
Perceptual loss와 adversarial loss를 활용하는 결과가 시각적으로 더 낫지만 artifact가 생기며 비현실적인 texture를 생성하기도 한다. 이는 SISR에서 ill-posed 문제로 야기되었지만 RefSR은 고해상도의 reference 이미지를 활용함으로써 이를 완화했다. Ref영상을 얻는 방법은 web search나 video frame등 다양한 방법이 있다.
RefSR에는 성능을 저하시키는 두 가지 주요 제한 사항이 있다.
- 첫번째는 LR과 Ref사이의 대응점을 정확하게 찾는것, 하지만 다른 해상도와 texture 분포에서 정확하게 매칭하는것은 어렵다.
- 두번째는 texture feature를 효율적으로 전송하는것
비록 deformable convolution이 LR과 Ref feature map간 명시적인 정렬하는것을 학습할수 있어도, 먼 거리의 feature를 정렬하는것은 여전히 어렵다. 게다가 RefSR 방법은 자신의 texture를 재구성하는것 보다 texture를 효율적으로 집계하는것을 우선시 한다. Feature aggregation 과정 또한 중요한데, ResBlock은 모든 pixel feature를 동등하게 다뤄, Ref 이미지로 부터 불필요한 texture를 가져와 결과를 만든다. DATSR은 ResBlock을 Swin-Transformer로 바꾸었지만, window self-attention 연산은 파라미터와 런타임을 증가 시킨다는 문제점이 있다.
이러한 문제점을 해결하기 위해,
- 먼저 deformable convolution을 수정하지 않고 reference 이미지를 섞는다. 이를 통해 유사한 feature 사이의 거리를 간접적으로 증가시키고, 훈련 난이도를 높이며 성능을 향상 시킨다.
- 두번째, TADE에 영감을 받아, single-image feature 임베딩을 사용해 LR이 불필요한 feature를 완화하는 동안 그들의 feature를 활용해 스스로 재구성 되도록 도와준다.
- 마지막으로, 새로운 feature aggregation 모듈인 , Dynamic ResBlock (DRB)를 제시한다. DRB는 decoupled filter를 residual block에 추가한것이다. 이는, 공간과 channel 영역에서 texture 정보를 알 수 있고, 관련있는 texture를 adaptive하게 aggregate 하며, 노이즈나, 잘못된 texture같은 불필요한 정보를 줄이고 관련있는 texture 정보를 개선하기 위해 효율적인 enhanced spatial attention mechanism (ESA)를 사용한다.
게다가 대부분의 이전 work들은 중요한 사실인 : perceptual loss와 adversarial loss의 증가는 texture 전송과 재구성에 악영향을 끼친다. Reconsturction loss 훈련 모델의 texture 전송과 재구성 능력을 최대한 활용하기 위해 feature reuse framework을 제안한다. 이는 loss_rec + loss_per + loss_adv을 사용하는 훈련과 평가 과정에서 loss_rec으로만 훈련된 feature를 feed back하는 feature aggregation 모듈이다. 이러한 조작은 perceptual loss가 texture 전달 및 재구성에 미치는 영향을 효과적으로 감소시킨다. 이 논문의 기여한점을 요약하면 아래와 같다.
- Feature reuse framework를 소개한다. 이는, perceptual loss와 adversarial loss로 부터 texture 재구성 저하를 상당히 줄인다. 이러한 framework은 다양한 RefSR에 적용할 수 있다.
- LR의 self-texture 재구성을 개선시키고 texture 관계를 유지하기 위해, single-image feature reconstruction 모듈을 사용한다. 이 모듈에서 feature upsampling과 최종 이미지 재구성 과정은 제외하고, LR 자체의 재구성 feature를 aggregation 하는데에만 집중한다.
- DRB를 설계하고 texture adaptive 모듈로 도입한다. 이 block은 dynamic filter를 적용하고 선택적 인지와 Ref 이미지로 부터 texture를 전송하기 위해 spatial attention을 개선시킨다.
Proposed Method
Feature Reuse Reconstruction Framework
Feature reuse는 deep network에서 vanishing gradient 문제를 예방하여 이전 layer의 feature를 후속 layer에 입력하여 네트워크의 학습과 파라미터 효용성을 개선시킨다. 이전 연구에서 SR시 loss_rec만을 사용하는것이 perceptual loss나 adversarial loss를 사용하는것 보다 더 많은 상세한 texture를 제공하는것을 보여줬다. 이러한 문제를 극복하기 위해, reconstruction loss 만을 사용해 SR feature map을 생성하는 사전학습된 모델을 사용하는것을 제안하고, 모든 loss를 사용하는 두번째 모델에 통합한다. 이는 그림 1과 같다. 그러므로, feature reuse를 두 모델의 훈련 과정으로 확장한다. 요약하자면 먼저 LR 이미지와 Ref 이미지를 입력으로 얻어 loss_rec로 훈련된 SR feature를 얻는다. 이 과정은 오직 loss_rec로만 훈련되어진다.

이 단계에서 texture를 전송하고 재구성하는 능력이 강렬한 RefSR 네트워크를 얻는다. 하지만, 고화질의 이미지를 생산하기위해, perceptual loss와 adversarial loss의 사용이 요구된다. 두번째 네트워크의 texture 전송과 재구성 능력을 향상시키기 위해, 첫번째 네트워크에서 SR_rec feature를 생성하고 두번째 네트워크 훈련에 feature map을 되돌려 보내는 형식으로 통합한다. 이 과정은, 첫번째 모델은 오직 추론만 하며 가중치 업데이트는 하지 않는다. 앞의 식 (1)을 다음과 같이 나타낼 수 있다.

이러한 framework 사용은, 동일한 texture 전송과 재구성 성능을 가진 두개의 모델을 얻을 수 있다. 이러한 framework은 다른 RefSR work에서도 성능을 개선시킬 수 있다. Ablation 연구에서 이 work을 MASA와 C^2-matching에 사용하여 성능을 입증한다.
Correlation-based Texture Warp
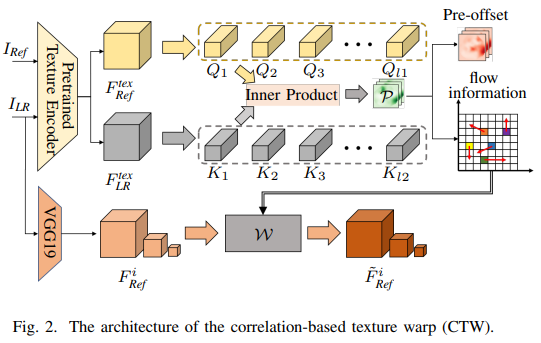
RefSR task에서 가장 중요한 부분은 LR과 Ref 이미지 간의 정확한 매칭을 하는것이다. 이것은 순차적인 texture 전송에 있어 중요하다. Correlation Texture Warp (CTW)구조는 그림 2와 같다. 먼저 LR 영상을 Ref 영상과 같은 크기로 보장하기 위해 zero-padding을 사용한다. 다음, 파라미터를 공유하는 texture 인코더로 LR과 Ref 의 feature를 추출하고 feature map을 생성한다. Texture 인코더는 일관성을 유지한다. 왜냐하면 이는 지식증류나 연관학습 방법의 훈련의 문제인 LR과 Ref 이미지 간의 다른 해상도 때문에 부정확한 매칭을 완하시켜 매칭을 좀 더 robust 하고 개선시키기 때문이다. Texture feature는 unfold 되어서 LR은 l1 개의 patch (Q), Ref는 l2개의 patch (K)를 얻는다. Q와 각 패치 K간의 cosine 유사도는 inner product 로 계산된다.
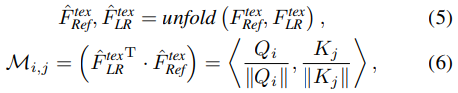
패치 Q가 주어졌을때 패치 K와 가장 유사한 패치를 찾을 수 있으며 이를 P라고 한다. Index matrix P는 다음 식 (4)와 같이 정의되며 이중 유사한 패치는 식 (5)와 같이 정의할 수 있다.
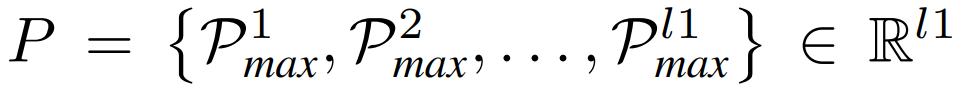
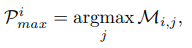
M은 패치 Q에 해당되는 패치 K의 confidence score를 나타낸다. Optical flow를 사용해 reference feature를 초기에 warp하려면 index 행렬 P를 flow 정보로 변환해야 한다. 이는 다음 식 (6)과 같다.
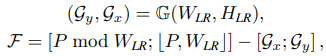
[ ; ]은 두 벡터간 concatenation을 나타내며, G(·)는 LR의 크기인 grid를 생성해주는 grid 함수이다. Gx와 Gy는 grid의 높이와 넓이 좌표값이고, mod와 [ , ]은 module과 floor division인 수학 연사자 이다. F 는 flow 정보이다. 마지막으로, VGG19로 부터 추출된 3개의 다른 크기의 feature map을 선택한다. VGG19를 선택한 이유는 feature 추출 능력이 강력하며 추가적인 feature 추출 모듈을 학습할 필요가 없기 때문이다. Ref feature의 해당되는 3개의 크기는 각 다른 크기의 flow 정보를 사용해 optical flow로 warp 된다.
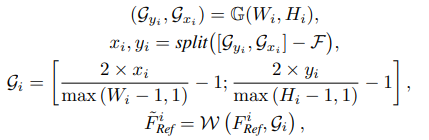
Multi-scale Dynamic Texture Aggregation
RefSR의 다른 중요한 목표는 대응 매칭 관계에 기반한 효율적인 texture 전송을 사용하는것이다. Reference 이미지 texture의 더 효율적인 전송과 통합을 위해 그림 1의 회색 부분과 같이 U-Net에 기반한 multi-scale dynamic texture transfer 모듈을 제안한다. U-Net의 multi-scale의 특징을 사용해, multi-scale reference 이미지의 texture feature를 점진적으로 집계할 수 있으며 더 rich한 texture를 생성하는것을 배울수 있다. 직접적으로 texture를 전송하는 SRNTT랑 TTSR과 달리, RefSR에서 LR과 Ref 간의 texutere 정렬을 위해 특별한 deformable convolution을 사용하고 마지막으로 texture 전송과 aggregation을 완벽하게 하기 위해 texture-adaptive aggregation 모듈을 사용한다. Texture 전송의 주요 task는, RefSR이 종종 LR 에서 나오는 고주파의 디테일을 재구성하기 위해 struggle 한다. 이를 해결하기 위해, LR 자신의 feature를 재구성하는데 SISR 방법을 사용하고, 재구성된 feature를 feature aggregation process에 사용한다. 이것으로, RefSR에서 재구성하기 어려운 detailed texture를 보조할 뿐만 아니라 불균형한 texture의 도입을 어느정도 제한한다.
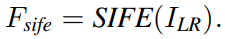
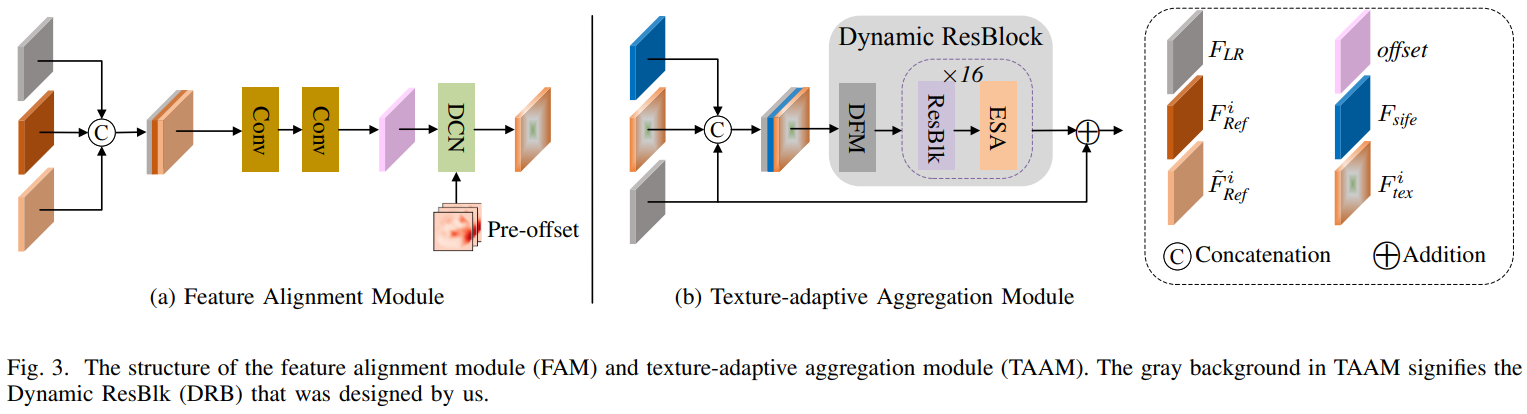
Texture Alignment Module
Multi-scale reference feature에서 더 정확하게 texture feature을 전송하기 위해, texture alignmnet를 정확하게 하는 RefSR을 위해 설계된 특별한 deformable convolution을 사용한다. 그림 3 (a)의 flowchart와 같이, deformable covolution을 위한 offset을 얻기 위해, LR feature와 Ref feature 두개를 concat하여 offset 을 얻는다. 이는 deformable convolution을 학습하는데 광학적으로 왜곡된 reference feature를 사용하는것이 학습 과정에 있어 더 안정적이기 때문이다.
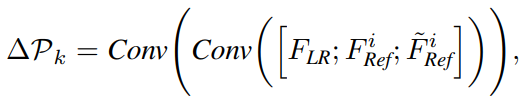
P_LR과 P_Ref 간의 공간적 차이인 ∆P를 사용하며 이는 ∆P = P_LR − P_Ref로 나타낼수 있다. ∆P는 CTW의 출력인 pre-offset 이다. 마지막으로, 개선된 deformable convolution은 P_LR을 통합하는데 사용되고, 이는 전반적인 texture이다.
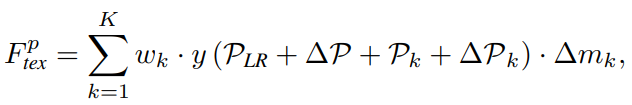
y는 original reference feature, P_k ∈ {(-1, 1), (-1, 0), ..., (1, 1)}, ∆P_k는 학습 가능한 offset, w_k는 convolution weight, ∆m_k는 modulation scalar, 출력은 position 에 alignment 된 reference feature이다. Deformable convolution에 기반한 texture alignment를 통해 각 해당되는 reference feature의 가장 유사한 patch들의 주변 texture들이 통합되어질 수 있고, 각 패치의 contextual information을 완전히 사용할 수 있어, 후손 texture 전송의 보장을 제공한다.
Texture-Adaptive Aggregation Module (TAAM)
LR, LR_sr, tex feature들을 효율적으로 통합하기 위해 TAAM을 제안한다. TAAM은 그림 3(b)에 나오는것 처럼 self-adapting 전송과 관련있는 texture feature를 통합한다. 특히, 정렬된 texture feature를 LR과 LR_sr feature과 concat하고, convolutional layer에 입력한다. 이후, 출력 F_agg를 얻기 위해 reference feature 안에 있는 관련있는 texture를 전송하고 통합하기 위해 dynamic residual block을 사용한다. 가장 작은 크기에 해당하는 TAAM 모듈에 LR_sr 만 내장하고, 즉, 가장 작은 크기의 feature matching만을 사용한다는점에 유의해야 한다. 다른 TAAM은 LR, tex feature만 통합 한다.
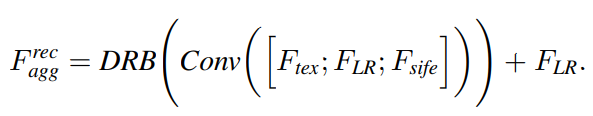
두번째 모델에서는 첫번째 모델에서 만들어진 feature map을 재사용한다. 결과적으로, 이 feature map을 feature aggregation 과정에 더해 texture feature를 개선시킨다. 식 (11)을 두번째 모델에서는 다음과 같이 나타낼 수 있다.
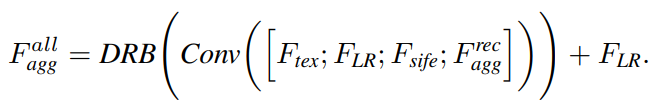
Dynamic ResBlock (DRB)
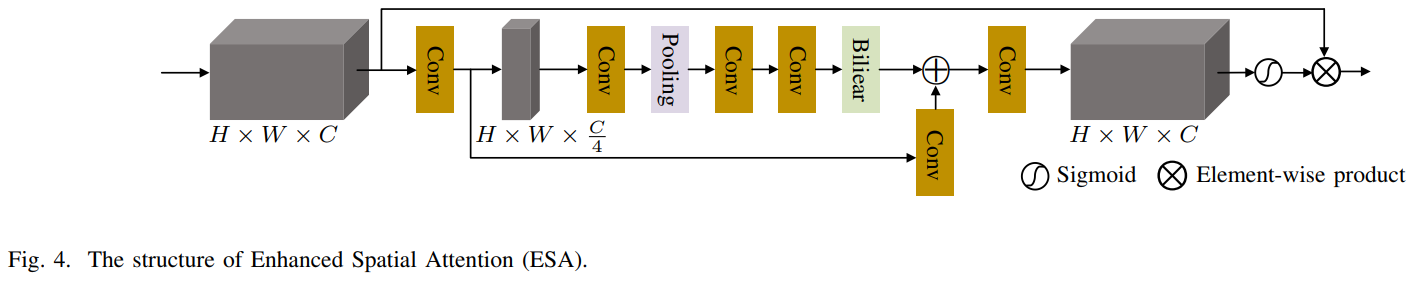
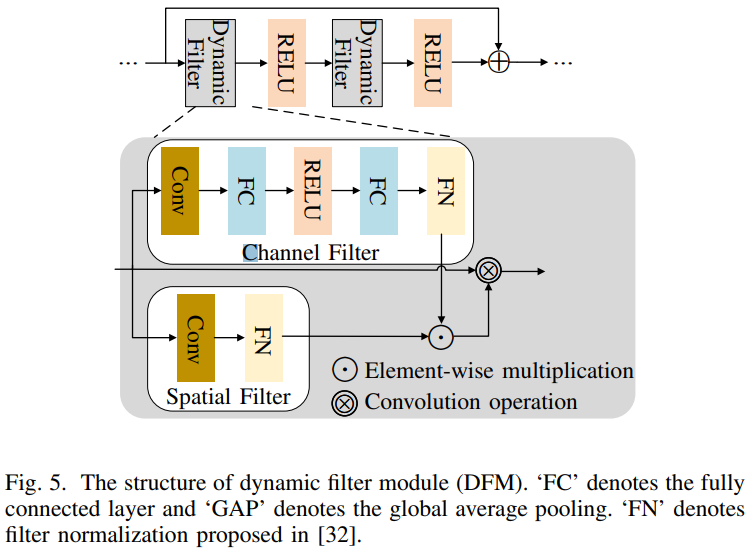
DRB 모듈은 두개의 decoupled dynamic filter와 ResBlock 그리고 Enhanced Spatial Attention (ESA)로 구성된다. Decoupled dynamic filter와 ESA는 그림 5와 4에 나타난다. Decoupled dynamic filter는 F_LR과 F_tex, F_sife 간의 관련있는 texture을 효율적으로 인식할 수 있는 channel filter와 spatial filter로 나눠져있다. Decoupled dynamic filter 연산은 다음과 같다.
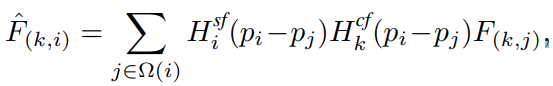
Ω(i)는 i번째 pixel 주변의 convolution window를 나타내고, p_i와 p_j는 pixel 좌표이다. H는 앞에서 부터 spatial filter, channel filter를 의미하고 dynamic filtering 전 후 에 대한 k 번째 channel과 j 번째 pixel의 feature value는 F(k, j)과 출력으로 나타낸다. Routing weight와 최종 aggregated feature는 다음과 같이 생성된다.
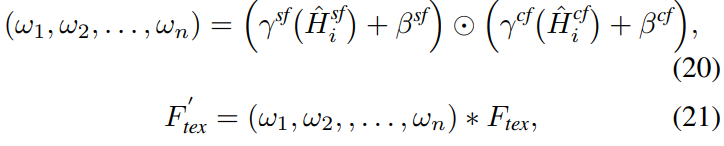
H는 각 spatial과 channel filter branch에서 얻어진 value를 나타내고, 뒤에 normalization이 적용된다. w는 routing weight를 의미한다.
ESA 는 이전 work에서 효과적이고 효율적인 것으로 증명되었다. 이는 channel 크기와 spatial 크기를 각각 압축하는 stride가 2인 1x1 convolution과 3x3 convolution을 사용해서 이며, max pooling을 사용해 feature 크기를 줄여서 이다. ESA 과정은 다음과 같이 정의 된다.
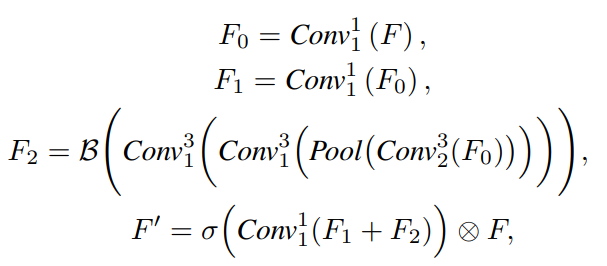
ESA의 ResBlock은 LR feature의 관련있는 texture feature를 개선시킬 수 있고 낮은 연관성의 feature를 억압하며 높은 연관성의 reference feature를 통합할 수 있다. 이 attention module은 lightweight 하며 오직 적은 수의 parameter만 더해진다. 이 attention 기반의 texture-adaptive aggregation 방법은 reference로 부터 효과적인 texture를 전달 및 융합하고 관련없는 texture로 부터 간섭을 줄일 뿐만 아니라, SISR 방법에 의해 재구성된 feature가 LR feature에도 잘 통합되도록 보장한다. F_sife featiure를 집합 시킴으로써, RefSR이 자체 texture를 재구성하기 어렵다는 단접을 보완할 뿐만 아니라, 상당 부분 무관한 texture의 생성을 억제한다.
Loss Function
Reconstruction Loss
모델이 훌륭한 texture transfer 능력과 이미지 reconstruction 능력을 보장하기 위해 reconstruction loss를 사용한다.
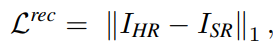
Perceptual Loss
Perceptual loss는 feature 영역에서 계산되는 것으로, 이미지를 GT에 더 유사하게 만들어 준다.
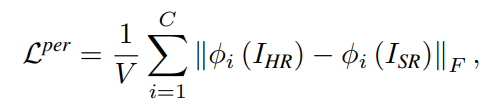
Adversarial Loss
생성자 G와 판별자 D는 서로를 상호보완하며 개선되고 모델은 시각적으로 안정된 이미지를 출력할 수 있다.

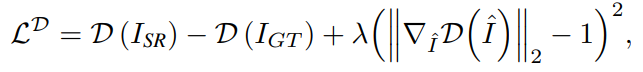
최종 loss는 다음과 같으며 λ는 각 loss별 매개변수 이다.
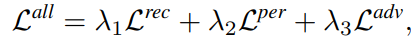
Experiments
Dataset and Metrics
- Training Dataset : CUFED 11871 pairs and 160×160 resolution
- Testing Dataset : CUFED5, Urban100, Manga109, Sun80, MR-SR
- Metrics : PSNR, SSIM in YCbCR color space (Y channel)
- Implementaiotn Details
- LR 영상을 만들기 위해 HR 영상의 해상도를 4배 낮춤
- Data augmentation으로는 수평, 수직 뒤집기, 랜덤 rotation 진행
- Long-distance feature 정렬에 대한 성능 향상과 훈련 강도를 높이기 위해 reference 이미지 패치를 랜덤하게 섞음
- SISR feature 임베딩 모듈을 위한 사전 훈련된 모델인 ESRGAN의 RRDB 파라미터를 사용
- Optimizer Adam, learning rate 1e-4, batch size 9, loss weight는 각 1.0, 1e-4, 1e-6으로 설정
Comparison with State-of-the-art Methods
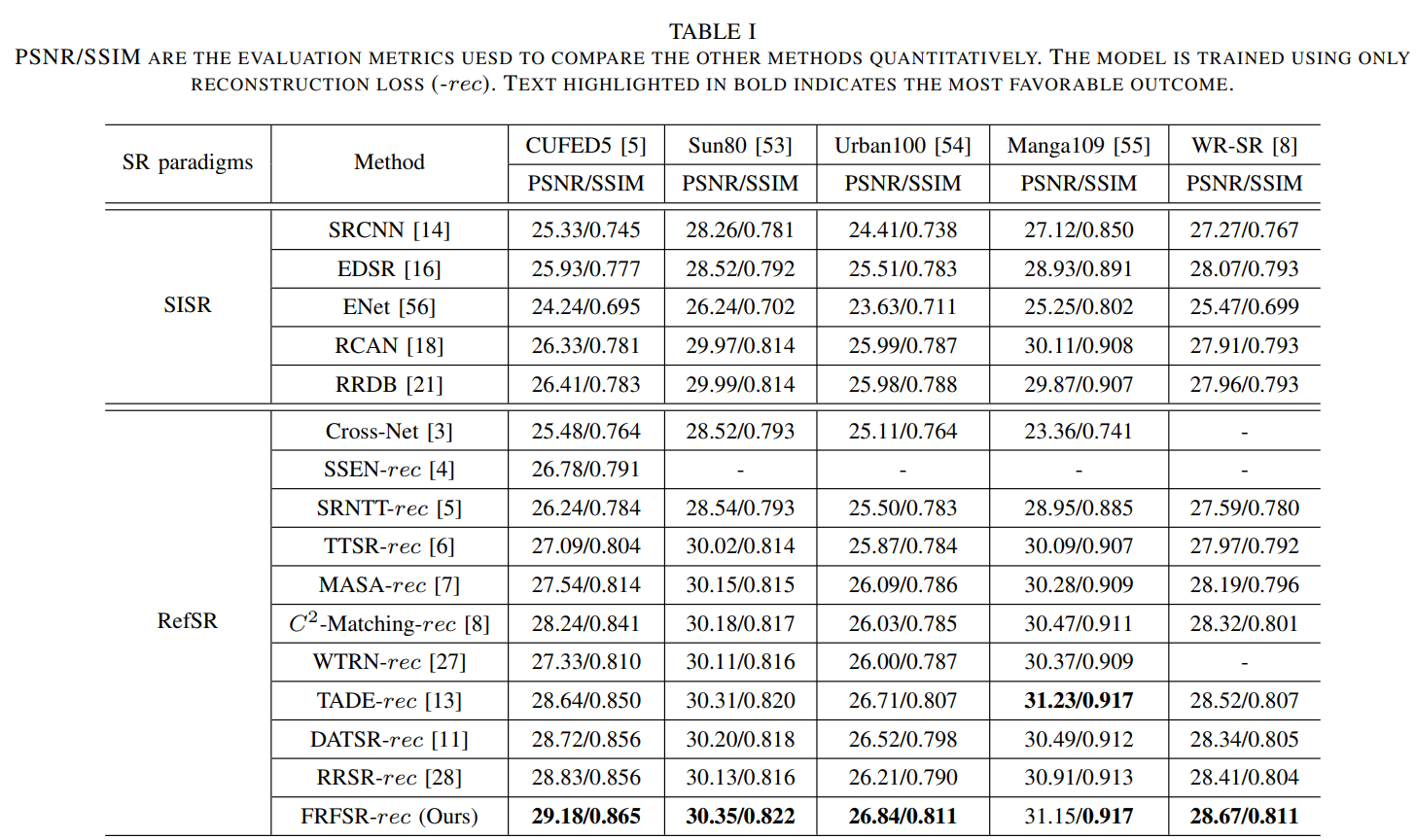
Quantitative Comparison
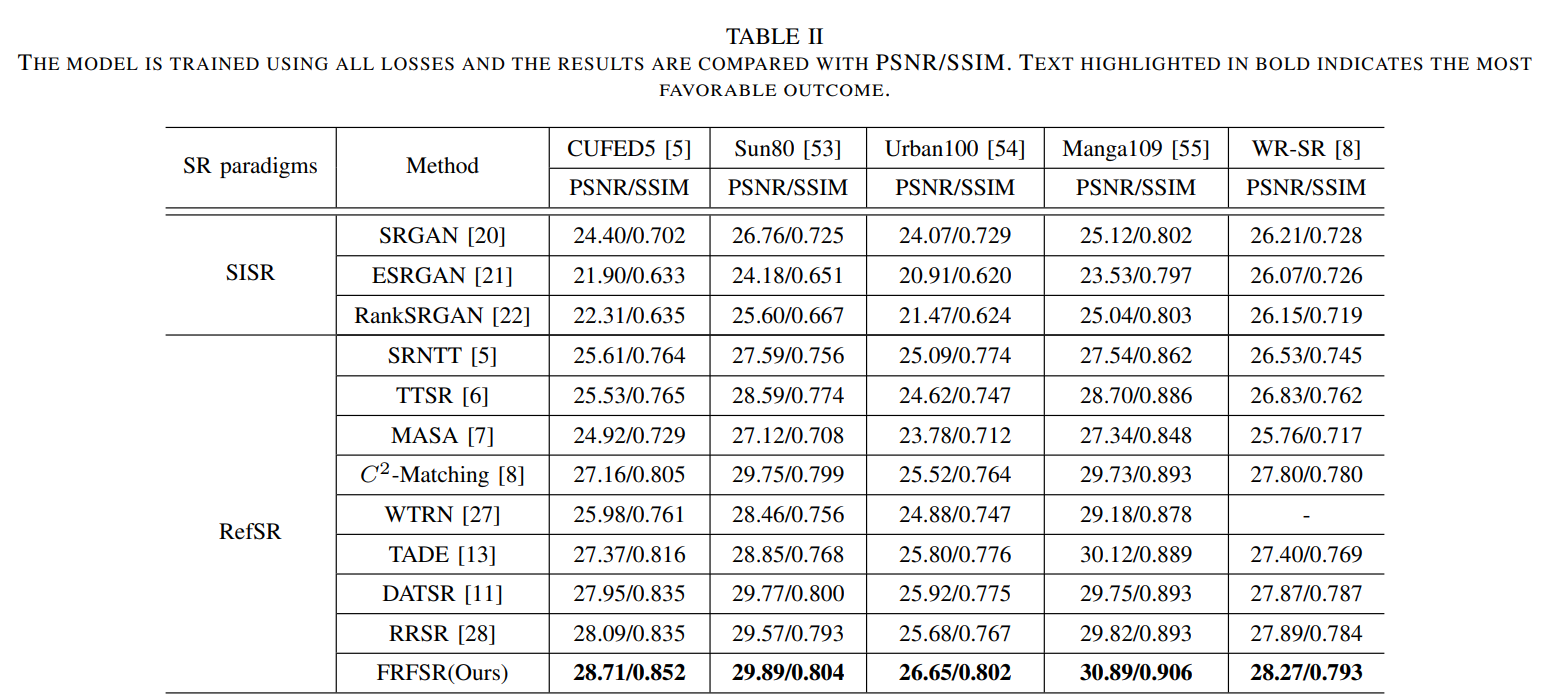
표 1에 reconstruction loss만을 사용하여 다른 SotA 모델과 비교한 결과를 나타냈다. 제안하는 방법은 재구성 과정에서 효과적인 texture matching, dynamic texture 전송 그리고 완벽한 SISR feature를 격려한다. 이것으로 고해상도의 reference 이미지를 LR 이미지로 전송하고, 고주파의 정보를 개선시키고 self-feature를 전송하여 LR이 스스로 재구성하는데 도움을 준다. 표 2에 보여지는것과 같이 제안하는 모델이 loss_rec만 사용했을때 보다 성능이 떨어졌을지라도, 다른 모델에 비해 높은 성능을 달성했다.
Qualitative Evaluation
그림 6은 loss_rec만을 사용해 다른 SISR과 RefSR 모델들과 비교한 그림이다. RCAN 보다 선명하며 RRDB가 특히, 얼굴 및 미세한 texture에 대해 고주파 정보의 심각한 저하로 인해 texture 정보를 재구성하는데 어려움이 있다. RefSR과 비교했을때, FRFSR의 적응적 틍성은 Ref 이미지로 부터 texture 정보를 인식하고 전달할 수 있게 한다. 그래서 모델은 LR이 놓친 고주파 정보를 수용할 수 있어, 이미지를 GT와 더 가깝게 재구성할 수 있다. 제안하는 모델이 다른 RefSR 모델에 비해 더 detail 한 texture를 많이 가지고 있다. 이것으로 제안하는 모델이 효율적인것을 증명한다. Feature를 재사용하는 FRFSR은 더 현실적인 texture 정보를 효과적으로 보존할 수 있다.

Comparison of Robustness of Texture Transformation
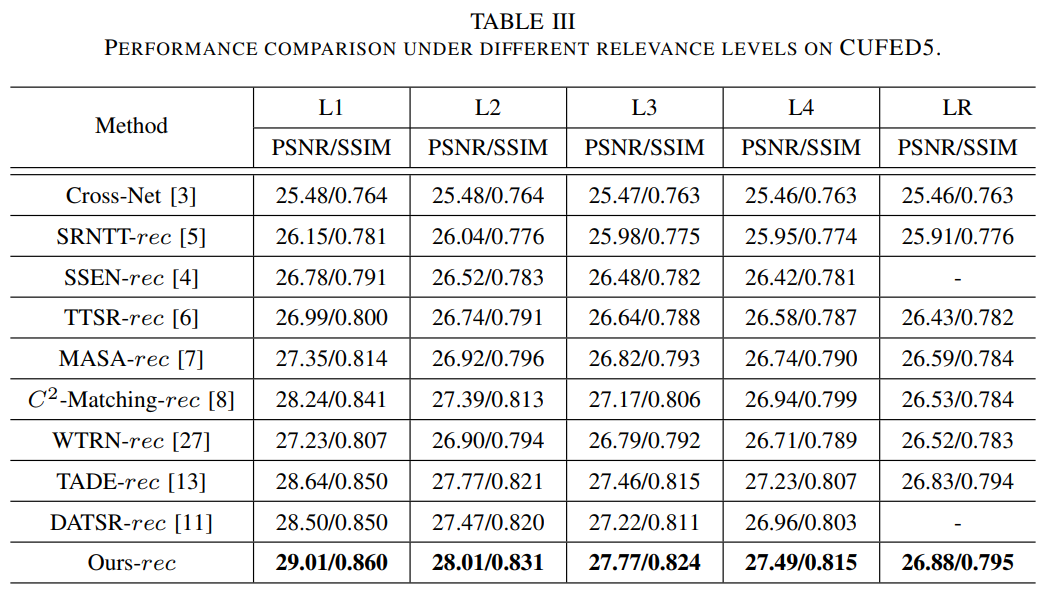
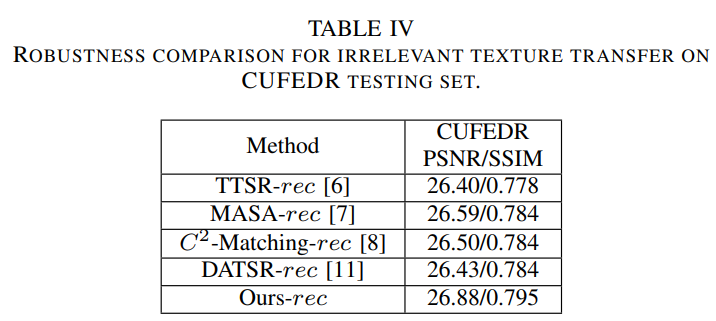
Texture transfer robustness는 RefSR 모델에서 중요한 평가이다. 그림 7은 SotA 모델이 texture를 잘못 전송한 그림이다. 게다가, 비록 Ref 이미지의 texture가 불균형적이더라도, 모델은 texture transfer robustness 해야한다. 표 3은 다른 모델들의 다른 reference 단계에 대한 결과를 나타낸다. 이때, LR은 LR 이미지가 reference 이미지로 사용된것을 의미한다. 이 결과로 FRFSR이 다른 모델에 비해 texture transfer and robustness함을 보여준다. CUFED에서 임의로 HR 1개를 reference 이미지로 선정해 실험한 결과는 표 4와 같다. 참조 이미지가 무관하더라도 그림 8과 같이 다른 모델에 비해 높은 성능을 보인다. 이러한 실험 결과는 제안하는 모델이 관련있는 reference 이미지에서 유사한 texture를 일치시키고 전송할 수 있으며, 또한 관련성이 낮은 시나리오에서 adaptive texture transfer robustness도 갖추고 있음을 나타낸다.


Comparison of Robustness of Long-range Alignment
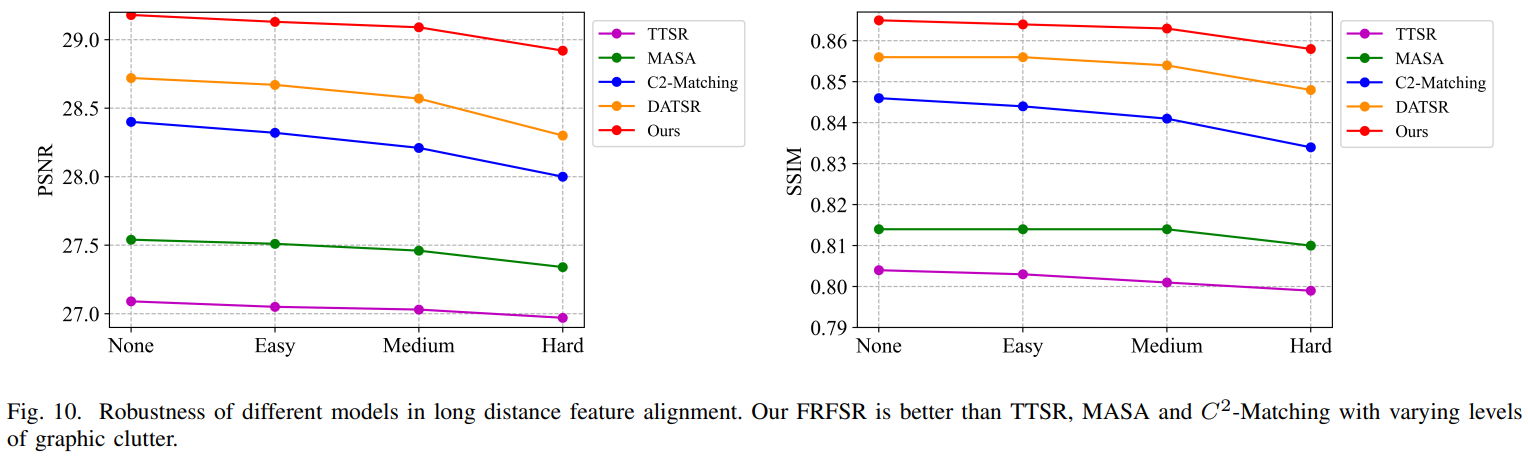
Long-distance feature 정렬과 관련해 모델의 robustness를 개선시키기 위해 long-distance alignment와 context perturbation 샘플과 함께 훈련을 통합했다. 특히 reference 이미지를 n×n 패치로 나누고, 위치를 랜덤하게 섞고 최종적으로 새로운 샘플 이미지로 한다. 이는 이미지 context의 종속성을 방해하고 관련 패치 간의 misalignment 거리를 확대한다. Suffling 패치 수준을 2×2, 4×4, 8×8로 하여 진행한다. 이는 그림 10과 11에 나타낸다. 학습 시에는 4×4 data augmentation 만을 사용했다.

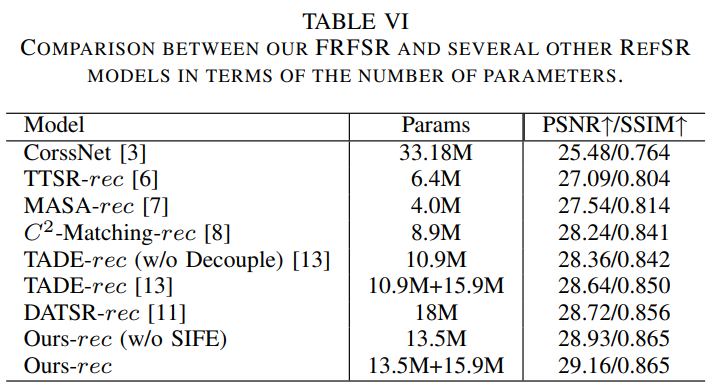
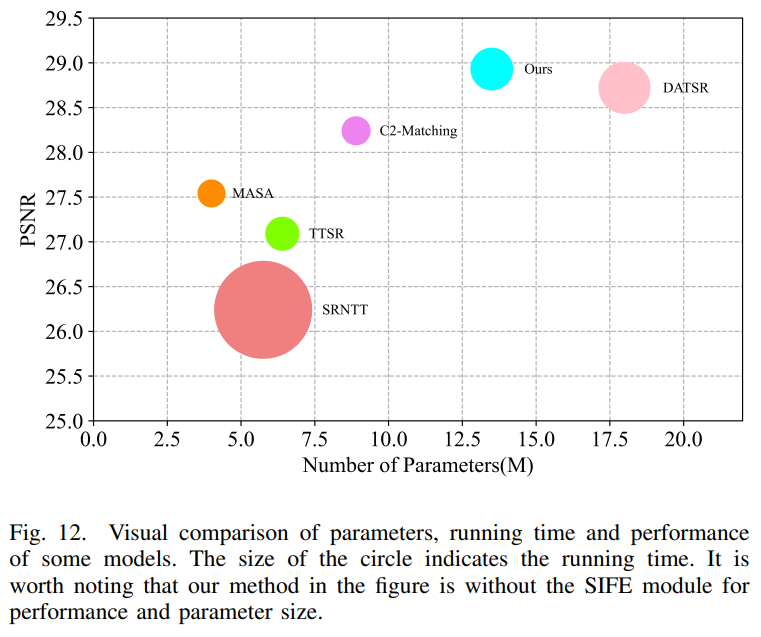
Discussion of Model Size and Computation Cost
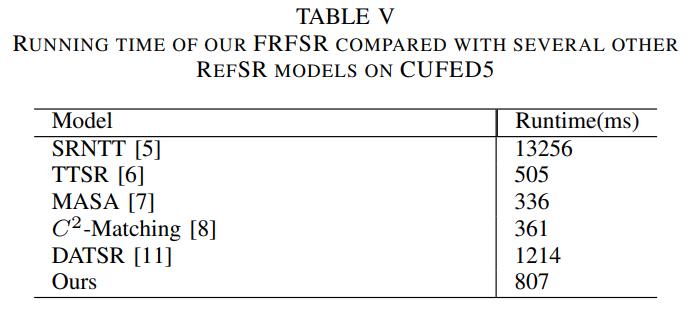
다른 모델들과 비교한 결과를 표 5, 6 그리고 그림 12에 나타냈다.
Ablation Studies
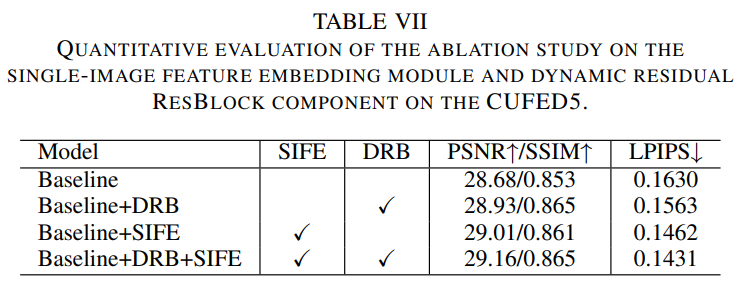
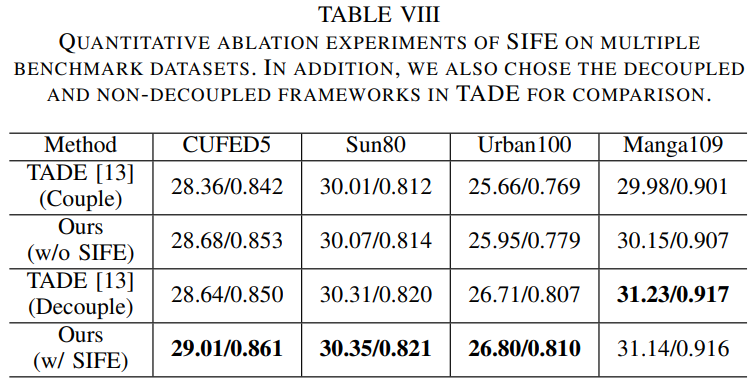
이 절에서는 SIFE와 DRB의 성능을 시험한다. 결과는 표 7과 같으며, 또한 feature reuse framework을 다른 RefSR에 적용해 효율적인것을 증명한다.
Single Image Feature Embedding
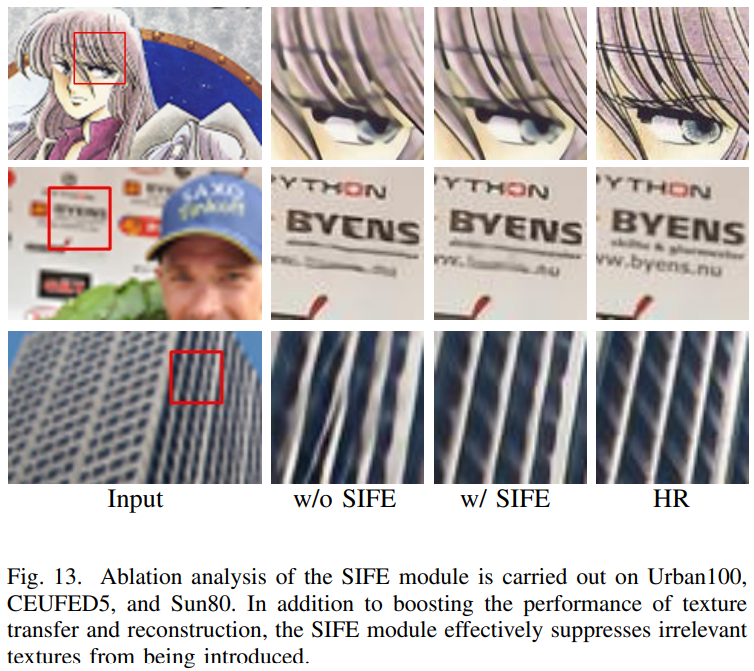
SISR로 부터 재구성된 feature는 Ref 이미지 texture feature보다 더 효율적으로 사용될 수 있다. 이를 검증하기 위해, texture를 전송할때 feature 임베딩을 고려하지 않고 Ref 이미지에서 일치하는 texture를 전송하는 성능과 Ref 이미지에는 없는 유사한 texture를 재구성하는 성능이 모두 영향 받는다는것을 찾았다. 표 8은 SIFE 모듈의 유뮤에 따른 성능 결과이다. 그림 13은 SIFE 모듈을 추가하면 모델의 학습을 용이하게하고, 세부 손실을 완화 하며 CUFED5의 Ref 이미지에서 더 풍부하고 미세한 texture 세부 정보를 전송할 수 있을 뿐만 아니라 다른 텍스처와 같이 다른 데이터셋에서 재구성된 SR 이미지에서 texture feature를 더 두드러지게 만들 수 있다. SIFE 모듈을 추가하면 그림 13의 세번째 행과 같이 무관한 texture 전송을 어느 정도 억제할 수 있다. SIFE 모듈은 정량적, 정성적 평가를 통해 Ref 이미지에서 존재하지 않는 texture 세부사항을 복원하고, 모델의 texture 전달 능력을 향상시킨다.
Dynamic Residual Block
Aligned reference feature는 많은 노이즈를 포함해서 바로 ResBlock을 reference feature는 SR 이미지에 불균형한 texture와 노이즈를 발생시킨다. 그래서 residual block에 dynamic filter와 ESA를 사용해 관련 있는 texture를 효율적으로 인지하고 그들을 통합한다. 이에 대한 결과는 표 7과 그림 14와 같다. ESA를 추가한 후 관련성이 높은 texture feature가 더욱 두드러지고, texture edge가 더욱 sharp 해지는것을 볼 수 있다. 또한 그림 16에서 세번째 행은 DRB 모듈을 추가하는것이 효과적으로 무관한 texture의 도입을 줄이고 texture를 전달하고 재구성하는 모델의 능력을 향상시킬수 있음을 보여준다. 또한 네번째 행에서는 DRB 모듈에 의해 재구성된 texture가 GT에 더 가깝다는것을 보여준다.


Feature Reuse Framework
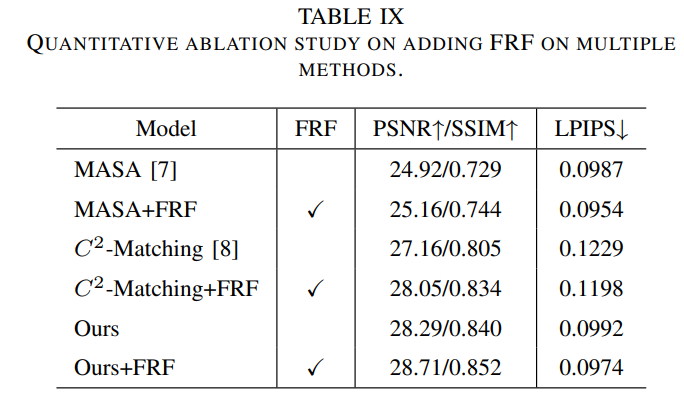
Loss_rec로 훈련된 모델과 비교하여, 모든 loss로 훈련된 모델이 texture 전송 및 재구성에 더 나쁜 성능을 나타내는것을 발견했다. Adversarial loss와 perceptual loss의 영향을 줄이기 위해, FRF를 사용한다. 표 9는 MASA와 C^2-Matching의 FRF 사용 성능을 보여준다. 이는 FRF가 더해진 후 성능이 향상되는것을 볼 수 있다. 또한 FRF를 더한 정성적 결과는 그림 17과 같다. FRF를 더한 후 texture를 더 정상적으로 복원한다. 이것은 이 framework가 adversarial loss와 perceptual loss가 texture 재구성 저하에 미치는 영향을 줄일 수 있음을 나타낸다.

Conclusion
- Texture 재구성 과정에서 발생하는 perceptual loss와 adversarial loss의 부정적 영향을 완화하는 feature reuse framework를 제안
- LR 입력 영상의 자체 기능을 재구성 하기 위한 SIFE 모듈과 percetptual aggregate reference 이미지의 효과적인 texture를 재구성하는 TAAM으로 구성
- 이러한 접근 방법은 RefSR의 성능을 개선시켰으며 관련이 없는 reference의 견고성도 강화함
'딥러닝 논문 리뷰' 카테고리의 다른 글
| Single Image Super-Resolution via a Dual Interactive Implicit Neural Network Review (0) | 2023.11.03 |
|---|---|
| Local Implicit Image Function (LIIF) Review (2) | 2023.10.30 |
| Spatial-Frequency Mutual Learning for Face Super-Resolution Review (0) | 2023.07.31 |
| CrossNet Review (0) | 2023.07.21 |
| SegFormer Review (0) | 2023.07.03 |



