
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Zero-Shot sr
- Reference Super-Resolution
- Referense Super Resoltuion
- Reference-based SR
- Feature reuse
- ConvNeXt
- implicit representation
- FRFSR
- Super-Resolution
- GNN in image
- ADE20K
- arbitrary scale
- SISR
- INR
- Cell detection
- DIINN
- graph neural network
- deep learning
- GNN
- SegFormer
- Cityscapes
- hypergraph
- session-based recommendation
- TAAM
- Tissue segmentation
- TRANSFORMER
- Cell-tissue
- LIIF
- CrossNet
- Graph
- Today
- Total
딥러닝 분석가 가리
Spatial-Frequency Mutual Learning for Face Super-Resolution Review 본문
Spatial-Frequency Mutual Learning for Face Super-Resolution Review
AI가리 2023. 7. 31. 21:57"Spatial-Frequency Mutual Learning for Face Super-Resolution"
Abstract
Face super-resolution (FSR)은 LR 얼굴 영상을 HR 얼굴 영상으로 복원하는것이 목표이다. Deep learning으로 FSR은 상당한 성취를 얻었지만 기존의 FSR 방법은 고정된 receptive field를 가지고 있으며 또한 facial 구조를 유지하기 힘들다는 단점이 있어 FSR의 성능을 제한시키고 있다. 이러한 문제점을 해결하기 위해, Fourier transform을 도입한다. Fourier transform은 global facial 구조 정보를 capture할 수 있고 image-size의 receptive field를 달성할 수 있다. Fourier transform을 사용해, FSR을 위한 spatial-frequency mutual network (SFMNet)을 고안한다. SFMNet은 공간과 주파수 사이의 상관관계를 처음으로 explore한 FSR 방법이다. 좀 더 구체적으로 말하자면, SFMNet은 spatial branch와 frequency branch 두 branch로 구성된다. 앞서 말한 Fourier transform의 이점인, frequency branch는 image-size의 receptive field를 달성하고 spatial branch가 local dependcy를 추출하는 동안, global dependency를 capture할 수 있다. 이러한 dependencies가 상호 보완적이고 FSR에 유리하다는 점을 고려해, 보완적인 공간 정보와 주파수 정보를 상호 융합하여 모델의 기능을 향상시키는 frequency-spatial interaction block (FSIB)를 개발한다. 실험결과에서는 정성적, 정량적 모두 기존의 FSR 방법에 비해 더 높은 성능을 달성했다.
Introduction
FSR은 저해상도의 얼굴 영상을 고해상도의 얼굴 영상으로 복원하는것이다. Low-cost 카메라나 imaging condition의 제한 때문에 얻어진 얼굴 영상은 항상 저화질이므로 얼굴 인식, 얼굴 속성 분석 등 과 같은 작업을 악화시킬 수 있다. 그러므로 FSR은 새로운 과학적 도구가 되었고 computer vison이나 image processing 커뮤니티에서 주목받는 분야이다. FSR은 ill-posed 문제가 있다. FSR은 일반적인 SR과 다르게 오직 얼굴 영상만 사용하므로 중추적인 얼굴 구조를 복원해야 한다.
기존의 존재하는 FSR 방법이 성능을 향상 시켰지만 여전히 다루어야할 한계들이 있다. 얼굴 영상은 global 얼굴 구조를 가지고 있지만, CNN의 receptive field는 vanishing gradient 문제 때문에 제한이 있어 global dependcy를 실패한다. Large receptive field를 얻기 위해 transformer가 computer vision에 적용되었다. Self-attention은 모든 patch를 따라서 long-range dependency를 모델링 할 수 있지만, transformer는 훈련 데이터와 연산량에 있어 높은 수요를 요구한다. 게다가, partition 전략은 얼굴의 구조를 망가뜨릴 수 있다. 그러므로 FSR은 효율적인 방법을 위해 이미지 크기의 receptive field를 달성하고 얼굴의 구조를 유지할 수 있어야 한다. 이러한 것들을 위해서 frequency 정보를 도입한다. 잘 다듬어진 주파수 영역의 features는 영상 크기의 receptive field를 달성할 수 있고 global dependcy를 capture할 수 있으며 이는 공간영역에서 local facial feature를 잘 보완할 수 있다. 주파수 정보를 얻기위해 Fourier transform을 사용한다. Fourier transform은 영상을 얼굴 구조 정보의 특징을 가지고 있는 진폭과 위상으로 분해한다. 그림 1에 나타나듯이, 영상을 복원할 때 위상 정보를 사용하면 얼굴 구조를 좀 더 선명하게 복원할 수 있다.

이러한 분석을 통해 FSR을 위한 새로운 spatial-frequency mutual network (SFMNet)을 제안한다. SFMNet은 공간과 주파수 영역을 통합하여 explore한다. SFMNet은 주파수 branch와 공간 branch를 포함한 두가지 branch를 가진다. 주파수 branch는 spatial branch가 local facial feature를 추출하는동안 Fourier transform으로 global facial structure을 capture한다. 주파수 영역의 global 정보와 공간 영역의 local 정보는 상호보완적이고, 이 둘은 모델의 표현 능력을 개선할 수 있다. 이 점에 비추어 볼때, FSR 성능을 개선시키기 위해 상호간의 주파수와 공간 정보를 혼합하는 frequency-spatial interaction block (FSIB)을 설계한다. SFMNet에 공간과 주파수 영역 둘다 모델의 학습을 가이드 하기 위해 GAN 기반의 sptial 설명자와 frequency 설명자를 개발한다.
Contribution
- FSR을 위해 공간 정보와 주파수 정보 둘다 사용하는 spatial-frequency mutual netowrk를 개발
- Global 주파수 정보와 local 공간 정보를 상호 혼합하는 frequency-spatial interaciton block을 설계
- 정성적, 정량적 SotA 달성
Proposed Method
Revisiting Fourier Transform
Fourier transform은 신호처리에 있어 중요한 기술이다. Fourier transform은 단일 채널 영상 x 가 주어지면 다음 식 처럼 표현된다:

H와 W는 영상 x의 높이와 넓이, j는 imaginary unit, u와 v는 수평과 수직 좌표계 그리고 F는 Fourier transform을 의미한다. 식 (1)에서 F(x)에 있는 각 픽셀이 영상 x에 있는 모든 픽셀과 통합된다.
주파수 영역에서, x의 두가지 요소인 진폭과 위상은 다음과 같이 얻어진다:

R(x)와 I(x)은 F(x)의 real과 imaginary에 해당된다. Fourier transform의 이점은 이러한 두가지 요소가 영상 크기의 receptive filed을 capture할 수 있다. 게다가, 이 두가지 요소는 얼굴 영상의 다른 특징을 capture한다. 위의 그림 1에서 원본 얼굴 영상과 이에 해당하는 진폭과 위상 영상 그리고 진폭과 위상을 각각 얼굴 영상으로 바꾼 영상을 보여준다. 명백하게 위상 요소로 재구성된 얼굴 영상은 LR 영상이 잃어버린 선명한 얼굴 구조 정보를 가지고 있다. 그러므로 위상 요소는 얼굴의 구조를 잘 유지할 수 있고 FSR 성능을 개선 시킬 수 있다. 이러한 두 관점을 비춰볼 때, SFMNet은 long-distance dependency를 capture할 뿐만 아니라 local dependency를 활용할 수 있다.
SFMNet
Long and short-ranage dependency를 고려하는것은 FSR의 성능을 개선시킬수 있고 Fourier transform은 영상 크기의 receptive field를 쉽게 얻을 수 있으므로, 공간과 주파수 영역 둘다 explore하는 FSR 방법인 SFMNet을 제안한다. 제안된 SFMNet은 그림 2와 같다. Fourier transform을 사용하는 주파수 branch는 영상 크기의 receptive field를 가져 global dependency를 capture할 수 있다. 공간 branch는 local dependency를 capture하고 global frequency information과 통합되어 최종 SR 결과를 만든다. Global 주파수 정보와 local 공간 정보는 상호보완적이고 다르다, 이러한 상호보완적인 정보를 상호적이고 효율적으로 통합하기 위해 적응적 attention map을 생성할 수 있는 FSIB를 설계한다.

Overview
LR 얼굴 영상이 주어지면, feature를 추출하기위해 두 branch로 부터 두개의 convolutional layer를 지나 주파수와 공간 branch에 해당되는 feature를 생성한다. 그리고 나서, 추출된 feature는 multi-scale feature를 추출하기 위해 spatial-frequency mutual learning modules (SFMLM)으로 들어간다,

SFMLM이후 frequency, spatial feature map들은 reconstruction layer에 들어가 그림 2처럼 frequency SR과 spatial SR을 복원한다.
모델이 FSR을 더 잘 수행하도록 하기 위해 pixel-level과 frequency-level의 손실함수를 사용한다.

Loss는 각 pixel-level과 frequency-level이며, A(·)와 P(·)는 위상과 진폭을 의미한다. Pixel-level loss는 SFMNet을 high-fiedlity 얼굴 영상으로 재구성하도록 이끌고, frequency-level loss는 frequency 정보를 배우도록 돕는다. 게다가, GAN의 강력한 생성 능력의 이점을 얻기 위해, 공간과 주파수 영역에 adversarial loss를 도입한다. 세부적으로, 공간 식별자와 주파수 식별자를 재구성된 SR 결과와 HR을 공간과 주파수 영역에서 식별하도록 설계한다. 두개의 식별자는 유사한 구조를 공유하지만 다른 입력을 갖는다. 공간 식별자의 입력은 SR 혹은 HR, 주파수 식별자는 진폭과 위상이 연결된 SR 혹은 HR을 입력으로 갖는다.

또한 perceptual loss도 사용한다.

이로써 전체 loss는 다음과 같다.

Spatial-frequency Mutual Learning Module
SFMNet의 SFMLM의 각 추출되는 i 번째 feature map은 다음과 같이 정의된다.

f는 frequency block (FRB)와 spatial block (SPB)이며 F는 추출된 feature map이다. SPB는 residual block으로 구성되고, FRB는 그림 2의 오른쪽과 같이 주파수 영역에서 진폭과 위상으로 변환시킨 뒤 convolutional layer를 사용하고 이를 다시 영상으로 변환해준다. 주파수 branch는 공간 branch가 local dependency를 추출하는 동안 영상 크기별 receptive field를 global dependency를 capture할 수 있다. Global과 local dependencies는 상호보완적이고 FSR에 용이할 수 있어, FSIB를 설계한다. FSIB는 모든 SPB뒤에 있어 상호 보완성을 활용한다.

Frequency-spatial Interaction Block
주파수 branch는 global 정보를 공간 branch는 local 정보를 추출하므로 이를 결합해야 한다. 이를 달성하기 위해, global 주파수 정보와 local 공간 정보를 상호적이고 적응적이게 혼합할 수 있는 frequency-spatial interaction block (FSIB)을 설계한다. 그림 3에 묘사되듯이, FSIB는 먼저 두개의 정보를 cross-attention으로 융합하고 나서 다른 attention map을 생성한다.

먼저, spatial feature map과 frequency feature map은 FSIB에서 두개의 convolutional layers를 거친뒤 각 feature map을 얻는다. 그리고 나서, global 주파수 정보와, local 공간 정보를 상호보완적으로 활용하기 위해, self-attention에 기반한 spatial-frequency cross-attention (SFCA)를 설계한다.
SFCA
좀 더 구체적으로, 두개의 입력을 가진 SFCA는 source 정보와 guidance 정보를 포함한다. 두 정보를 완벽히 융합하기 위해, 다른 convolutional layer에서 나온 source 정보를 Q, guidance 정보를 K와 V로 사용한다. 이후, source와 guidance 간의 cross-attention은 다음과 같다.

Channel 차원을 따라서 global 상호작용을 capture 하고 연산량을 줄이기 위해 SFCA는 channel 차원을 따라서 계산된다.
Local 공간 정보와 global 주파수 정보간 모델이 상호작용하기 위해, 주파수 정보와 공간 정보가 FSIB에서 서로를 위한 source와 guidance가 되도록 한다.

이렇게 나온 두개의 결과를 상호 융합하기 위한 예측 네트워크로 pixel-wise attention을 예측할것을 제안한다. 자세하게는, 먼저 두개의 결과를 concat하고 concat된 결과를 convolutional layer와 sigmoid로 된 예측 네트워크를 통과하도록 한다.

출력은 예측된 attention이고 이것의 channel은 orignial feature보다 두배 크다. 주파수 정보와 공간 정보간의 다름과 상호보완적인 부분을 보면, 다음 식과 같이 channel 차원을 분할할 수 있다.
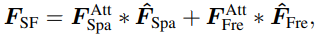
Experiments
Dataset and Metrics
- Train : CelebA(168,854), Test : Helen(50), CelebA(1,000)
- Image size 128×128, resize 32×32, 16×16
- PSNR, SSIM, LPIPS, NIQE
Implementation Details
- SFMLM의 수는 14, SRB의 residual block은 2
- Downsampling module과 Upsampling module은 각 FRB와 SRB이후에 삽입, SFMLM 1-6은 down, 9-14는 up
- PSNR-oriented model γ1은 0.01, GAN-based model은 pre-trained PSNR-oriented model 사용 γ2는 0.0005, γ3은 0.001, γ4는 0.1로 설정
- Optimizer는 Adam, learning rate는 0.0001
- Deep learning framework PyTorch, GPU는 RTX 3090
Comparison with the state-of-the-arts
제안한 모델을 검증하기 위해 SotA 모델들과 비교한다. 정량적 결과는 표 1과 같다. 공평하게 하기위해 모든 모델들은 같은 train, test data를 사용한다. 제안된 방법이 가장 좋은 성능을 보였다. SRCNN과 EDSR은 얼굴 영상을 설계하지 못해서 복원하는데 실패 한다. FSRNet과 DIC는 사전에 얼굴을 추정하고 사전에 활용하는것을 제안했지만, 사전에 추정된것은 정학성을 보장하지 못해 FSR 성능에 제한적이다. Spatial space에서 SPARNet과 SISN과 비교했을때 제안하는 방법이 주파수 정보를 활용할수 있어 더 좋은 성능을 보인다. PSNR과 SSIM 뿐만 아니라 parameter와 running time도 비교했을때, 제안하는 방법이 성능과 모델 complexity에서 좋은 균형을 가진다.

정성적으로 비교한 결과는 그림 4와 같다. 모든 방법들은 얼굴 구조를 재구성할 수 있지만, 제안하는 방법은 치아나 눈 같은 얼굴의 구성요소를 특히 더 잘 복구한다는 이점이 있다. 제안하는 방법이 다른 방법들 보다 좀더 현실적이고 자세하게 복원하고 이는 robustness하고 stability 한 것을 입증한다. 이는 제안하는 방법이 global face feature와 implicit 위상을 사용할 수 있기 때문이다. 게다가 공간 영역과 주파수 영역 에서 비교하기위해 이를 시각화 시킨것을 그림 5에 나타냈다. 제안된 방법이 가장 현실적인 얼굴을 디테일을 살렸을 뿐만 아니라 주파수 영역에서 또한 가장 정확하게 복원했다.


Face Recognition Results
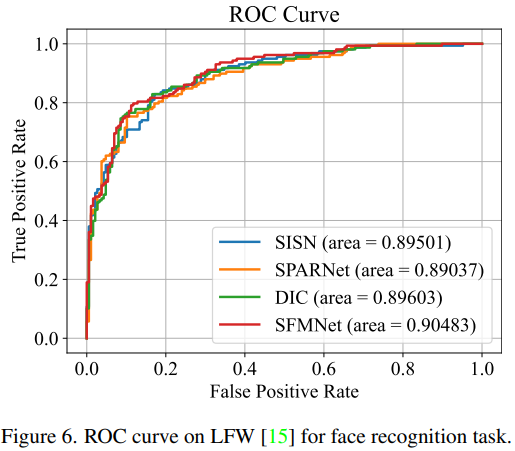
좋은 성능의 FSR 방법은 높은 PSNR과 SSIM을 달성할 뿐만 아니라, 얼굴 인식과 같은 task에서도 개선되어야 한다. 그러므로, 다른 FSR 방법들과 비교해 얼굴 인식률을 측정해 검증한다. Deepface 모델로 얼굴을 인식하며 ROC curve를 그림 6에 나타냈다. 묘사된 결과 제안된 모델 SFMNet이 ROC curve의 아랫부분 AUC가 가장 넓어 가장 좋은 성능을 보였다.
Real-world Face Restoration
게다가, 제안된 모델을 real-world face image restoration에서도 성능을 검증한다. Real-world face image restoration을 위한 존재하는 방법들은 reference prior, generative prior 혹은 vector-quantized dictionary의 잠재성을 활용한다. 방법을 비교하기 위해 Resotreformer와 VQFR을 선택한다. 비교한 그림은 그림 7과 같고, Restoreformer는 많은 노이즈가 있는반면, VQFR은 높은 perceptual quality를 가진다. 하지만, VQFR로 복원된 얼굴은 약간 일그러지고, 복원된 얼굴들의 표정과 fidelity가 원래 얼굴들과 다르다. 제안된 모델은 128×128크기와 bicubic로 downsampling된 데이터로 훈련되었지만 다른 모델은 512×512크기의 complex degradation으로 생성된 데이터로 훈련되었으므로 제안된 방법이 real-world LR face 복구에도 사용될 수 있다.

Ablation Study
×8의 SFMNet에서 핵심 구성요소의 효율성을 검증한다. The effectiveness of the FSIB: 먼저, SBN이라고 명명한 frequency branch를 제거해 spatial branch만 있는 방법을 검증한다. 그리고 나서, frequency branch를 다시 복구하고 FSIB를 SFMNet과 비슷한 parameter를 가지도록 concatenation과 convolutional layer로 구성된 SFCNet을 검증한다. 마지막으로, SFMNet을 검증한다. 이에 대한 결과는 표 2에 나타난다. SFCNet이 SBN보다 조금 더 높은 성능을 보이며, 이는 frequency branch가 모델의 표현 능력을 개선하기 위해 global dependency를 제공할 수 있음을 증명한다. 하지만, concatenation이 주파수와 공간 상의 상호작용을 수행하기에는 너무 간단해 성능 개선의 제한이 있다. FSIB를 사용한 SFMNet은 PSNR과 SSIM 두 분야 모두 가장 좋은 성능을 보였다. 제안된 SFCA의 효율성을 검증하기 위해, SFCA를 concatenation과 convolutional layer로 구성된 layer로 대체 히고 이를 SFCCNet이라고 한다. SFCCNet과 비교한 결과 SFCA가 FSR 성능을 개선 시킬수 있음을 입증했다.

The effectiveness of the frequency discriminator: 주파수 discriminator의 효율성을 분석하기 위해 실험을 한다. 구체적으로 frequency discriminator이 있는것과 없는 모델의 결과를 비교하여 표3에 나타낸다. SD와 SFD는 있는것과 없는것을 의미한다. (글이 잘 못 적혀 있는듯, 앞 줄에서는 SD가 주파수 판별기가 있고 SFD가 없는것인데 뒷 문장에서는 있는것이 정량적 측면에서 더 좋은 성능을 낸다고 적혀 있음) 정량적 측면에서, 주파수 판별기의 도입은 모델의 LPIPS와 NIQE의 성능을 분명히 향상 시킬 수 있다. 정성적 측면에서의 비교는 그림 8과 같다. 주파수 스펙트럼은 global 얼굴 구조를 capture할 수 있기 때문에 SFD에 의해 왜곡된 얼굴은 SD의 얼굴보다 더 현실적이고 시각적으로도 만족스럽다.


Conclusion
- Spatial domain과 frequency domain 간의 상호작용을 하는 SFMNet을 제안
- SFMNet은 spatial branch와 frequency branch로 구성
- Spatial branch는 spatial 영역에서 local facial feature를 추출, Frequency branch는 주파수 영역에서 image-size receptive field를 가져 global dependency를 capture
- Global과 local 정보를 상호작용시키기 위해 FSIB 설계
- Frequency discriminator를 frequency domain에서 모델을 이끌기 위해 개발
- 실험적 결과에서는 SotA를 달성
Paper
'딥러닝 논문 리뷰' 카테고리의 다른 글
| Local Implicit Image Function (LIIF) Review (2) | 2023.10.30 |
|---|---|
| A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution Review (0) | 2023.09.02 |
| CrossNet Review (0) | 2023.07.21 |
| SegFormer Review (0) | 2023.07.03 |
| OCELOT: Overlapped Cell on Tissue Dataset for Histopathology Review (0) | 2023.06.27 |



