
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SISR
- hypergraph
- LIIF
- session-based recommendation
- Feature reuse
- DIINN
- Cityscapes
- ADE20K
- arbitrary scale
- ConvNeXt
- Cell detection
- Reference Super-Resolution
- Cell-tissue
- INR
- graph neural network
- SegFormer
- implicit representation
- Super-Resolution
- Tissue segmentation
- Reference-based SR
- Referense Super Resoltuion
- TAAM
- CrossNet
- TRANSFORMER
- Graph
- FRFSR
- deep learning
- GNN
- Zero-Shot sr
- GNN in image
- Today
- Total
딥러닝 분석가 가리
ConvNeXt : A ConvNet for the 2020s 본문
"A ConvNet for the 2020s"
Abstract
2020년대에 들어서 시각 인식은 합성곱 층으로 구성된, ConvNet들 보다 image classification 에서 높은 성능을 차지한 Vision Transformers (ViTs)가 주가 되었다. 반면에, 기초적인 ViT는 object detection이나 semantic segmentation과 같은 일반적인 computer vision (CV)에 적용했을때 어려움이 있다. 그래서 이전의 ConvNet 처럼 계층적 transformer (Swin Transformer와 같은)로 만들어, 일반 vision 백본으로 사용가능하도록 만들고 다양한 vision task에서 뛰어난 성능을 보여주었다. 하지만, 이러한 혼합적 접근방법의 효과는 합성곱의 고유의 inductive biases 보다는 여전히 transformer의 고유한 우수성에 기인한다. 본 연구에서는 ConvNet을 재설계 및 재검토하고 ConvNet이 달성할 수 있는 한계를 시험한다. 저자는 ViT 처럼 ResNet을 점진적으로 현대화 하고 그 과정에서 성능 차이에 크게 기여할 수 있는 몇가지 주요 요소를 발견한다. 이러한 탐색의 결과는 순수 ConvNet으로 구성된 ConvNeXt 모델을 만든다. ConvNeXt는 정확성과 확장성 면에서 transformer보다 유리하며 ImageNet top-1 정확도는 87.8%를 달성하고 COCO detection, ADE20K segmentation에서는 Swin Transformer 보다 우수함을 입증했다.
Introduction

딥러닝의 영향은 2010년대 부터 십년 동안 진보되었다. 이는 합성곱 층으로 이루어진, ConvNet이 시각 인식 분야에서 성공적인 구조로 전환 되었기 때문이다. 2012년에 들어서, AlexNet이 소개되며 시각적 특징 학습에 대한 잠재력을 보여 "ImageNet moment"를 촉발시키며 computer vision의 새로운 시대를 열었다. 이는 VGGNet, Inception, ResNe(X)t 등 대표적인 ConvNet이 등장해 정확성, 효율성 및 확장성의 다양한 측면에 초점을 맞춰 많은 유용한 디자인 원칙을 대중화 했다.
ConvNet은 "sliding window" 전략을 사용하고 다양한 CV 어플리케이션에 잘 적합하도록 만드는 몇가지 inductive biases를 가지고 있다. 가장 중요한것은 translation equivariance으로 object detection과 같은 작업에 바람직한 속성이다. 또한 sliding window 방식으로 사용될때 계산이 공유된다는 사실 때문에 본질적으로 효율적이다.
비슷한 시기에 natural language processing (NLP)는 다른 방향으로 발전되었다. Recurrent neural network (RNN) 대신에 transformer가 사용되며, transformer가 주요 backbone 구조가 되었다. Language와 vision 영역의 차이점이 있음에도 불구하고 2020년도에 두 영역은 transformer에 수렴되었고, vision transformer (ViT)는 네트워크의 구조를 완전히 바꿔놓았다. 영상을 일련의 패치로 분할하는 "patchify" 층을 제외하고, ViT는 영상의 inductive bias를 도입하지 않고 기존의 NLP transformer에서 최소한만을 변경한다. ViT의 주요한 점은 scaling behavior: 더 큰 모델과 데이터셋 크기의 도움으로 인해 transformer는 기존의 ResNet보다 상당히 차이가 큰 성능을 보일수 있다. Image classification에서 이러한 결과는 유의미 했지만, CV는 imgae classification에 국한되는것이 아니다. 앞선 논의와 같이, 지난 십여년 동안 수많은 CV task의 해결책은 fully convolutional paradigm, sliding-window에 상당이 의존되었다. ConvNet의 inductive biases 없이, 기본 ViT 모델은 일반적인 CV backbone으로 채택되는데 많은 어려움이 있다. 가장 큰 어려움은 입력 크기와 관련하여 quadratic 복잡성을 갖은 ViT의 global attention 설계이다. 이는 ImageNet classification에 적합할 수 있지만 고해상도 입력에서는 빠르게 다루기 어렵다.
이러한 차이를 줄이기 위해 혼합된 접근법을 사용한 계층적 transformer가 도입된다. 예를들어 "sliding window" 전략 (attention within local window)이 transformer에 다시 도입되어 ConvNet과 유사하게 동작될 수 있게 되었다. Swin transformer는 이러한 방향에서 획기적인 방법으로, transformer가 일반적인 vision backbone으로 채택되고 image classification을 넘어 CV에서 sota 성능을 달성할 수 있도록 했다. Siwn transformer의 성공과 빠른 채택은 또한 한 가지를 드러냈는데, convolution의 본질이 중요하지 않게 되는것이 아니라 여전히 많은 것을 요구하며 절대 사라지지 않는다는 것이다.
이러한 관점에서, CV를 위한 transformer의 많은 발전은 convolution으로 돌아가는것에 목적을 둔다. 하지만 이러한 시도는 비용 문제를 초래한다: sliding window self-attention은 많은 비용을 초래, cyclic shifting 같은 방법으로 속도를 최적화 할 수 있지만, 시스템 설계가 더 정교해진다. 반면에, ConvNet은 이미 이렇게 요구되는 속성들에서 안정적이므로 역설적이다. ConvNet들이 영향력을 잃어가는 주된 이유는 (hierarchical) transformer가 많은 vision task에서 ConvNet보다 우수하고 성능 차이는 일반적으로 transformer의 우수한 scaling behavior가 요인하며, multi-head self-attention이 핵심 요소 이다.
지난 십여년 동안 점진적으로 개선된 ConvNets과 달리 ViT의 채택은 한 단계 변화 였다. 최근 문헌에서 , Swin Transformer와 ResNet 주로 채택되어 비교된다. ConvNets과 계층적 ViT는 다르지만 유사하기도 하다: 둘 다 유사한 inductive biases가 있지만, 학습히 상당히 다르게 적용된다. 이러한 작업에서, 저자는 ConvNet과 Transformer 간의 구조적 구별점을 조사하고, 네트워크 성능을 비교할때 confounding 변수를 식별하려고 노력한다. 이러한 연구는 ConvNets을 위해 ViT 전과 후의 차이를 줄이는 경향이 있을 뿐만 아니라 순수한 ConvNet의 한계를 시험해 뛰어넘을수 있도록 한다.
이를 위해 표준적인 ResNet50을 개선된 절차로 훈련시킨다. 점진적으로 Swin-T와 같은 계층적 ViT에 기조하여 구조를 점진적으로 "modernize"한다. 이러한 탐색은 핵심 질문을 낸다: 'How do design decisions in Transformers impact ConvNet's performance?' 저자는 성능 차이에 기여하는 몇가지 핵심 요소를 발견한다. 결과적으로, 순수한 ConvNet으로 구성된 ConvNeXt를 제안한다. ConvNeXt는 표준 ConvNets의 효율성을 유지하며 transformer와 비교하여 다양한 task에서 뛰어난 성능을 입증했다.
Modernizing a ConvNet: a Roadmap
ResNet-50을 기준 삼아 Swin-T 처럼 현대화 시켜가며 성능을 비교한다. 현대화 시키는 방법은 아래와 같다:
- macro design
- ResNeXt
- inverted bottleneck
- large kernel size
- various layer-wise micro design
아래 그림 2는 절차에 대한 결과이다.

Training Techniques
네트워크 구조 설계 부분에서 훈련 절차 또한 성능에 영향을 미치므로 ResNet의 훈련 절차를 ViT의 절차를 따라 가도록 한다.
- Epochs: 90 -> 300, Optimizer: AdamW, Augmentation: Mixup, Cutmix, RandAugment, Random Erasing
- Regularization schemes including Stochastic Depth
- Label Smoothing
결과 정확도 76.1% -> 78.8%로 2.7p% 향상되었다.
Macro Design
Swin-T의 거시적 네트워크 설계를 분석한다. Swin-T는 ConvNet을 따르며 각 단계마다 feature map 해상도가 다른 multi-stage를 사용한다. Swin-T는 두가지 흥미로운 설계가 있는데: stage compute ratio와 stem cell 이다.
Changing stage compute ratio
Swin-T의 단계별 계산 비용은 1:1:3:1 large Swin-T는 1:1:9:1 이므로 이에 맞춰 ResNet-50의 block 갯수를 (3, 4, 6, 3)에서 (3, 3, 9, 3)으로 변경한다. 그 결과 정확도가 78.8% -> 79.4%로 0.6p% 향상되었다.

Changing stem to "Patchify"
네트워크가 시작되는 부분에 처음 입력이 들어오는 부분을 stem 이라고 한다. 기본 ResNet은 7×7 kernel과 2×2 stride를 사용해 입력 크기를 4배 dwonsampling 하는데, ViT는 large kernel size에 해당되는 (14×14 or 16×16)을 겹치는 부분없이 convolution 하는 더 공격적인 "patchify"을 한다. Swin-T는 아키텍처의 multi-stage 설계를 수용하기 위해 이보다 작은 "patchify", patch size가 4를 사용한다. 이러한 방식이 좋은 효과를 가져왔기 때문에 ResNet도 4×4 kernel, 4 stride를 활용한다. 그 결과 정확도가 79.4% -> 79.5%로 0.1p% 향상 되었다.
ResNeXt-ify

ResNeXt에서 적용된 방식을 사용한다. 이의 핵심적인 요소는 grouped convolution이다. 이는 convolution filter가 다른 그룹으로 분할된것이다. 이는 bottleneck block에 3×3 conv layer로 grouped convolution을 구성한것으로 상당히 많이 FLOPs를 줄이고, 네트워크의 width가 커져 capacity가 확장 되었다. 또한, depthwise convolution을 사용하여 연산량은 줄이고, capacity는 유지하도록 한다. 또한, Swin-T와 같은 channel 수를 가지게 한다 (64 to 96). 그 결과 성능이 79.5% -> 80.5%로 1p% 향상 되었다. 다만 channel 수가 늘어 FLOPs가 4.5 -> 5.3으로 늘어난다.
Inverted Bottleneck
모든 transformer block에서 한 가지 중요한 설계는 inverted bottelenck을 생성한다는 것이다. 즉, MLP block의 hidden dimension은 input dimension보다 4배 크다. 이는 아래 그림 4에서 볼 수 있다.

사실 이러한 transformer의 4배 확장되는 inverted bottleneck 구조는 MobileNetV2에 의해 대중화되어 이후 몇몇 ConvNet 구조에서도 사용 되었다.
그림 3은 inverted bottleneck 구조를 설계한 것이다.
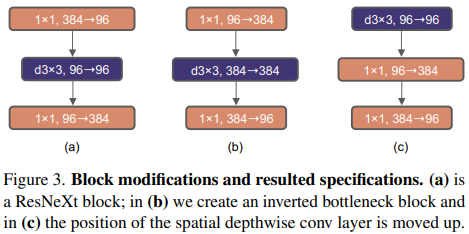
Depthwise convolution에 대한 FLOPs가 늘어남에도 불구하고, downsampling residual block's shortcut 1×1 conv layer에서 FLOP의 감소로 인해 네트워크의 FLOPs를 4.6G까지 감소시킨다. 또한 이러한 결과는 성능을 80.5% -> 80.6%로 향상 시킨다.
Large Kernel Sizes
이 단계에선 large convolutional kernel에 대한 behavior에 초점을 맞춘다. ViT와 가장 구별되는 부분은, global receptive field를 가지는 non-local self-attention이다. Large kernel은 이전 ConvNet에서도 사용되었는데 VGG이후 3×3 kernel을 쌓는것이 효율적이라고 기준화 되었다. Swin-T는 window size를 7×7로 사용하므로 ConvNets에 large kernel-size를 사용하는것을 연구한다.
Moving up depthwise conv layer
Large kernel을 탐색하기 위해, 하나의 전제조건은 depthwise convolution layer의 위치를 그림 3(b) -> 그림 3(c) 처럼 위로 올리는 것이다. 이는 transformer에서도 명확한 설계이며: MSA block은 MLP layer 보다 먼저 배치된다. Inverted bottleneck block은 자연스로운 선택이다 - 복잡하고 비효율적인 모듈은 채널 수가 적은 반면, 효율적이고 dense한 1×1 conv는 무거운 연산을 수행한다. 이러한 단계는 FLOPs를 4.1G까지 낮추지만 일시적으로 성능이 79.9% 하락된다.
Increasing the kernel size
Large kernel 크기를 갖는것은 상당히 큰 이점이 있는데, 이를 실험하기 위해 kernel의 크기를 3, 5, 7, 9, 11을 실험한다. 그 결과 7×7일때 80.6%로 가장 높은 성능을 달성한다.
Micro Design
네트워크 구조의 미시적 설계를 수정한다.
Replacing ReLU with GELU
Transformer에서는 activation function을 ReLU대신 GELU를 사용한다. GELU는 ReLU를 부드럽게 변형한 것으로 볼 수 있는데 이러한 특징을 살려 ConvNet에서 ReLU 대신 GELU를 사용해 정확도를 80.6%로 다시 상승시켰다.
Fewer activation functions
Transformer와 ResNet의 작은 차이점 하나는 activation function이 transformer가 더 적다는 것이다. 이는 위의 그림 4에 나온것 처럼 마지막 MLP layer에만 activation function을 사용한다. 그래서 ConvNet도 이처럼 GELU를 하나만 사용한다. 그 결과 80.6% -> 81.3%로 0.7p% 향상되었다.
Fewer normalization layers
Transformer는 보통 normalization layer가 적게 사용된다. 그래서 batchnorm (BN) layer를 지우고 그림 4처럼 하나의 normalization layer를 사용한다. 그 결과 성능이 81.4%로 향상 되었다.
Substituting BN with LN
Transformer는 BN을 사용하지 않고 layer norm (LN)을 주로 사용한다. 하지만 ResNet에서 BN을 LN으로 직접적으로 교체하면 최적이 아닌 성능을 얻을 수 있다. 네트워크의 구조 및 훈련 기법의 모든 수정을 통해 BN 대신 LN을 사용하는것이 미치는 영향을 검토하고 LN이 훈련되는데 있어 문제점이 없을 관찰한다. LN을 사용한 결과 정확도가 81.5%로 0.1p% 향상되었다.
Separate downsampling layers
ResNet에서 spatial downsampling은 각 단계가 시작될때, 3×3 kernel을 사용하고 stride를 2로준 convolution을 사용한다. 반면 Swin-T에서는 stage 사이에 별도의 downsampling layer를 추가한다. 비슷한 전략인 2×2 kernel과 stride를 2로 한 conv layer를 알아본다. 이러한 수정은 분산훈련으로 이어지며, spatial 해상도가 변경되는 곳 마다 normalization layer를 추가하는것이 훈련을 안정화 하는데 도움이 될 수 있음을 보여준다. 그 결과 정확도가 82%를 달성하며 기존의 Swin-T인 81.3%를 넘어섰다.
Experiments

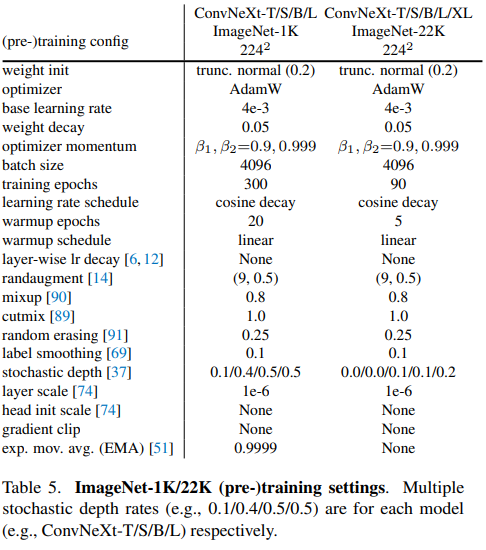
Training settings

Results
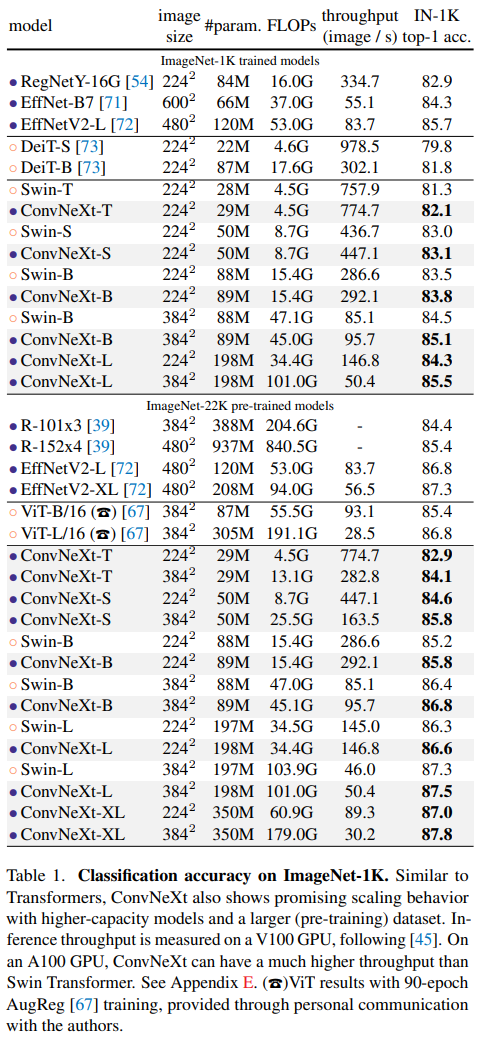
Image classification
Object detection

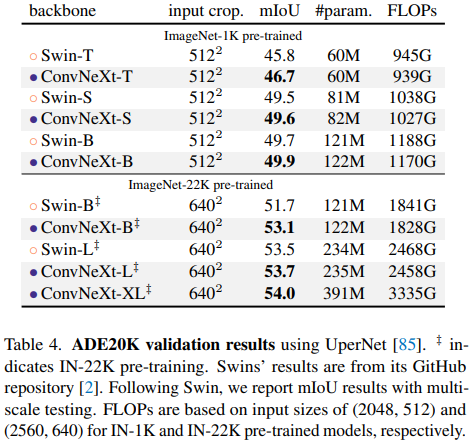
Semantic segmentation
Isotropic ConvNeXt vs ViT
ConvNeXt가 모든 층에서 동일한 해상도를 가지는 ViT 스타일 등방성 구조로 변환할 수 있는지 조사한다. 먼저 ViT와 동일한 feature dimension (384/768/1024)을 같도록 하고, depth는 parameter와 FLOPs가 동일해지도록 18/18/36으로 설정한다. 블럭의 구조는 그림 4와 같이 동일하게 유지한다. ViT는 DeiT(S/B)와 MAE(L) 방식으로 훈련되었고, ConvNeXt는 이전과 동일한 상태로 훈련되지만, warmup epochs가 더 길어진다. 이에 대한 결과는 표 2에 나와같다.

Conclusions
- ConvNets은 일반적인 vision backbone으로 많이 사용되었지만, ViT, Swin-T 가 등장하며 transformer가 더 정확하고 효율적이며 ConvNets보다 유연하여 ViT 등이 더 많이 사용됨
- 순수한 ConvNet으로만 구현되어 ViT와 Swin-T 보다 우수한 ConvNeXt를 제안
- 이 연구의 결과가 널리 알려진 여러 견해에 도전하고 사람들이 CV에서 convolution의 중요성을 다시 한번 생각하길 바람



