
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Referense Super Resoltuion
- Zero-Shot sr
- DIINN
- SISR
- ADE20K
- Feature reuse
- Cell-tissue
- implicit representation
- deep learning
- Tissue segmentation
- TRANSFORMER
- TAAM
- Graph
- Reference-based SR
- ConvNeXt
- session-based recommendation
- FRFSR
- GNN
- LIIF
- Super-Resolution
- GNN in image
- graph neural network
- Cityscapes
- CrossNet
- hypergraph
- SegFormer
- Cell detection
- INR
- arbitrary scale
- Reference Super-Resolution
- Today
- Total
딥러닝 분석가 가리
NestedFormer Review 본문
"NestedFormer: Netsted Modality-Aware Transformer
for Brain Tumor Segmentation"
Abstract
- Multi-modal MR imaging은 풍부한 보완 정보를 제공하여 뇌종양을 진단하는데 임상에서 주로 사용됨
- 기존의 multi-modal MRI 분할 방법은 다른 modality 간의 concatenation으로 융합하는데, 이는 서로 다른 modalities 간의 비 선형적 의존성을 활용하기 어려움
- Modality 내부, modality 간의 관계를 명확하게 활용하는 Nested Modality-Aware Transformer (NestedFormer)를 제안
- Transformer 기반의 multi-encoder와 single-decoder 구조를 설계해, 다른 modalities 간의 high-level 표현을 융합, modality sensitive gating (MSG)를 적용해 더 효율적으로 skip connection 함
- Multi-modal fusion은 Nested Modality-aware Feature Aggregation (NMaFA) module에서 시행, 이는 3 방향 spatial-attention 으로 각각의 modalities의 long-term dependencies를 개선, 그리고 핵심적인 contextual 정보를 보완하기 위해 cross-modality attention을 사용
- BraTS2020과 Meningiomas segmentation (MeniSeg) datasets에서 SOTA를 달성
Introduction
뇌종양은 전세계적으로 가장 흔한 암 중 하나로, 신경교종(gliomas)은 다양한 수준의 공격성을 가진 악성 뇌종양이며 수막종 (meningiomas)은 성인에게서 가장 흔하게 나타나는 원발성 두개내 종양이다. Multi-modal MRI는 뇌종양을 분석하기 위해 많은 정보를 제공해 주며, 이러한 영상들은 아래 그림 1과 같다.

최근들어, CNN과 ViT를 활용한 방법들은 뛰어난 성능을 보였다. 뛰어난 성능을 보인 기존의 방법들은 network 입력이 concatenated image인 early-fusion 전략을 사용하는데, 이는 다른 modalities간의 비선형적 관계를 활용하기 어렵다. 이를 해결하기 위해 최근에는 다른 인코더에서 추출된 modality-specific feature를 중간 layer에서 융합하는 layer-fusion 전략을 사용한다. 하지만, 이러한 전략을 사용하는 기존의 방법은 다른 modalities 간의 long-range spatial dependencies을 구축하지 않아, 보완할 수 있는 정보를 충분히 활용하지 않는다.
- 효율적이고 강건한 뇌종양 분할을 위해 NetstedFormer라고 불리는 새로운 nested modality-aware transformer를 제안
- 서로 다른 MRI의 global dependencies를 강조한 차이가 있는 volumetric spatial feature를 추출하기 위해 효율적인 Global Poolformer를 제안
- 상호보완적인 feature를 더 잘 추출하고 몇개의 modalities도 융합하기 위해, Nested Modality-aware Feature Aggregation (NMaFA) module을 제안
- NMaFA는 single-modality의 공간적 일관성과 cross-modality의 일관성 둘다 명확하게 고려하고, nested transformer를 활용해 intra- and inter-modality 간 long-range dependencies를 관여해 보다 효율적으로 feature를 표현함
- 3 차원의 spatial-coherence를 효율적으로 연산하기 위해 Tri-orientated Spatial Attention (TSA)를 제안
- Deocding에서 feature 재사용 효과를 향상시키기 위해 modality-sensitive gating (MSG) 모듈을 개발
- MSG는 효과적인 skip connection을 위해 modality-aware low resolution feature를 동적으로 filtering 함
Method
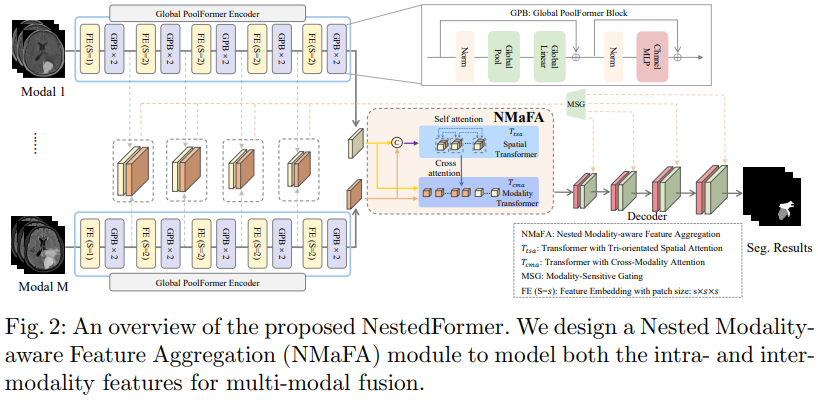
NestedFormer는 위 그림과 같으며 총 3가지 요소로 구성되어 있다.
- 서로 다른 modalities의 multi-scale representation을 얻기 위한 multiple encoders
- Multi-modal 간의 high-level embedding feature 관계를 활용하기 위한 NMaFA fusion module
- 디코더에서 modality-sensitive low-resolution feature를 선택적으로 전송하기 위한 gating 전략
Global Poolformer Encoder
각 modality의 local context 정보를 더 잘 추출하기 위해 Poolformer를 modality-specific encoder로 확장한다. Poolformer는 Transformer의 computation-intensive attention module을 average pooling으로 대체함으로써 우수한 성능을 보인 모델이다. 그러므로, global information을 개선하기 위해, Poolformer에서 average pooling 대신에 global pooling을 사용하는 Global Poolformer Block (GPB)를 설계한다. GPB block은 learnable global pooling (GP)와 MLP block으로 구성된다. 입력을 X 출력을 Z로 해 이를 수식으로 표현하면 다음과 같다.

Global Poolformer encoder는 5개의 그룹으로 한 개의 feature embedding (FE) layer와 두 개의 GPB blocks으로 구성된다. 각 FE layer는 3D convolution이며, 첫 FE layer는 1x1x1 patch size를, 나머지는 2x2x2에 stride를 2로 사용한다. 인코더의 최종 출력은 입력의 1/16이며 channel은 128이다.
Nested Modality-Aware Feature Aggregation

High-level feature가 주어졌을때, NMaFA는 T_tsa를 기반으로 spatial-attention을, T_cma을 기반으로 cross-modality attention을 사용한다. T_tsa는 각 modality 공간에서 다른 patch들 간의 long-range correlation을 계산하기 위한 self-attention 방법을 활용한다. 서로 다른 modalities feature maps은 channel을 기준으로 concatenated 되어 high-level embedding을 얻는다. T_tsa는 이를 입력으로 받고 출력으로 spatially-enhanced feature를 얻는다.
T_cma는 서로 다른 modalities간의 inter-modality fusion을 달성하기 위해 cross-attention 방법을 활용한다. 이를 위해, 인코더의 출력은 flatten sequence를 얻기위해 spatial dimension으로 cocatenate 되어진다. 이때, Token Learner 전략을 사용하며, 입력으로는 T_tsa의 출력이 Q, spatial dimension으로 concatenate된 feature map이 K, V로 입력되어 최종 출력을 얻는다.
Transformer with Tri-orientated Spatial Attention. Volumetric embedding을 위한 spatial attention의 연산 효율성을 개선하기 위해 axial-wise attention MHA_z, plane-wise attention MHA_xy, window-wise attention MHA_w를 활용한다. MHA_z는 수직 방향을 따라서 featue token들의 long-range 관계를 모델링; MHA_xy는 각 slice 이내의 long-range 관계를 모델링; MHA_w는 sliding window를 사용해 local 3D-window의 관계를 모델링 한다. 이러한 attention을 식으로 표현하면 다음과 같다.

이러한 방법으로 모델은 local important region 특징 추출을 개선할 뿐만 아니라 적은 연산량으로 global feature dependencies를 계산한다.
Transformer with Cross-Modality Attention. T_tsa는 각 modality 내의 의존성을 개선시키지만, modality간의 통합은 patch embedding을 통해 이루어진다. Modalities간의 관계를 명확하게 활용하기 위해 서로 다른 modalities의 feature token을 spatial dimension을 따라서 concatenate한다. 이후 cross-attention을 사용해 modality dependency 정보를 개선한다.
Modalilty-Sensitive Gating
디코더에서는 feature map을 먼저 4D feature map으로 만들고, 이 feature map은 점진적으로 3D convolution과 2x upsampling을 거쳐 segmentation되어진다. 인코더 feature들은 multi-modal이다. 따라서, 인코더 feature들을 modality의 중요성을 따라서 필터링 하기 위해 modality-sensitive gating 전략을 skip connection에 설계한다.

FC는 1x1x1 convolutional layer, U는 2x upsampling.

최종 output은 위 식을 통해 계산되어진다.
Experiment
Implementation Details
PyTorch1.7.0, NVIDIA GTX 3090 GPU. Loss function은 soft dice loss와 cross-entropy, Optimizer는 AdamW, weight decay 는 1e-5, Learning rate는 1e-4, T_tsa는 두개, T_cma는 1개 사용, MHA_w에서 window-size는 BraTS2020에서는 (2,2,2), MeniSeg dataset에서는 (2,4,4) 사용
사용한 datasets은 BraTS2020과 MeniSeg, 평가 지표는 dice score와 HD95를 사용
Comparison with SOTA Methods
NestedFormer가 intra- and inter-modality간의 관계를 명시적으로 탐색함으로써 다중 MRI를 더 잘 융합했기 때문이다.



Ablation study

Conclusion
- Novel multi-modal segmentation framework NestedFormer를 제안
- M개의 modalities의 특징을 Global Poolformer Encoder로 추출
- High-level feature는 NMaFA로 효율적으로 융합, low-level feature는 MSG로 선택적 융합
- 제안된 framework는 양식에 구애받지 않으며, 다른 multi-modal medical data로 확장 가능
- 향후 연구로는 세분화 성능을 더욱 향상시키기위해 low-level 융합을 개선할 예정



