
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- SISR
- ADE20K
- GNN in image
- Tissue segmentation
- Graph
- SegFormer
- FRFSR
- Reference-based SR
- DIINN
- Referense Super Resoltuion
- GNN
- CrossNet
- arbitrary scale
- ConvNeXt
- Cell-tissue
- deep learning
- INR
- TAAM
- implicit representation
- Cell detection
- Super-Resolution
- graph neural network
- Cityscapes
- session-based recommendation
- Zero-Shot sr
- TRANSFORMER
- Reference Super-Resolution
- LIIF
- hypergraph
- Feature reuse
- Today
- Total
딥러닝 분석가 가리
Local Implicit Image Function (LIIF) Review 본문
"Learning Continuous Image Representation
with Local Implicit Image Function"
Abstract
Visual 세계가 연속적인 방법으로 표현되는 동안, 기계들은 픽셀들의 2D 배열로 이미지들을 분리된 방식으로 저장하고 본다. 이 논문에서는, 이미지의 연속적인 표현을 배우는 방법을 찾는다. Implicit neural representation (INR)을 사용한 3D reconstruction에 영감을 받아, 이미지 좌표와 좌표 주변의 2D deep feature를 입력으로 하여, 주어진 좌표의 RGB 값을 예측하는 Local Implicit Image Function (LIIF)를 제안한다. 좌표들이 연속적이기 때문에, LIIF는 arbitrary resolution을 제시할 수 있다. 이미지를 연속적인 표현으로 생성하기 위해, self-supervised 방식으로 LIIF 표현이 있는 인코더를 SR로 훈련시킨다. 연속적인 표현의 학습은 학습시 제공되지 않은 30배 SR 까지 제시한다. 또한, LIIF 표현이 2D에서 이산 표현과 연속 표현 사이의 다리를 구축하고, 크기가 다양한 이미지 GT 정보로 학습 작업을 자연스럽게 지원하며 GT 정보의 크기를 조정함으로써 방법을 크게 능가한것을 보여준다.
Introduction
우리의 시각적 세계는 연속적이지만, 기계는 한 장면을 저장하고 2D pixel 배열로 제시하는 처리과정을 가진다. 이때 복잡성과 정밀도 사이의 균형은 해상도에 의해 조절된다. Pixel기반의 표현은 다양한 computer vision 작업에 성공적으로 적용되었지만, 해상도에 제약이 있다. 예를들어, 데이터셋은 종종 다른 해상도를 가진 이미지를 제시한다. 만약 CNN으로 훈련하기를 원한다면, 이 이미지들을 같은 크기로 조절해야한다. 이미지를 고정된 해상도로 표현하는것 대신에, 이미지를 연속적인 표현으로 나타내는 연구를 제시한다. 이미지를 연속적인 도메인에 정의된 함수로 모델링하여 필요에 따라 임의의 해상도로 복원할 수 있다.
이미지를 어떻게 연속적인 함수로 표현할 수 있는가? 제안하는 방법은 3D shape reconsturction을 위한 implicit neural representation (INR)에 영감을 받았다. INR의 핵심적인 아이디어는 객체를 해당 신호 (3D 객체 표면까지의 부호 거리, 이미지의 RGB 값)에 매핑하는 함수로 표현하는 것이며, 함수는 deep neural network에 의해 매개변수화 된다. 각 객체간의 개인적인 함수를 학습하는것 대신에 instance간의 지식을 공유하기위해, 인코더 기반의 방법은 다른 객체 간의 latent code를 예측하기위해 제안되었고, 그 후 디코딩 함수는 latent code를 좌표들에 대한 추가 입력으로 취하는 동안 모든 객체들에 의해 공유된다. 3D 작업에서 성공했음에도 불구하고, INR 이전의 인코더 기반의 방법은 숫자와 같은 단순한 이미지를 표현하는데만 성공했을 뿐 자연스로운 이미지를 표현하는데는 실패했다.
본 논문에서는 자연스럽고 복잡한 이미지를 연속적인 형태로 표현하기 위해 Local Implicit Image Function (LIIF)를 제안한다. LIIF에서 이미지는 공간 차원에 분포된 latent code의 집합으로 표현된다. 좌표가 주어졌을때, 디코더 함수는 좌표 정보를 취하여 주변의 local latent code를 입력으로 질의한 다음 주어진 좌표에서 RGB 값을 출력으로 예측한다. 좌표가 연속적이기 때문에, LIIF는 임의의 해상도로 제시될 수 있다.
픽셀 기반의 이미지에 대해 연속적인 표현을 생성하려면, 생성된 연속적인 표현이 입력 이미지보다 더 높은 정밀도로 일반화 될 수 있기를 바라기 때문에, 입력과 GT가 연속적으로 변경되는 up-sampling 크기에서 제공되는 SR의 self-supervised 작업을 통해 LIIF 표현을 가진 인코더를 훈련시킨다. 이 작업에서 pixel 기반의 이미지를 입력으로 받아들이면, 인코딩된 LIIF 표현은 입력의 더 높은 해상도의 대응물을 예측하도록 훈련된다. 대부분의 SR 연구는 convolution-deconvolution 프레임워크로 특정한 크기로 up-sampling 하는 방법을 학습하는데 초점을 둔다면, LIIF 표현은 연속적이므로 훈련 데이터가 제공되지 않은 x30배의 SR, 임의의 크기로 초해상화 할 수 있다.
또한, LIIF가 2D로 이상 표현과 연속 표현 사이의 다리를 구축한다는것을 증명한다. 크기가 다양한 이미지에서 학습 작업에서, LIIF는 다양한 크기에서 제공된 정보를 exploit 할 수 있다. 고정된 크기를 출력하는 이전 방법은 학습시키기위해 GT를 모두 같은 크기로 재구성할 필요가 있어, fidelity를 희생시킬수 있다. LIIF 표현은 임의의 해상도를 제시할 수 있어, GT 크기 재구성 없이 end-to-end 방법으로 훈련할 수 있다. 이는, GT의 크기를 재구성하는 방법에 비해 상당히 더 나은 결과를 보여준다.
Contribution
- 자연스럽고 복합적인 이미지를 연속적으로 표현하는 새로운 방법
- LIIF 표현은 훈련 도중에 제시되지 않은 x30배 까지 초해상화 할 수 있음
- LIIF는 크기가 다양한 이미지 학습시 효율적임

Local Implicit Image Function
LIIF 표현에서 연속적인 이미지 I^(i)는 2D feature map M^(i)로 표현된다. 디코딩 함수 f_θ (θ는 파라미터)는 모든 이미지 간에 공유되고, MLP로 파라미터화 되어잇으며 다음과 같이 나타난다.

z는 벡터, x ∈ X 는 연속적인 이미지 영역에서의 2D 좌표, s ∈ S 는 예측된 신호(RGB 값 처럼)이다. 실제로 2차원에 대해 x의 범위를 [0, 2H]와 [0, 2W]라고 가정한다. 정의된 f_θ에서 각 벡터 z는 함수 f_θ(z,·): X → S, 즉 RGB 값에 좌표를 매핑하는 함수를 나타내는것으로 간주될 수 있다. M^(i)의 H × W feature vector (latent code라고 부름)가 I^(i)의 연속 이미지 영역 (그림 2의 파란색 원)의 2D 공간에 고르게 분포되어 있다고 가정한 후, 그들 각각에 2D 좌표를 할당한다. 연속적인 이미지 I^(i)의 경우, 해당 좌표 x_q의 RGB 값은 다음과 같이 정의된다.

z*는 M^(i)의 x_q로 부터 가까운 거리(Euclidean distance)의 latent code, v*는 이미지 영역에서 z* latent code의 좌표이다. 그림 2를 예로 들자면, 현재 정의에서 z*_11은 x_q에 대한 z*이고 v*는 z*_11에 대한 좌표로 정의된다.

요약하자면, 모든 이미지들에 의해 공유된 함수 f_θ 로, 연속적인 이미지는 2D 영역에서 고르게 퍼져있는 H × W latent code로 보는 2D feature map M^(i) 로 표현된다. M^(i)의 각 latent code z는 연속적인 이미지의 local piece를 나타내며, 이는 자신에게 가장 가까운 좌표 집합의 신호를 예측하는 역할을 한다.
Feature unfolding
M^(i)의 각 latent code에 포함된 정보를 풍부하게 하기 위해서 feature를 unfolding 한다. Unfold M의 latent code는 M^(i)의 3×3 개의 인접 latent code의 concat이다.

M^(i)는 zero-padding 되었다. 이후 모든 연산은 unfold 된 M^(i)를 사용한다.
Local ensemble
식 (2)의 문제는 불연속적인 예측이다. 구체적으로, x_q에서의 신호 예측은 M^(i)에서 인접한 latent code z*를 질의함으로써 행해지기 때문에, x_q가 2D 영역으로 이동할 때, z*의 선택은 갑자기 하나에서 다른 것으로 전환될 수 있다 (인접한 latent code의 다른 선택). 예를들어 그림 2 에서 x_q가 점선과 교차할때 발생한다. z*의 선택이 전환되는 좌표 주변에서는 서로 다른 latent code로 부터 두 개의 무한히 가까운 좌표의 신호가 예측될 것 이다. 학습된 f_θ 가 완벽하지 않는 한, z* 선택이 전환되는 이러한 경계에 불연속적인 패턴이 나타날 수 있다.
그림 2에 나타나는 문제를 해결하기위해 식 2를 다음과 같이 확장 시킨다.
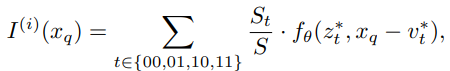
z*_t (t ∈ {00, 01, 10, 11})는 top-left, top-right, bottom-left, bottom-right 부분 공간에서 인접한 latent code, v*_t 는 z*_t의 좌표, S_t 는 t'가 t의 대각(00은 11, 10은 01) 일때 x_q와 v*_t' 사이의 사각형 지역이다. 가중치는 정규화 되어진다. Feature map M^(i)가 외부에 mirror-padded 되는것을 고려하여, 위의 공식이 경계 근처의 좌표에 대해서도 작동하도록 한다.
직관적으로, 이것은 local latent codes로 표현되는 local pieces들이 이웃한 pieces들과 겹치도록 함으로써, 각 좌표에서 독립적으로 신호를 예측하기 위해 4개의 latent code들이 존재하도록 하기 위한 것이다. 이러한 4개의 예측은 질의점과 가장 가까운 latent code의 대각선 대응물 사이의 직사각형 면적에 비례하는 voting with normalized confidences에 의해 병합된다. 따라서 신뢰도는 query 좌표가 가까울수록 높아진다. z*가 전환되는 좌표에서 연속적인 전환을 달성한다. (그림2의 점선)
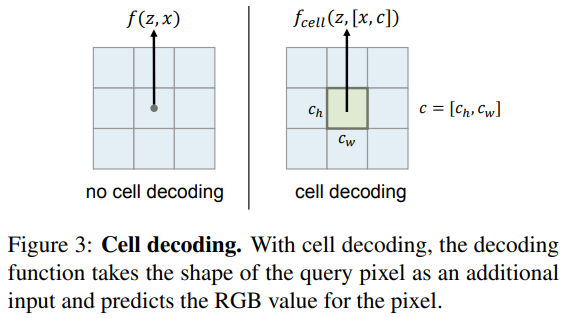
Cell decoding
실제로, LIIF 표현이 임의의 해상도에서픽셀 기반 형태로 제시될 수 있기를 원한다. 원하는 해상도가 주어진다고 가정하면, 간단한 방법은 연속된 표현 I^(i) (x)에서 픽셀 중심의 좌표의 RGB값을 질의하는 것이다. 이것은 이미 잘 작동할 수 있지만, query pixel의 예측된 RGB 값이 최적이 아니라면, 그 pixel 영역의 정보는 중심 값을 제외하고 모두 폐기된다.
이러한 문제를 해결하기 위해, 그림 3과 같은 cell decoding을 사용한다. 식 1을 다음과 같이 다시 재 공식화 한다.
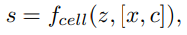
c = [ch, cw]는 query pixel의 높이와 너비의 특정한 두 값을 포함하고 [x,c]는 x와 c의 concat이다. 식 (5)의 의미는 다음과 같이 해석할 수 있다: 모양이 c인 좌표 x에 중심을 둔 pixel을 렌더링 할 경우 RGB 값은 얼마가 되어야 한다. 실험에서 보여줄 것처럼, 추가적인 입력 c를 갖는 것은 주어진 해상도에서 연속적인 표현을 제시할 때 유익할 수 있다.
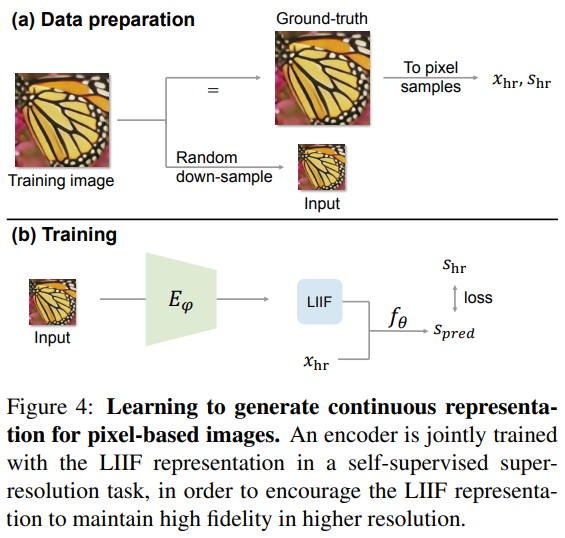
Learning Continuous Image Representation
그림 4에 나타나듯이 이미지의 연속적인 표현을 생성하는 학습 방법을 소개한다. 공식적으로 학습 데이터를 가진 이 작업의 목표는 한번도 보지 못한 이미지의 연속적인 표현을 생성하는것이다.
일반적인 아이디어는 LIIF 표현으로 나타내는 이미지를 2D feature map으로 map 하는 인코더를 훈련한다. 생성된 LIIF 표현이 입력을 재구성할 수 있을 뿐만 아니라, 더 중요한 것은 연속적인 표현으로서 더 높은 해상도를 제시될 때에도 높은 fidelity를 유지해야 한다는 것이다. 그러므로 이 프레임워크를 self-supervised task로 훈련할 것을 제안한다.
먼저, 그림 4에 보여지듯이 단일 훈련 이미지를 예로 든다. 훈련 이미지의 경우, 랜덤 scale로 훈련 영상을 down-sampling하고 입력을 생성한다. 훈련 이미지를 x_hr, s_hr인 pixel 샘플로 표현함으로서 GT를 얻는다. x_hr은 이미지 영역의 픽셀의 중심 좌표, s_hr은 픽셀의 해당 RGB 값이다. 인코더는 LIIF 표현함으로써 입력 이미지를 2D feature map으로 map 한다. x_hr의 좌표는 LIIF 표현에 대한 query로 사용되고 이때, f_θ 는 각 LIIF 표현에 기반한 좌표에 대한 신호(RGB 값)을 예측한다. s_pred를 예측된 신호라고 정의하면, 훈련 loss(l1)는 s_pred와 GT인 s_hr 간에 계산된다.
paper
'딥러닝 논문 리뷰' 카테고리의 다른 글
| ConvNeXt : A ConvNet for the 2020s (0) | 2024.01.16 |
|---|---|
| Single Image Super-Resolution via a Dual Interactive Implicit Neural Network Review (0) | 2023.11.03 |
| A Feature Reuse Framework with Texture-adaptive Aggregation for Reference-based Super-Resolution Review (0) | 2023.09.02 |
| Spatial-Frequency Mutual Learning for Face Super-Resolution Review (0) | 2023.07.31 |
| CrossNet Review (0) | 2023.07.21 |



