
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Reference Super-Resolution
- Super-Resolution
- Graph
- INR
- LIIF
- graph neural network
- Reference-based SR
- Cell detection
- SISR
- Referense Super Resoltuion
- arbitrary scale
- hypergraph
- Zero-Shot sr
- TRANSFORMER
- CrossNet
- ConvNeXt
- session-based recommendation
- implicit representation
- Tissue segmentation
- GNN
- Cityscapes
- DIINN
- Cell-tissue
- ADE20K
- FRFSR
- deep learning
- Feature reuse
- TAAM
- SegFormer
- GNN in image
- Today
- Total
딥러닝 분석가 가리
Online Learning for Reference-Based Super-Resolution Review 본문
"Online Learning for Reference-Based Super-Resolution Review"
Abstract
Online learning은 테스트 단계에서 입력 데이터가 심층 네트워크에 업데이트해서 성능 개선을 도출하는 방법이다. SISR(Single Image Super-Resolution)에서 online learning 방법은 심층 네트워크의 online adaptation을 위해 LR(저해상도) 영상을 사용한다. SISIR 방법과 다른, RefSR(Reference-based SR) 알고리즘은 입력 LR 영상을 개선하는데 유용한 기능이 포함된 HR(고해상도) 참조 영상의 이점을 제공한다. 그로므로 본 논문에서는 RefSR 뿐만 아니라 SISR에도 해당되는, 몇가지 ref 영상을 사용하는 새로운 online learning 알고리즘을 소개한다. 실험결과 제안하는 방법이 RefSR과 SISR 모델에 적용할 수 있으며 성능 또한 개선 시켰다. 심층 분석을 통해서 제안하는 방법이 non-bicubic degradation 커널에 robustness한 것을 제시한다.
1. Introduction
딥러닝 기반의 SISR은 최근 주목할 만한 성과를 보였지만, 훈련할 때 MSE, MAE를 최소화해야 하기 때문에 여전히 blurry 영상을 출력한다. 이러한 문제를 해결하기 위해 GAN이나 perceptual loss를 사용하지만, 종종 reconstruction 성능 저하로 이어진다. 그 이유는 GAN 이 종종 고화질의 영상을 생성하지만, downsampling 중에는 손실된 실제 정보를 복구하지 못하기 때문이다. 이런 손실된 정보를 재구성하기 위해 RefSR이 제안되었다. 이런 연구들은 LR-HR 간의 비슷한 특징을 찾는것이며 그 예로 deformable convolution과 attention 기술이 있지만, 이 기술들은 non-ideal한 방법에서는 좋은 성능을 보이지 못한다. 이를 해결하기 위해 ZSSR(Zero-Shot Super-Resoluton)에 영감을 받아 online learning 기술을 제시한다. 하지만 ZSSR은 large scaling factor인 x3, x4 등으로 SR 할 때는 화질이 저하된다는 단점이 있다. 그러므로 본 논문에서는 online learning을 위해 LR과 HR 참조 영상을 효과적으로 활용해 RefSR 뿐만 아니라 SISR 모델 또한 업데이트 하는 방법을 제안한다.
- 사전에 학습된 SR 모델을 사용해, 입력 LR 영상으로 부터 유사 HR 영상을 생성한다.
- SR 모델의 online learning을 위한 또 다른 기준으로 유사 HR 영상과 downsampled 유사 HR 영상 쌍을 사용한다.
- 요약 하자면 3가지 형태의 LR, Ref, 유사 HR 영상을 활용해 SISR과 RefSR 모델 모두에 대해 online learning을 한다.
- 각 supervision을 개별적으로 사용할 뿐만 아니라 online learning을 위해 각 supervison의 조합도 사용한다.
- 그 결과, 제안한 방법은 ZSSR과 비교해서 online adaptation 중 더 많은 영상의 이점을 얻을 수 있다.
본 논문에서 제안하는 방법의 기여는 다음과 같다.
- Supervison을 위한 다양한 데이터 쌍을 가진 RefSR을 위한 online learning 방법을 제안한다.
- SISR 모델을 위한 3가지 방법, RefSR 모델을 위한 4가지 방법을 제시한다.
- 제안하는 방법은 매우 간단하지만 효율적이고, SISR과 RefSR을 밀접하게(seamlessly) 결함할 수 있다.
- 제안하는 방법은 ref와 입력 영상 사이의 유사성에 크게 영향을 받지 않고 일관된 성능 향상을 보여준다.
2. Methods
2.1 Online Learning
Online learning에서 가장 중요한 점은 테스트 단계에서 주어진 입력 데이터를 어떻게 활용하느냐 이다. Online learning은 영상에서의 self-similarity(자가 유사성)를 활용한다. Interanl feature를 학습하는 online learning의 특성을 사용해, 비슷한 특징을 가진 HR ref 영상을 처리하고, 테스트 영상을 복구하여 성능을 향상 시키는데 사용한다.
RefSR 문제점의 경우 LR, Ref 영상 두가 종류가 입력으로 들어오기 때문에 online learning이 더 중요하다. 그러므로, LR과 Ref 등의 다양한 영상으로 부터 train-input X와 train-target(supervison) Y를 구성하기 위해 다양한 방법을 개발한다. 비록 목적이 RefSR의 문제점을 해결하는것 일지라도, RefSR 뿐만 아니라 테스트 시 SISR 모델을 훈련하는데 사용할 수 있는 데이터 페어인 D를 구성한다.
2.1.1 SISR Model
- SISR 모델은 훈련하기 위해 입력 X와 supervison Y로 구성된 데이터 쌍 D_s를 요구한다.
- D_s는 D(LR), D(Pse), D(Ref)로 구성된다.
- D(LR)은 downsampled LR영상과 입력 LR 영상으로 구성되어 있다. D(LR) = {X : LR↓, Y : LR}
- ZSSR과 같은 SISR의 self-similarity를 이용하기 위해 일반적으로 사용되는 구성이다.
- D(Pse)는 SR 모델(Pφ (·))로부터 얻어진 유사 HR 영상으로 구성된다.
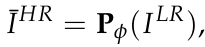
- φ는 pre-trained network 파라미터이다.
- 훈련 샘플 쌍을 구성하기 위해 유사 HR 영상을 dwonsampling 한다. D(Pse) = {X : 유사 HR↓, Y : 유사 HR}
- D(LR), D(Pse)와 비슷한 ref 영상인 D(Ref)를 사용한다.
- D(Ref)는 downsampling된 ref 영상과 원본 ref 영상으로 구성된다. D(Ref) = {X : Ref↓, Y : Ref}
- 테스트 단계에서 획득한 LR, Pse, Ref 3개의 데이터 쌍을 사용해 SISR모델의 pre-trained 파라미터인 θ_s를 다음 손실함수를 최소화 하는것으로 업데이트 한다. (x와 y는 D_s의 X, Y로 부터 추출된 patch(부분))

- 앞서 말한 데이터 쌍들은 개별적으로 혹은 결합해서 사용할 수 있다.
2.1.2 RefSR Modle
- RefSR을 훈련시키기 위해, 입력 X, ref R, supervision Y로 구성된 D_r 쌍을 사용한다.
- 추가 입력 R 덕분에 SISR모델 보다 더 다양한 데이터 쌍을 구성할 수 있다.
- D_r은 D(LR), D(Pse), D(Ref1), D(Ref2)로 구성된다.
- D(LR)은 downsample된 LR 영상, ref 영상, 입력 LR 영상으로 구성된다. D(LR) = {X : LR↓, R : Ref, Y : LR}
- D(Pse)도 D(LR)처럼 비슷하게 구성된다. D(Pse) = {X : 유사 HR↓, R : Ref, Y : 유사 HR}
- Downsampled ref 영상인 Ref↓과 Ref 영상을 X, Y로 사용할수 있다. D(Ref1) = {X : Ref↓, R : LR, Y : Ref}
- D(Ref1)의 R인 LR을 유사 HR로 변형해서 사용할 수 있다. D(Ref2) = {X : Ref↓, R : 유사 HR, Y : Ref}
- 위의 데이터 쌍들을 사용해, pre-trained RefSR 모델인 RefSR θ_r (·)의 네트워크 파라미터인 θ_r을 업데이트 한다.

- x, r, y는 데이터 D_r의 X, R, Y에서 추출한 patch 이다.
- SISR 모델과 유사하게, 데이터 쌍은 개별적으로 사용되거나 online learning을 위해 결합될 수 있다.
Online learning을 위한 SISR, RefSR 모델의 데이터 쌍들을 요약하자면 표 1과 같다.

2.2 Inference
테스트 단계에서 SISR 또는 RefSR 모델의 업데이트된 파라미터를 사용해, 최종 super-resolved 영상을 추정한다.

RefSR과 다르게 SISR 모델은 online learing 단계에서 ref 영상을 사용해 업데이트되지만, ref 영상을 최종 추론에 사용안한다.
3. Experiments
3.1 Implementation Details
- SISR, RefSR -> Dataset : CUFED(11,871장), 모델을 pre-trained 위한 x4 upscaling
- SISR model : SimpleNet, RCAN(reduce res-block 20 to 6), EDSR(reduce res-block 32 to 16, channel 64)
epochs 100, batch-size 32, D_s 모두 사용하여 훈련한다. - RefSR model : SSEN(batch-size 32), TTSR(batch-size 9), epochs 200
- Online Learing -> Dataset : CUFED5, 126개의 그룹, 각 그룹당 HR 영상과 5개의 Ref 영상을 가지고 있다.
- 영상들은 random crop(128x128), rotation, flip로 증강시킨다.
- learning rate : 1x10^-4, optimizer : Adam, lr schedule : loss 값이 더 이상 감소하지 않을때 0.1을 곱한다,
deep learning framework : pytorch, os : Ubuntu 16.04, GPU : RTX2080
3.2 Experimental Results
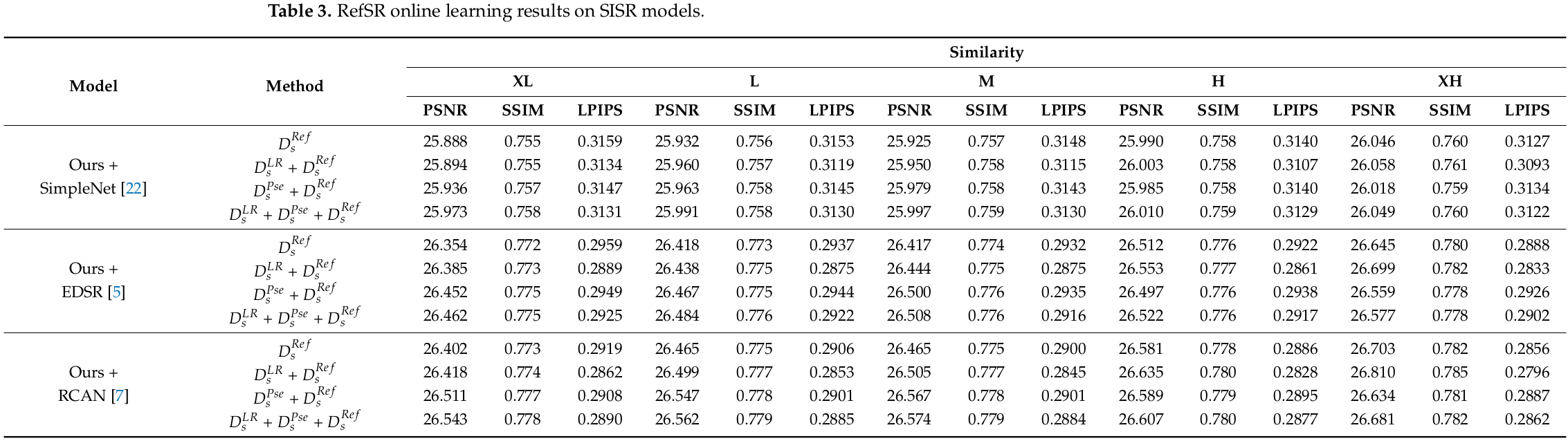
모든 실험은 기본 모델을 얻기위해 기존의 구성을 따라 SISR, RefSR 모델을 훈련시키고 online learing을 적용시킨다. 모든 모델은 CUFED5로 검증되고 검증방법은 PSNR, SSIM, LPIPS(LPIPS값은 VGG 모델로 측정)을 사용한다. SISR online learning 결과는 표 2에 나타난다.
- D(LR)만 사용한 online learning은 D(LR)의 크기가 너무 작아(30x20) 영상의 정보량이 적어 성능을 저하 시킨다.
- 반대로 D(Pse)를 online learning에 사용하면 HR의 정보를 포함하고 있기 때문에, 일관적으로 성능을 향상 시킨다.
- D(LR), D(Pse)를 모두 online learning에 사용한 결과는 D(Pse)의 HR 정보를 유지하면서 D(LR)의 self-similarity의 이익을 효과적으로 얻을 수 있다.

SISR 모델을 사용한 RefSR online learing의 결과는 표 3, RefSR 모델을 사용한 RefSR online learning의 결과는 표4, 그리고 표 2, 3, 4에 대한 정성적 결과는 그림 1과 같다.
- RefSR online learning에서 baseline model은 항상 성능이 개선되었다.
- D(Ref)가 D(Pse)는 사용할 수 없는 real high-frequency를 포함하기 때문이다.
- SISR 모델을 사용한 RefSR online learning에서는 D(LR), D(Ref)를 모두 사용했을 때 성능이 가장 좋다.
- RefSR 모델을 사용한 RefSR online learing의 결과는 D(Pse), D(Ref2)를 사용한 결과가 가장 높다.
- 그림 1은 모든 실험에 대한 정성적 결과로 f, k가 기본적인 e, j 보다 우수한 성능을 보인다.


3.3 Empirical Analyses
Reference Similarity
Online learning에서 ref 영상의 유사성에 대한 효과를 분석한다. CUFED5는 유사도에 따라 5개의 영상을 제공하는데, SISR, RefSR model 모두 유사도가 높을수록 성능이 향상되었고, 유사도가 가장 높은 XH 영상을 사용했을때, 가장 높은 결과를 보였다. 이는 XH ref 영상이 LR 영상이 잃은 세부사항들인 large amount of real high-frequency들을 포함하고 있기 때문이다. 그러므로, XH ref 영상을 사용한 online learning은 baseline model을 더 robustness 하게 만들 수 있다.
Pseudo HR vs LR for Sueprvision
SISR 모델을 사용한 RefSR online learing에서 두가지 결과인 D(LR) + D(Ref)와 D(Pse) + D(Ref)의 결과를 비교한다. 유사도가 높을수록(XH, H) D(LR) + D(Ref)의 결과가 더 높았고, 그렇지 않으면(M, L, XL) D(Pse) + D(Ref)의 결과가 더 높았다. 조사한 바와 같이 baseline network가 XH, H ref 영상으로 부터 관련성이 높은 영상을 학습할 수 있기 때문이다. 하지만, 관련없는 ref 영상으로 인해 D(Ref)의 역할이 약화되는 반면, 결함된 데이터인 D(LR), D(Pse)의 역할은 상대적으로 강조된다. 그러므로, D(Pse)와 결합된 D(Ref)의 성능 향상은 self-supervision인 D(LR)과 비교했을때 pre-trained model인 D(Pse) 덕분에 우수하다. 한편, RefSR 모델을 사용한 RefSR online learning은 유사 HR로 fine-tuning한 결과가 LR로 fine-tuning한 결과보다 좋다. 다시 말하면, 모든 similarity levels 에서 D(Pse) + D(Ref2)가 D(LR) + D(Ref1)보다 더 나은 성능을 보였다. 유사 HR이 LR 보다 Ref 와 비교적 유사한 해상도를 가지기 때문이다. 그래서, ref 영상의 정보와 더 쉽게 정렬하고 결합할 수 있다.
Non-Bicubic Degradation
RCAN(SISR), TTSR(RefSR)을 사용해 non-bicubic로 영상을 저하시킨 LR영상으로 제안하는 방법을 검증한다. x4 줄이기 위해 MZSR에 제시된 방법을 사용한다. 표 5에서 bicubic degradation으로 pre-train된 RCAN과 TTSR은 inferrior한 SR 결과를 생성하는데, non-bicubic degradation 밥업을 학습하지 못했기 때문이다. 하지만 만약, non-bicubic degradation이 online learing 동안 주어진다면 RCAN과 TTSR모델은 제안된 online learning 으로 상당히 좋은 성능을 낼 수 있다. 게다가, RCAN과 TTSR은 random kernel로 downsampling해서 얻은 각 입력을 사용해 수행하는 bline manner로 인해 online learning을 향상시킬 수 있다. 그림 2는 기존의 방법과 제안한 방법을 비교한 non-bicubic 정성적 결과 이다. 그로므로 결론은 제안하는 방법이 degradation kernel의 인식과 상관없이 어떠한 종류의 degradation에도 잘 수행한다.


4. Conclusions
- 테스트 단계에서 네트워크 적응을 위해 다양한 종류의 이터를 활용하는 RefSR을 위한 online learning 알고리즘을 제안했다.
- 제안된 방법은 어떠한 네트워크 파라미터를 추가하지 않고도 SISR과 RefSR에서 상당한 성능 향상을 보였다.
- 다양한 유형의 데이터 쌍은 LR, 유사 HR, Ref 영상을 사용한다.
- 각 데이터 쌍의 역할을 ref 영상의 서로 다른 유사성의 수준을 검증한다.
- 제안된 방법의 실험결과는 유효성, 효율성, 그리고 다목적성을 보여준다.
paper
'딥러닝 논문 리뷰' 카테고리의 다른 글
| Non-local Neural Networks Review (0) | 2023.02.19 |
|---|---|
| RZSR with Depth Guided Self-Exemplars Review (0) | 2023.02.02 |
| TTSR Paper Review (0) | 2023.01.17 |
| Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution Paper Review (0) | 2023.01.14 |
| MZSR Paper Review (1) | 2023.01.11 |



