
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Tissue segmentation
- TRANSFORMER
- DIINN
- Super-Resolution
- FRFSR
- GNN in image
- graph neural network
- arbitrary scale
- Zero-Shot sr
- SISR
- TAAM
- ADE20K
- Cell-tissue
- GNN
- Graph
- Cityscapes
- Reference Super-Resolution
- Referense Super Resoltuion
- ConvNeXt
- INR
- deep learning
- Reference-based SR
- implicit representation
- LIIF
- session-based recommendation
- CrossNet
- SegFormer
- hypergraph
- Feature reuse
- Cell detection
- Today
- Total
딥러닝 분석가 가리
Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution Paper Review 본문
Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution Paper Review
AI가리 2023. 1. 14. 12:27"Robust Reference-based Super-Resolution
with Similarity-Aware Deformable Convolution"
Abstract
본 논문에서는 RefSR(reference-based SR) 작업을 위해 SSEN(Similarity Search and Extraction Network)을 참조하는 새롬고 효율적인 referenced feature extraction 모듈을 제안한다.
제안된 모듈은 SISR(Singe Image Super-Resolution)의 성능을 향상시키기 위해 참조 이미지(reference image) aligned relevant feature(정렬된 관련있는 이미지?)를 추출한다.
Brute-force searches 혹은 Optical flow estimations를 사용하는 Convolutional 알고리즘과 다르게, 제안된 알고리즘은 어떠한 추가적인 supervision이나 heavy한 연산 없이 end-to-end 학습이 가능하고 단일 네트워크 foward를 해서 가장 알맞은(best match) 예측을 할 수 있다.
- Brute-force search : 가능한 모든 경우의 수를 모두 탐색하면서 요구조건에 충족되는 결과만을 가져오는 기법
- Optical flow estimations : 영상내의 객체의 움직임을 각 픽셀별로 추정하는 기법
게다가 제안된 모듈은 best matching position 뿐만 아니라 best match의 관련된것 또한 알 수 있다.
이 모듈은 제안한 알고리즘을 관련성 없는 reference image가 주어졌을때에도 여전히 robust 하게 만들고, 기존의 RefSR 방법을 사용했을때 서능 저하의 주요 원인을 극복했다.
게다가 제안한 모듈은 reference image가 없더라도 self-similarity SR에 사용할 수 있다.
실험 결과에서는 양적으로나 질적으로나 이전의 연구보다 우수한 성능을 보여준다.
1. Introduction
악명 높은 어려움에도 불구하고 중요성과 실용성 때문에 많은 관심을 받은 SISR은 LR(Low-Resolution)이미지로 부터 HR(High-Resolution)이미지를 재구성 하는것이 목적이다.
PSNR(Peak Signal-to-Noise Ratio)을 높이기 위한 optimization 과정은 GT와 예측된 HR 이미지 사이의 MSE와 MAE를 최소화 한다.
이러한 알고리즘은 가능한 평균값이나 중앙값으로 solution을 생성해서 고주파의 details이 부족하고 저 레벨의 흐릿한 HR 이미지를 생성한다는 한계가 있다.
현실적인 HR 이미지를 얻기 위해서는 HR과 재구성된 영상의 높은 유사성을 요구한다.
- Perceptual loss 혹은 GAN 기반의 알고리즘은 SR에서 더 나은 출력을 보여줬다.
- Adversarial learning은 생성자가 판별자와 경쟁해 저 현실적인 이미지를 생성하도록 도와준다.
- 이러한 알고리즘들은 시각적으로 좋은 영상을 출력하더라도, 원본 HR 이미지를 재구성했다고 확실하게 보장할수 없다.
- 이로인한 PSNR 저하가 발생할 수 있다.
- 이러한 문제를 해결하기위해 몇가지 방법들은 GT와 같거나 더 현실적인 SR 출력을 위해 몇가지 정보를 더해준다.
SISR에서 RefSR(rich texture를 생성하기 위해 비슷한 콘텐츠를 포함하고 있는 external Ref를 사용해 HR 이미지를 생성하는것이 목적)이 급격하게 주목받고있다.
- Downsampling 과정에서 원본의 high-frequency information을 손실하기 쉽기 때문에 GT의 정확한 high-frequency detail을 재구성하는거는 매우 어렵다.
- 이러한 high-frequency details의 경우 유사한 콘텐츠를 명시적으로 제공하는것이 가짜 텍스처를 생성하는 것에 비해 더 합리적인 접근 방식이다.
- 많은 SR 알고리즘은 reference image(video frame, web image searches, different view point에서 획득할수 있는)가 input과 페어인 RefSR의 특수한 경우로 볼 수 있다.
- 일반적인 RefSR 알고리즘은 예상치 못한 성능 저하를 피하기 위해 비슷한 콘텐츠가 포함되어야 한다는 한계가 있다.
- RefSR 알고리즘의 가장 요구되는 행동은 LR과 Ref 사이의 유사성을 알아야 하는것이다(Ref 이미지와 무관한것에 영향을 받지 않는).
최근 연구인 video SR과 RefSR 방법에 영감을 받아 RefSR을 위한 새로운 reference feature 추출 모듈을 제안한다.
- Deformable Convolution을 사용한 SSEM(Similarity Search and Extraction Network) 기반의 새로운 end-to-end로 훈련가능한 reference feature 추출 모듈을 제안한다.
- 제안한 방법은 상관없는 reference가 주어져도 어떠한 PSNR 저하가 없어 robustness 하고 adaptiveness를 보여준다.
- 제안한 방법은 RefSR뿐만 아니라 reference 이미지를 사용할수 없는 경우 self-similarity에 사용할수 있다.
그림 1에서는 제안하는 방법의 결과를 보여준다.

2. Similarity Search and Extraction Network
2.1 Network Architecture
RefSR은 입력으로 LR 이미지와 HR Ref 이미지가 주어졌을때 HR 이미지를 추정하는것이 목표이다.
Feature aligning 기능을 가진 Deformable Convolution에 영감을 받아, 입력과 Ref feature 사이의 비슷한 contents를 매칭하는것과 aligned form에서 Ref feature을 추출하는 통합 재구성 과정을 RefSR 문제라고 공식화한다.
Ref feature 모듈인 SSEN의 도움으로 ref 이미지로부터 HR 정보(high-frequency texture)로 전송할 수 있는 end-to-end 형식의 통합된 프레임워크를 제안한다.
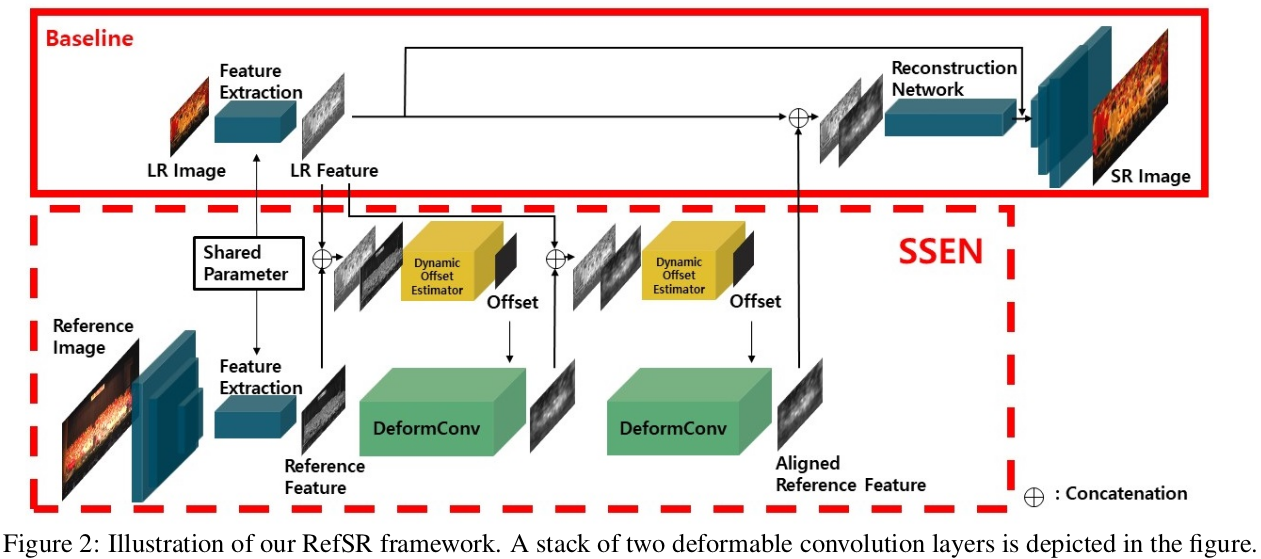
- SSEN의 구조는 그림 2와 같다.
- 이미지의 Input과 Ref 페어는 HR 이미지로 재구성되기 위해 프레임워크로 들어가고, SSEN은 어떠한 flow supervision(label?)도 없이 픽셀 공간상의 contents를 매칭하며 aligned form의 ref 이미지의 feature를 추출한다.
- Deformable convolution layer를 순차적인 방식으로 계속 쌓여 receptive field가 커진다는 점에 주목해 순차적 접근방식으로 변형 가능하게 설계한다.
- Deformable convolution layer는 3개의 층을 가지는것이 최적의 구조이다.
- RefSR은 전체 이미지 내에서 유사한 영역을 검색할 것으로 예상되어, a large receptive field가 가장 중요한 문제이다.
- 이 제안은 offset 정보를 전파하기 위해 multi-scale 구조와 non-local block이 채틱된다.
- 제안하는 모듈은 deformable convolutional kernels에 대한 offset을 추정하면서 extremely large receptive fidel로 픽셀 또는 패치 레벨 매칭을 부드럽게 수행한다.
2.2 Stacked Deformable Convolution Layers
Deformable convolution은 geometric한 변형을 모델링 하는 CNN의 능력을 향상시키기 위해 제안되었다.
- 이것은 defromed sampling grid를 사용해 픽셀 포인트의 sampling을 도와주는 학습가능한 offset으로 훈련된다.
- Modulation(변조?) scalar로 sampling kernel의 dynamic한 weights를 학습할수있는 deformable convolution을 유사성 탐색과 추출 단계에서 사용한다.
- Modulated deformable convolution의 modulation scalar는 offset과 함께 spatially-variant(공간적으로 제한된) kernel을 만드는것을 배운다.
- Deformable convolution 수행 식은 식 1과 같다.
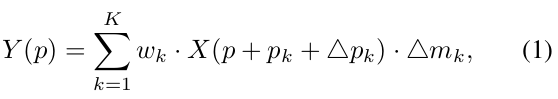
- X는 입력, Y는 출력, k와 K는 해당 번째에 해당되는 kernel weights 이다.
- w_k(k번째 kernel weight), p(중심 지수(indices of the center)), p_k(k번째 고정 offset) 그리고 △p_k(학습가능한 k번째 위치에 있는 offset) 이다.
- △m_k는 modulation scalar로 관련성 있는 weight 학습으로 RefSR에서 cluttered(복잡하거나) irrelevant(관련없는) 입력 데이터에 대한 대응되는것을 robustly하게 추출할 수 있다.
SSEN은 그림 2에서와 같이 DeformConv(Deformable Convolution layer)를 포함하고 있다.
- 제안된 순차적으로 쌓인 deformconv는 더 큰 receptive field에 feature를 aligning 하기위해 ref 이밎로 부터 더 많은 위치를 샘플링 한다.
- SSEN은 dynamic offset estimator로 부터 제공된 offset에 따라 각 레이어의 입력 feature에 ref feature를 점진적으로 aligns 한다.
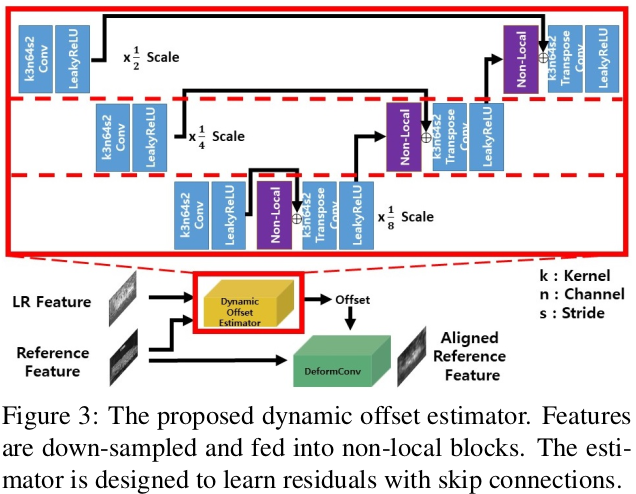
2.3 Dynamic Offset Estimator
위치가 가까운것 부터 먼것까지의 유사성을 capture 하는데는 offset이 dynamic하게 배울 수 있다.
-> offset은 다양하고 먼 거리까지 능동적으로 도달해 넓은 영역을 커버할 수 있어야 한다.
Ref feature와 input feature는 concat되어 dynamic offset estimator로 입력된다. Dynamic offset estimator는 그림 3과 같다.
- Optical flow extimations에서 일반적으로 multi-scale philosophy를 따른다.
- Concat된 input은 offset이 예측할때 multiple levels of scales가 고려되어지며 3번의 down-sample 한다.
- 먼 거리에 있는 relevant features를 효율적으로 가져오기위해(to localize) dynamic offset estimator에 non-local blocks을 사용한다.
- Non-local 연산은 내부 또는 상호간의 featuredml 전역 상관관계를 capture하고 크고 작은 displacement(변위)를 다루기 위해 극도로 큰 receptive field를 사용해 dynamic offset을 예측하는데 도움을 준다.
- Dynamic offset을 추정하는데 3개의 non-local blocks을 사용해 feature가 각 규모의 attention에 따라 증폭된다.
- Down-sampling을 고려하는 non-local 수행 과정은 픽셀 단위의 유사성 보다 패치 단위의 유사성을 측정하는것을 고려할 수 있다.
Non-local block의 연산은 다음 식과 같다.
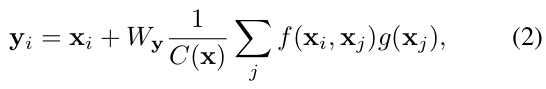
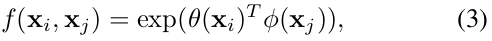
- x : Input, y : Ouput, i : index의 출력 position, j : index의 all possible position
- W_y : weight matrix, C(x) : normalization factor, f(·), g(·) : pair-wise 연산과 선형 임베딩 함수
- θ(·), φ(·) : 선형 임베딩 함수
2.4 RefSR and Self-Similarity SR Framework
RefSR은 batch Normalication이 없는 residual blocks으로 구현되어 SSEN은 존재하는 어떠한 SR구조에도 쉽게 붙일수 있다.
- SSEN에서 추출된 ref feature는 mid-level의 input feature와 융합된 후, upsample 되어지기전에 reconstruction 네트워크에서 추가로 처리된다.
- Global skip conncection 되어진 Input과 Output 사이의 layer는 네트워크가 residual feature를 학습하는것에 초점을 두는것을 보장하기위해 채택된다.
- 모든 feature manipulations(조작)은 효율적인 연산을 위해 intput 공간의 차원을 1/4 크기로 실행한다.
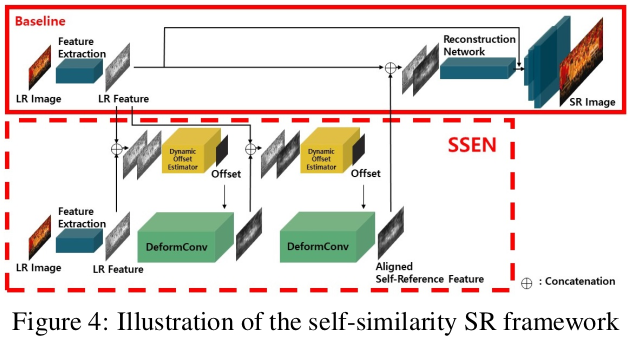
- Self-Similarity SR : 만약 적절한 ref 이미지가 없다면 SSEN은 self-reference manner로 사용할 수 있다.
- 그림 4를 보면 참조 되어진 feature는 같은 input 이미지에서 추출 되어진다.
- 이 경우 제안된 모듈은 reconstruction loss를 최소화 하는데 도움을 줄 수 있는 입력 이미지로부터의 단서를 이용하는데(to exploit cues) 사용될 수 있다.
- Reconstruction 네트워크로는 RCAN을 사용한다.
2.5 Training Obejctive
Objective function으로 Charbonnier penalty 함수를 사용한다.
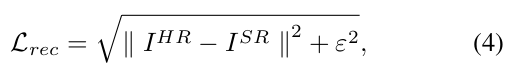
- ε 은 1e^-6 이다.
이미지를 좀더 현실감있게 생성하기 위해 PatchGAN을 사용한다.
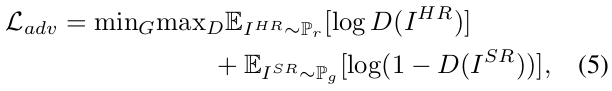
- G는 I_SR을 생성 해주는 생성자, D는 판별자 이다.
- P_r은 real data distribution, P_g는 model distribution
3. Experimental Results
3.1 Dataset
CUFED를 사용한다(Ref SR을 훈련시키기 위해). CUFED5를 사용한다(RefSR을 평가하기 위해).
- RefSR은 ref image가 입력된 LR image와 유사한 내용을 포함하고 있다는 가정이 있다.
- 훈련 과정 중 데이터를 증강시키기 위해 랜덤하게 90도 회전한다.
Self-similarity SR을 위해 DIV2K 데이터를 사용한다. 평가를 위해 Urban100, Set5, Set14 그리고 B100 데이터를 사용한다.
- Patch 크기를 192X192로 random corrping, 랜덤 90도 회전하여 훈련 데이터를 증강한다.
3.2 Training Details
- 모든 실험에서 LR과 HR 이미지의 scaling factor는 X4로 설정한다.
- learning rate는 1e^-4, optimizer는 Adam, 딥러닝 프레임워크는 Pytorch, GPU는 NVIDIA 1080Ti를 사용한다.
- L_adv를 사용한 네트워크 훈련을 위해, 처음에는 L_rec만을 사용해서 네트워크를 훈련하고 training objective에 GAN loss를 붙여서 네트워크를 fine-tune 한다.
- 네트워크를 100K번 반복, batch size는 32, cosine learning rate schedule(γ = 0.9)를 사용한다.
3.3 Quantitative and Qualitative Evaluations
RefSR 제안한 Ref SR 방법의 성능을 보여주기 위해 GAN 기반의 SISR과 RefSR 방법 정성적 정량적 결과를 비교한다.
- 그림 5에서 보여지듯이 다른 방법들과 비교했을때 제안한 방법의 visual quality가 가장 좋다.
- 거기다 제안한 방법의 결과는 잡영이 적고, 선명하며, GT와 유사도가 가장 높다.

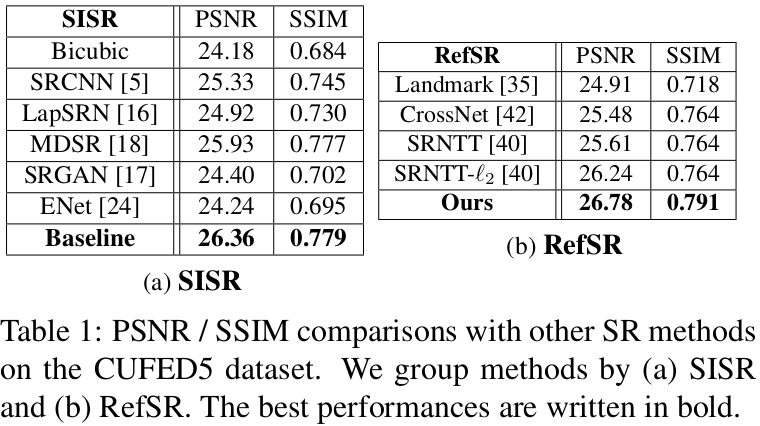
제안한 방법과 기존의 SISR, RefSR을 정량적 결과인 PSNR, SSIM을 비교해 표 1에 나타난다.
- 모든 방법들은 CUFED 데이터로 훈련되고 CUFED5로 테스트 한다.
- 제안한 방법의 PSNR이 이전의 모든 방법들 보다 높은 차이를 보이며 가장 좋은 결과를 보인다.
- 가장 좋은 결과를 보인 이유는 ref image로 부터 정보를 받았기 때문이다.
Self-Similarity SR SISR 방벙과의 공평한 비교를 위해 SSEN과 비교한다.
- 그림 6은 SSEN의 유무에 따른 Urban100으로 테스트한 정성적 결과이다.
- 제안한 방법이 성공적으로 먼 pixel에서 finer texture(더 미세한 텍스처)를 전송해 구조화되고 recurring(반복적인)한 details을 복구한것을 확인한다.

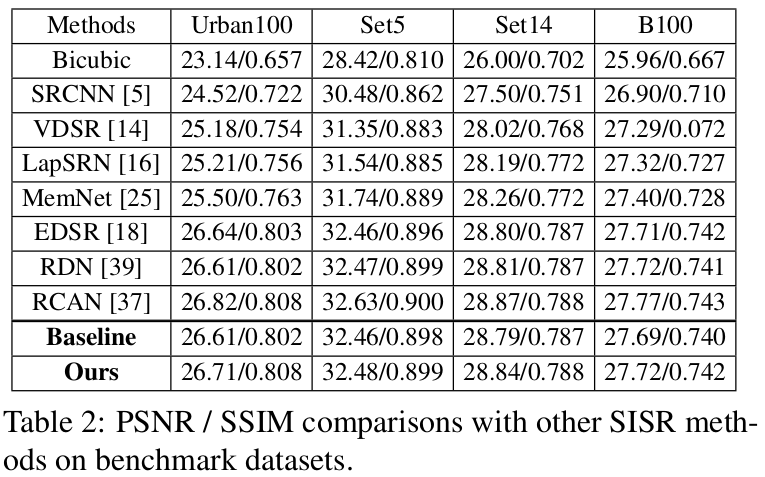
표 2에서는 다른 SISR 방법들과의 정량적 결과를 비교한다.
- 제안한 모듈의 훈련 과정 도중 SSEN을 붙여 선응향상을 확인해 제안한 모듈이 효율적인것을 입증한다.
- RCAN보다는 PSNR이 약간 낮았지만, Urban100 데이터에서 PSNR이 0.1 향상된것을 확인한다.
- 이것으로 SSEN이 self-similarity SR에서 효율적인것을 확인한다.
3.4 Ablation Studies
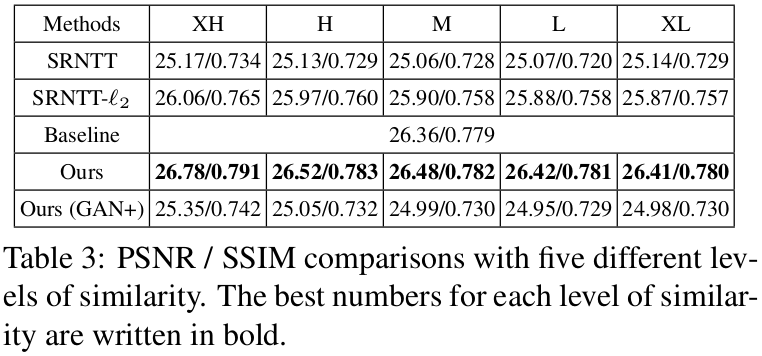
Robustness to Irrelevancy 제안한 방법과 SRNTT의 ref image를 robustness와 irrelevancy로 비교해 표 3에 나타난다.
- 5가지 similarity levels인 XH(very-high), H(high), M(middle), L(low), XL(very-low) 유사성을 비교한다.
- Perceptual(지각적) 품질 중심의 훈련 조건에서 제안한 방법이 가장 높은 유사성을 보인다.
- 제안된 방법과 간을 같이 사용할때 L_rec와 L_adv의 weight를 조절하면 similarity levles는 향상될 수 있다.
- SRNTT-l2 와 비교했을 땐 제안된 방법이 모든 부분에서 robustness함을 보인다.
- 어떠한 ref image가 주어지더라도 제안된 방법이 가장 robustness함을 보인다.
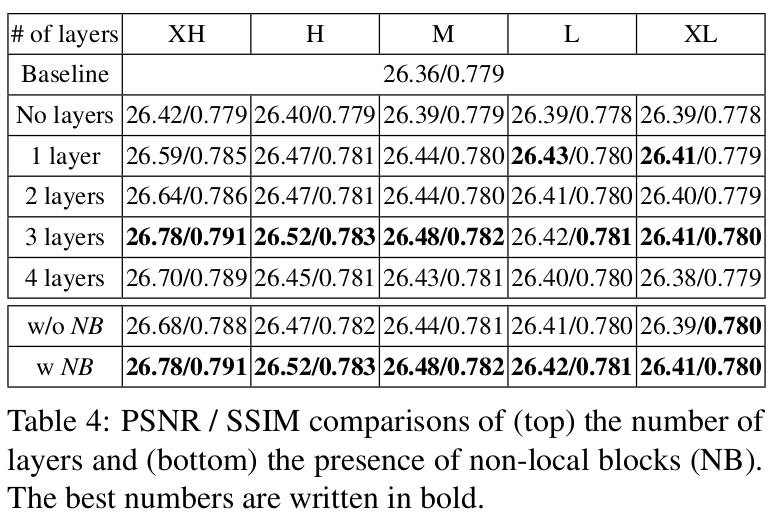
Number of Deformable Convolution Layers, Effect of Non-Local Block 표 4에서는 가장 최적화된 deformable conv layer의 개수와 non-local block의 유무에 대한 결과를 보여준다.
- 3개의 layer를 쌓았을때 가장 최적의 성능을 보여주는것을 확인한다.
- Baseline과 비교했을때 오직 한개의 deform conv를 사용해도 XH에서 0.23dB(PSNR)상승했고, Deform conv를 사용하지 않아도 조금 상승한것을 볼수 있다.
- 각 layer의 출력 feature는 alignment 수준이 다르기 때문에, 각 deform conv에 skip connection을 추가하는것은 부적절해서 네트워크를 더 깊게 모델링 하는것은 훈련을 더 어렵게 만들수 있다.
- Non-local block이 있는것이 없는것 보다 상당히 높은 결과를 보여준다.
- 이것은 non-local block이 전역적 context와 장기적 의존성을 추정하는데 필요한 각 특징의 상관관계를 capture하는데 도와주는것을 암시한다.
- Non-local block을 사용하지 않으면 XH 수준에서 PSNR 성능이 0.1dB 낮아진것을 확인할수 있다.
Visualization of Offset 제안한 방법에서의 유사성과 관련성이 있다는것을 검증하기 위해 offset을 시각화해 그림 7에 나타낸다.
- Ref image 픽셀에 모든 sampling을 시각화 한다(3개의 3X3 deform conv를 가져 9^3rodml sampling point가 있다).
- Originally aligned regions에 있는 sampling point는 출력 pixel 위치 근체어 군집화 되는 경향이 있다.
- 반면에 misaligned area의 sampling 위치는 receptive field를 넓힘으로써 분열되는 경향이 있다.
- 넓어진 receptive field, SSEN은 input image와 ref image사이 pixel 간의 best matching 페어를 찾으려고 시도한다.
- Self-similarity SR의 경우 input과 ref image는 이미 align 되어져 있어 samping point는 유사한 영역 또는 구조물을 따라 분산된다.

Computation Time x4 SR을 진행할때 제안한 방법과 다른 방법들 간의 연산 시간을 나타낸다.
- PatchMatch 86.3s, SS-Net 105.6s, SRNTT patch matching 과정은 9.053s이고 재구성은 2.909s 이다.
- 제안된 방법은 patch matching 과정 없이 효율적인 feature alignment 능력으로 인해 0.95s 소요된다.
4. Conclusion
- 본 논문에서는 ref feature 추출 모듈인 LR feature와 관련된 aligned ref image로 부터 특징을 추출하는 SSEN을 제안한다.
- 제안된 방법은 첫번째 end-to-end Ref SR 방식으로 많은 연산량 혹은 명시적 flow 추정을 필요로 하지 않는다.
- 제안된 방법은 다른 방법들 보다 robustness하고 ref image가 주어지지 않았을때 self-similarity SR에 사용할 수 있다.
- Long distance similarity issue를 사용하기 위해, multi-scale 구조와 wide range of offset을 예측하는 dynamic offset estimator에 non-local block를 사용한다.
- 실험적 결과는 다른 방법들에 비해서 정성적, 정량적 모두 좋은 성능을 보여 SotA를 달성한다.
Paper
'딥러닝 논문 리뷰' 카테고리의 다른 글
| RZSR with Depth Guided Self-Exemplars Review (0) | 2023.02.02 |
|---|---|
| Online Learning for Reference-Based Super-Resolution Review (0) | 2023.01.31 |
| TTSR Paper Review (0) | 2023.01.17 |
| MZSR Paper Review (1) | 2023.01.11 |
| Zero Shot SR review (0) | 2023.01.03 |



