
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- session-based recommendation
- Cell-tissue
- Zero-Shot sr
- SegFormer
- Referense Super Resoltuion
- GNN in image
- SISR
- arbitrary scale
- CrossNet
- Graph
- Cityscapes
- Cell detection
- ADE20K
- hypergraph
- INR
- deep learning
- graph neural network
- FRFSR
- Tissue segmentation
- Reference Super-Resolution
- implicit representation
- ConvNeXt
- LIIF
- TAAM
- Super-Resolution
- DIINN
- Reference-based SR
- GNN
- Feature reuse
- TRANSFORMER
- Today
- Total
딥러닝 분석가 가리
MZSR Paper Review 본문
Meta-Transfer Learning for Zero-Shot Super-Resolution
Abstract
CNN은 large-scale external smaples를 사용한 SISR(Single Image Super Resolution)에서 좋은 성능을 보였다.
External 데이터셋에 기반한 성능은 뛰어날 지라도, specific image의 internal information을 알수 없고, supervised에서 경험한 특정한 조건의 데이터에만 적용할 수 있다.
이러한 문제를 해결하기위해 ZSSR(Zero Shot Super-Resolution)이 제안되었지만, 추론시간이 길다는(몇천번의 gradient 업데이트가 필요) 단점이 있다.
본 논문에서는 MZSR(Meta-Transfer Learning for Zero-Shot Super-Resolution)을 제안한다.
- Internal learning을 위한 일반적인 initial parameter을 찾는것에 기반한다.
- External과 internal 정보 둘다 사용하고 추론단계에서 한번의 gradient update를 진행하지만 상당히 좋은 결과를 얻을 수 있다(Figure 1).
- MZSR은 주어진 이미지의 condition에 빠르게 적응하고, large spectrum of image condition에 적용이 가능하다.

1. Introduction
LR 이미지에 상대되는 그럴듯한 HR 이미지를 찾는 SISR은 low-level vision area에 어려운 문제점이 있다.
최근 CNN 기반의 SISR은 많은 연구가 진행되었고 bicubic downsampling 한 데이터셋에서 좋은 성능을 보였다.
하지만 real-world에서의 LR 이미지는 downsampling kernels과 noise와 거리가 있고, 최근 방법들을 사용하면 원하는 결과와 다른 artifact를 생성하고 도메인 격차로 인해 좋지않은 결과를 보인다.
게다가 파라미터와 메모리 오버헤드는 실제 어플리케이션에 사용하기에 너무 크다는 단점이 있다.
또한 단일 이미지 내에서 internal recurrence of information인 multi-scale과 non-local self-similarity는 strong natural image priors중 하나이다.
그러므로 이것은 이미지 복원 작업인 영상 노이즈 삭제, suepr-resolution에 오랫동안 사용되었다.
더해, non-local 속성 이전의 강력한 이미지는 네트워크의 성능 향상을 위해 암묵적으로 그러한 선행 학습하는 네트워크 구조에 포함된다.
또한, 내부의 분포를 배우기 위한 몇몇 작업들도 제안 되었고, 영상 복원을 위한 external과 internal 정보를 결합하는 연구도 많이 나왔다.
최근 ZSSR은 zero-shot SR을 제안한다.
- 오직 CNN의 힘많을 사용하여 zero-shot setting에 기반하지만, test image condition에 쉽게 적응한다.
- ZSSR은 test image로 부터 internal non-local 구조를 학습한다.
- 그래서 real-world에서는 external-based CNN보다 성능이 좋다.
- 또한 ZSSR은 test image의 conditon에 쉽게 적응할수 있는 blur kernel 덕분에 높은 유동성을 가진다.
하지만 ZSSR은 몇가지 제약이 있다.
- 결과를 얻기 위해 test time시 몇천번의 gradient 역전파 업데이트가 필요하다.
- Large-scale external dataset을 활용하지 않고 오직 internal 구조와 패턴에만 의존해 일반적인 external 패턴 관련된 영역에서는 external-based 방법보다 성능이 떨어진다.
최근 meta-learning 혹은 learning to fast가 최근 연구자들에게 많은 관심을 받고 있다.
- Meta-learing은 인공지능이 약간의 example만으로는 새로운 concept을 학습하기 어렵다는 문제점을 해결하는것이 목적이다.
- Meta-learning은 few-shot learning, 그리고 많은 방법들과 합쳐진 방법들이 제안되었는데 이중 MAML(Meta-Agnostic Meta-Learning)은 기본 학습자가 새로운 작업을 빠르게 학습할수 있도록 optimal initial state of the model을 학습하는 연구로 SotA를 달성했다.
- MAML은 meta-learner로 gradient update를 사용하여, gradient descent가 모든 학습 알고리즘에 근사할 수 있다.
본 연구에서는 MAML과 ZSSR에 영감을 받아 kernel-agnostic(커널을 믿지 않는) MZSR(Meta-Transfer Learing for Zero-Shot Super-Resolution)을 제안한다.
- ZSSR은 meta-test만을 수행하지만 MZSR은 meta-training도 같이 수행한다.
- Meta-transfer learing에 기반해 zero-shot unsupervised setting의 새로운 작업에 빠르게 적응가능한 효과적인 initial weight를 학습하는 새로운 훈련 방법을 제안한다.
- External과 internal 샘플을 사용하므로 interanl, external 두가지 학습의 이점을 활용할 수 있다.
- 빠르고 유연하고 가볍고 unsupervised at meta-test time을 통해 real-world에 적용할 수 있다.
2. Method
MZSR의 전반적인 방법은 그림 2에 나타나고 MZSR은 3가지 단계: large-scale training, meta-transfer learning, meta-test 로 구성되어 있다.

2.1 Large-scale Training
Large-scale traing 단계는 object 인식을 위한 large-scale ImageNet의 pre-training과 유사하다.
사용한 데이터셋은 DIV2K를 사용한다.
- 먼저, known 'bicubic' degradation을 사용해 HR-LR(bic) 이미지 페어를 만든다.
- Loss를 최소화 하기위해 bicubic degradation super-resolution을 학습하는 네트워크를 훈련시킨다.
- 식은 prediction과 GT간의 pixel-wise L1 loss를 의미한다.

- Large-scale traing은 두가지 기여점이 있다.
(1) Super-resolution 작업과 유사하게 효율적인 representations(고해상도 이전의 natural image)을 학습해, 네트워크가 쉽게 학습할 수 있다.
(2) MAML이 불안정한 학습을 보여주는데 well pre-trained feature representations이 meta-learning 학습단계를 도와줘 쉽게 학습할 수 있다.
2.2 Meta-Transfer Learning
ZSSR이 경사하강법으로 훈련된 이래로, 보편적인 학습 알고리즘으로 입증된 경사하강법의 도움으로 optimization-based meta-training 을 소개할 수 있다.
Meta-transfer learning 단계에서는 a few gradient update로 큰 성능 향상을 달성할 수 있도록 parameter 공간의 sensitive and transferable initial point를 찾는것이 목적이다.
MAML에 영감을 받아서 대부분 MAML을 따르지만, 본 연구에서는 MAML과 다르게 meta-training과 meta-test를 위한 다른 세팅을 채택 했다.
- Meta-trainnig에서는 external dataset을 활용하고, meta-test에서는 internal learning을 한다.
- 이는 large-scale external dataset의 도움으로 meta-learner가 kernel-agnostic 속성에 초점을 맞추기 위함이다.
Meta-transfer learning 데이터셋을 D_meta 라고 하고 HR, LR(diverse kernel) 쌍으로 이루어져 있다.
- Blur kernel을 위해 isotropic(등방성)와 anisotropic(이방성) Gaussian kernels를 사용한다.
- 공분산 행렬로 결정되는 각 kernel이 kernel distribution을 고려한다.

- random angle : Θ ∼ U [0, π]
- two random eigenvalues : λ 1 ∼ U [1, 2.5s], λ 2 ∼ U [1, λ 1 ]
- D_meta에 의해 meta-learner를 학습한다. (D_meta는 학습 단계 D_tr과 테스트 단계 D_te가 있다.)
Parameter θ에 대해 새로운 작업 T_i 에 적용해 한번 혹은 그 이상의 경사하강법을 수행한다.
- 한번의 gradient update를 위한 새로운 adapted parameter θ_i는 다음 식과 같고, α는 task-level의 학습률이다.

Model parameter θ는 D_meta의 test error를 최소화하기 위해 최적화 되어진다. Meta-objective 식은 다음과 같다.

Meta-transfer optimization은 위 식으로 수행되고, 이것은 knowledge across task(Meta-transfer learning의 전반적인 학습)을 배운다.
어떠한 gradient-based optimization도 meta-transfer 학습에 사용될수 있다.
parameter update rule은 SGD(stochastic gradient descent)를 따르고 식은 다음과 같으며 β는 meta-learning rate이다.

2.3 Meta-Test
Meta-test 단계는 ZSSR과 정확하게 같다.(모델이 single image 안에 있는 internal information을 학습한다.)
- 주어진 LR 이미지로, downsampling kernel을 통해 downsampling을 수행하여 I_son을 생성한다.
- LR 이미지를 모델에 적용해 super-resolved 이미지를 얻는다.
2.4 Algorithm
알고리즘 의사코드 1은 Large-scale training과 Meta-Transfer Learning을 묘사한다.
- Lines 3-7은 large-scale training 단계
- Lines 11-14는 기본 학습자가 task-specifc loss를 업데이트 하는 meta-transfor learing의 내부 반복
- Lines 15-16은 meta-learner optimization을 표현
- 식 2는 large-scale training의 식

알고리즘 의사코드 2는 ZSSR과 같은 meta-test 단계이다.
- A few gradient updates인 n이 meta-test 동안 수행한다.
- Super-resolved 이미지는 마지막 업데이트된 parameter에 의해 얻어진다.

3. Experiments
3.1 Training Details
- ZSSR을 따라서 residual learning으로 이루어진 8-layer CNN을 구성했다(255K개의 parameter수를 가진).
- DIV2K를 high-quality 데이터셋으로 활용했다(α = 0.01, β = 0.0001).
- Inner loop에서 5번의 gradient update 수행한다.(5 unrolling step, adapted parameter를 획득하기위해)
- Ttraining patch는 64X64 크기로 추출한다.
- 기초 학습자의 unrolling 과정으로 인한 Vanishing, Exploding gradient 문제를 해결하기 위해 각 단계 마다 weighted의 손실 합을 사용한다.(각 unrolling 단계에 추가적인 loss의 supervision을 제공)
- 초기엔 loss를 균등하게 측정하고 weights를 감소, 마지막엔 weighted loss가 최종 훈련 task loss로 수렴한다.
- Meta-optimizer로 ADAM을 사용한다.
- direct(non bicubic), bicubic 두가지를 훈련했다.
3.2 Evaluations on "Bicubic" Downsampling
Supervised, Unsupervised 방법론을 포함한 SotA SISR 방법론들과 비교했다.
- 데이터 : Set5, BSD100, Urban100
- 평가지표 : PSNR, SSIM, YCbCr colorspace
결과는 표 1에 나타난다.
- bicubic 방법으로 훈련된 CARN과 RCAN이 가장 뛰어난 성능을 보인다.
- ZSSR과 MZSR은 bicubic로 SR한 결과보다는 좋은 성능을 보이지만, unsupervised나 self-supervised regime이기 때문에 다른 방법에 비해서는 성능이 좋지 않다.
- MZSR은 ZSSR과 비교해서 좋은 성능을 보였다.

3.3 Evaluations on Various Blur Kernels
4가지 kernel : severe aliasing, isotrpic Gaussian, anisotropic Gaussian, bicubic sampling을 따르는 isotropic Gaussian을 사용해서 성능을 평가했다.(각 커널들은 아래와 같다.)

결과는 표2와 같다.
- bicubic방법에서 SotA를 보였던 RCAN이 낮은 성능을 보였다.
- 첫번째 kernel의 결과는 RCAN이 가장 낮은 성능을 보였고, supervised 방식인 IKC 또한 낮은 성능을 보였다.
반면에 ZSSR이 가장 좋은 성능을 보였지만, 이는 수천번의 gradient update가 필요하기 때문에 많은 시간을 요구하고 initial point가 랜덤하기 때문에 생성할때 마다 같은 결과가 나타나지 않는다.
MZSR은 다른 방법들과 비교했을때 gradient update를 적게 하더라도 좋은 성능을 보인다. - 다른 kernel의 결과는 MZSR의 결과가 다른 모델의 결과와 상당한 차이가 있다.
MZSR의 결과가 가장 좋으며 MZSR은 SR에서 빠르고, 유연하고, 정확한 방법이다.

3.4 Real Image Super-Resolution
제안된 MZSR의 성능을 보여주기위해 실제 이미지에 대한 실험도 한다.
실제 이미지에는 GT가 없고 오직 visual comparison만으로 표현한다.
결과는 다음 링크에 나타난다.
4. Discussion
4.1 Number of Gradient Updates
Ablation investigation을 위해 다른 구성으로 사용한 모델로 다양하게 훈련했다.
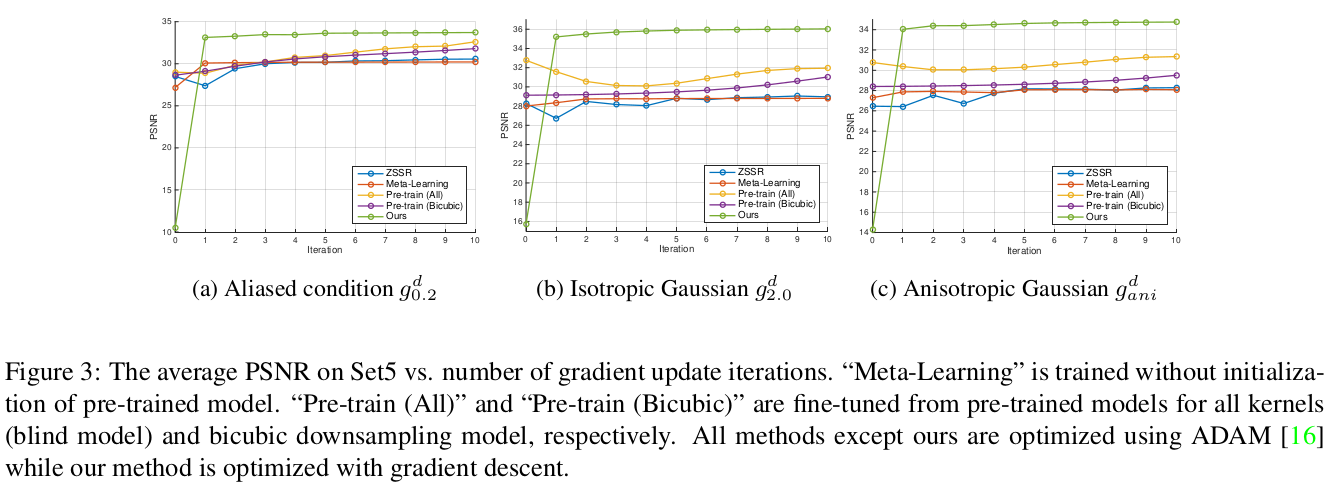
Set5를 사용한 PSNR결과가 그림 3에 나타난다.
- MZSR의 initial point가 가장 낮은 성능을 보였지만 첫번째 iteration 후에는 가장 좋은 성능을 보였다.
Initial point와 one gradient update에 대한 시각화 시킨 결과는 그림 4에 나타난다.
- 결과를 보면 initial point의 MZSR은 이상하지만, 첫번째 반복 이후엔 성능이 크게 향상된다.
- Initial point에서는 pre-trained 네트워크가 MZSR보다 더 나은 성능을 보이지만, gradient update 이후에는 MZSR을 성능이 더 좋다.
- Gradient update를 더 많이 한다면 MZSR의 성능은 더 개선될 것이다.

4.2 Multi-scale Models
[2.0, 4.0] scaling factor를 사용해 multi-scale 모델을 훈련했다.
표 3에는 X2의 결과가 나타난다.

Multiple scaling factors를 사용하면 task분포 p(T)가 더욱 complex 해 지는데, 여기서 meta-learner는 빠른 적응(adaptation)에 적합한 영역을 capture하기 위해 struggle(고군분투? 열심히?)한다.
- 더 큰 scaling factor를 meta-testing 할때, I_son의 크기는 CNN에 충분한 정보를 제공하기에는 너무 작아진다.
- 따라서 CNN은 매우 작은 LR_son 이미지를 거의 활용하지 않는다.
- 중요한 것은 CNN이 CNN의 internal information을 학습함에 따라, 그림 5와 같이 multi-scale recurrent 패턴을 가진 이미지는 large scaling factor에도 좋은 결과를 보여준다.

4.3 Complexity
다른 모델들과 time complexities를 비교한 결과는 표 4에 나타난다.
- GPU는 NVIDIA Titan XP를 사용해 측정한다.
- CARN과 RCAN은 parameters 수가 많다.
- 비록 CARN이 RCAN과 비교했을때 가벼운 모델 일지라도, unsupervised 모델들에 비해 parameter수가 많다.
- 하지만 CARN과 RCAN 모두 feedfoward 연산만 하기 때문에 연산속도는 빠르다.
- ZSSR은 unsupervised 방법으로 훨씬 적은 parameter를 가지고 있지만, 수천번의 forward와 backward pass가 필요해 많은 시간이 소요된다.
- MZSR은 single gradient update를 하면 연산 시간이 가장 적게 소요되고, 10번 수행하더라도 CARN보다 소모되는 시간이 적다.

5. Conclusion
- 본 연구에서는 빠르고, 유연하고, 가벼우며, external과 internal sample을 모두 활용하는 self-supervised SR 방법을 제안했다.
- 구체적으로 blur kernel의 다양한 조건에 sensetive initial point를 찾기 위해 transfer learning과 함께 optimization 기반의 meta-learning 방법을 채택했다.
- 그러므로 MZSR은 적은 gradient update를 수행하더라도 이미지 별 condition을 빠르게 adapt(채택, 적응)할 수 있다.
- MZSR은 ZSSR에 비해 좋은 성능을 나타냈고, 다른 방법들과도 비교해서 좋은 결과를 나타냈다.
Paper
https://openaccess.thecvf.com/content_CVPR_2020/papers/Soh_Meta-Transfer_Learning_for_Zero-Shot_Super-Resolution_CVPR_2020_paper.pdf
'딥러닝 논문 리뷰' 카테고리의 다른 글
| RZSR with Depth Guided Self-Exemplars Review (0) | 2023.02.02 |
|---|---|
| Online Learning for Reference-Based Super-Resolution Review (0) | 2023.01.31 |
| TTSR Paper Review (0) | 2023.01.17 |
| Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution Paper Review (0) | 2023.01.14 |
| Zero Shot SR review (0) | 2023.01.03 |



