
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Reference Super-Resolution
- implicit representation
- Reference-based SR
- TAAM
- SegFormer
- INR
- hypergraph
- Zero-Shot sr
- Super-Resolution
- Cityscapes
- session-based recommendation
- Cell detection
- Graph
- GNN
- deep learning
- TRANSFORMER
- CrossNet
- Feature reuse
- SISR
- Referense Super Resoltuion
- DIINN
- FRFSR
- LIIF
- GNN in image
- ConvNeXt
- Tissue segmentation
- graph neural network
- arbitrary scale
- ADE20K
- Cell-tissue
Archives
- Today
- Total
딥러닝 분석가 가리
Learning with Unmasked Tokens DrivesStronger Vision Learners 본문
"Learning with Unmasked Tokens Drives Stronger Vision Learners"
Abstract
- Masked image modeling (MIM) pre-trained encoders often exhibit a limited attention span, attributed to MIM's sole focus on regressing masked tokens only, which may impede the encoder's broader context learning
- To tackle the limitation, we improve MIM by explicitly incorporating unmasked tokens into the training process
- Specifically, our method enables the encoder to learn from broader context supervision, allowing unmasked tokens to experience broader contexts while the decoder reconstructs masked tokens
- Thus, the encoded unmasked tokens are equipped with extensive contextual information, empowering masked tokens to leverage the enhanced unmasked tokens for MIM
Introduction
- Advances in MIM noticeably show great success in self-supervised learning (SSL) of ViT by transferring the knowledge of masked language modeling
- Conceptually, MIM tasks consist of two parts: randomly masking out a part of inputs and predicting the masked inputs by the decoder
- This simple strategy enables a model to learn strong representations through the challenging task
- However, MIM strategies often encounter challenges, such as local dependency on attention to understand the entire context of an image
- exhibits shorter average attention distance
- observe that attention map patterns by MAE substantiate extremely local behavior indeed (Fig.1)

- We aim to understand the chronic shortage in a limited range of dependencies and how it affects MIM
- Identify a deficiency inside the vanilla MIM formulation and present a simple solution to its local dependency issue, demonstrating how it enhances MIM pre-training
- The proposed method of Learning with Unmasked Tokens (LUT) for MIM complements the sub-optimal representation learning by offering broadly contextualized supervision to unmasked tokens through extracting general context from the entire pixels to strengthen unmasked tokens (for masked tokens to attend), which aims to learn more context-generalized representations for the encoder
- During training, LUT minimizes the discrepancy between the encoded general context representations and the sparse representation
- Processed by the online learnable encoder from different views while performing MIM with a decoder
- This ensures reinforcing more contextualized unmasked tokens for mask tokens to attend to
- A general representation derived from all pixels can effectively utilize a highly augmented view, minimizing reliance on regional changes like color distortion to improve generalization
- The learnable network encodes a sparse and unmasked view and matches it to the generalized representation, and the decoder reconstructs the masked pixels using the encoded features
Preliminary
- Despite MIM's strong performance, we claim it still lacks strong attention capability after pre-training, particularly for comprehensive region-wide dependency
- General formulation

- MIM formulation itself falls short in learning broader contexts
- MIM loss may not fully exploit the pre-training capability while it is effectively designed with simplicity
- Owing to the scarcity of unmasked tokens in the encoder, the formulation does not leverage complete image information; encoded through, being only attended by a few visual tokens
Method

Our simple solution
- We contend that Eq.(1) computes loss exclusively using reconstructed masked tokens while leaving unmasked tokens being trained implicitly, which may impede learning broad contexts effectively
- Employ another loss expected to aid L_{MIM} by giving expansive supervision to unmasked tokens from the entire tokens

- D(·, ·) and g(·) denote a distance function and a context encoder
- Straightforwardly give encoded comprehensive supervision from entire tokens to unmasked tokens
- The expansively supervised unmasked tokens contain extended token information so that mask tokens can leverage it
Contextualized supervision
- The crux of our solution lies in learning unmasked tokens actively from a more comprehensive contextualization of entire visual tokens
- Opt for the elements in the newly involved loss (dubbed broader contextualization loss L_BC) in Eq. (2)
- Context encoder g, we implement this by simply reusing the encoder f_θ to give the supervision back to f_θ
- Employ momentum networks, architecture consists of a momentum encoder and MLP head
- Augmenting image patches from U to V to enhance the generalization of the encoder and avoid collapse
Sparse unmasked tokens that learn broad contexts
- Our encoding process obtains regional representations from sparsified tokens
- Aggregate the latent embeddings by averaging
- LUT can be interpreted as utilizing masked tokens for MIM interacting with sparse visual tokens employed to condense expanded context information
On contextual discrepancies across views
- Aim to provide broader contextualized supervision to unmasked tokens that correspond to the original view of the masked tokens
- MIMs generally use random resize crop(RRC) for giving geometric variation; using RRC may not align with our intention and could hinder learning
- Due to divergent views often providing narrower and limited shared information
- Adopt simple resized crop (SRC), SRC harms MAE but improves LUT
Object function
- Apply the normalized l2 distance for the feature distance
- Aggregated context representation and sparse one, and their l2 normalized version
- Broader contextualization loss computes the feature distance between normalized representations, formulated as:

- LUT is agnostic to the choice of distance function since the fundamental principle of it works regardless of the distance functions, InfoNCE of Smoothed l1 loss

Experiment
ImageNet-1K classification
Architecture
- Use the standard Vision Transformer (ViT) with a patch size of 16 for all experiments (ViT-B/16)
- Use the 8-layer transformer decoder following the MAE's setup for masked image modeling
- MLP heads aggregate general context from representations; 4096 dimension, batch normalization, ReLU
- Decoder and MLP heads are only used during training
Pre-training setup
- Follow ImageNet-1K pre-training protocol (same to facebook research mae)
- 1600 epochs with 40warmup epochs
- batch size 4096, image resolution 224x224
- AdamW, learning rate 1.5e-4 with cosine learning rate decay, Adopt layer-wise learning rate decay of 0.65
- Mask ratio 0.75, momentum decay rate 0.996, broader contextualization loss 1.0, 0.25 for the ViT-S/16 and ViT-B/16, respectively
- Employ SRC for geometric augmentation, color jittering, and the three augment consists of Gaussian blur, grayscale, and solarization
- All models are pre-trained using 8 V100-32GB GPUs
Results

- LUT achieves superior performance
- This comes to a head with a smaller ViT-S/16, where most of the results are saturated, but this is presumably due to the low capability of the backbone and the high flexibility of masked feature models
- The results highlight the efficacy of our proposed broader contextualized supervision in enhancing MIM, which showcases its significant potential for further improvements
ADE20K Semantic Segmentation
- To validate the transferability to dense prediction tasks, we evaluate semantic segmentation performance on ADE20K
- Follow the standard training protocol (MAE), fine-tuned for 160K interactions using UperNet, batch size 16, resolution 512x 512
- LUT also outperforms the competing methods
- This outcome can be attributed to the improved dense prediction capability
Computational costs
- Slight increase in computational demands, as mentioned above
- Top-1 accuracy of 83.6% at 400 epochs (119 hours), which matches MAE's accuracy at 1600 epochs (223 hours)
Transfer Learning
iNaturalist datasets
- Pre-trained ImageNet-1K, ViT-B/16 with a resolution of 224x224

Fine-Grained Visual Classification (FGVC) datasets

Analysis and Discussion
Ablation Study
- Use ViT-B/16 and train it for 400 epochs on ImageNet-1K as the fixed pre-training setup
Steered tokens
- Show that steering unmasked tokens via comprehensive supervision leads to an improved encoder
- Investigate whether masked tokens also benefit from steering
Contextualization for token steering
- Mainly used the visual tokens for contextualizing methods, but we studied whether other tokens (cls-token)
- Observe using pooled visual tokens is preferred for LUT
- Considering latent features undergo masked auto-encoding, these results imply that explicitly using general context is more effective than using implicit information via cls-token
Type of supervision
- Study the effectiveness of various supervision for unmaksed tokens
- Both supervision achieves lower performance than contextualization, implying that the additional token-wise supervision may conflict with the aggregated one, which is presumably due to the alignment between the set of tokens
Loss function
- Explore various losses for the broader contextualization loss
Masking ratio for target
- Study the target encoder needs masked image
- Without target masking outperforms all its counterparts
- Moreover, fine-tuning accuracy with masking even underperforms the baseline
- Implying that transferring coarse information harms the capability of learning representation
Image crop type
- RRC is more compatible with MAE than SRC, which indicates that the information that will be encoded needs to align closely with the view to the other side, thereby facilitating training

Further Analyses
Grad-CAM visualization

Analysis of attention distance
- Measure the average attention distance (AAD) to explore the dependency range in MAE quantitatively
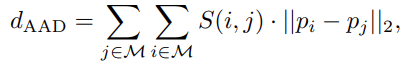
- Compute AAD using the entire images from the ImageNet-1K validation set
- ViT-B/16 pre-trained by previous method
- The analysis focuses on the layer-wise AAD for the last three layers
- LUT exhibits diverse ranges, spanning from shorter to longer-range dependencies
- Thus, LUT generally interacts wider than MAE and also surpasses others in the distance scopes
- Notably, the phenomenon is more significant at the final layer, which determines the capacity of contributes most to high-level semantics

Spectral analysis
- Additional analysis on the learned layer-wise representations LUT and MAE
- Measure the singular values (SVs) of the covariance features (how the features are spread in the embedding space)
- Fig. 4 shows a spectrum of log of singular value gaps between MAE and LUT across the layers
- 그림과 논문의 설명이 달라서 더 이상 설명하지 않음
Robustness Evaluation
- Employ two in-distribution benchmarks including ImageNet-V2 and -Real and four out-of-distribution benchmarks ImageNet-A, -O, -R, -Sketch, ObjectNet; further use SI-Score to test spurious correlations with the background

Conclusion
- Introduced a novel framework to address the limited broader understanding of image inherent in MIM
- MIM learns a narrower range of dependency due to lacking a comprehensive understanding of the entire pixel
- Proposed LUT pre-training method, minimizing the discrepancy between the context features and sparse visual tokens through our broader contextualization loss
'딥러닝 논문 리뷰' 카테고리의 다른 글
'딥러닝 논문 리뷰' Related Articles
more




Comments