
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- SegFormer
- Reference Super-Resolution
- Feature reuse
- Cell detection
- TAAM
- hypergraph
- session-based recommendation
- Super-Resolution
- SISR
- implicit representation
- deep learning
- DIINN
- arbitrary scale
- INR
- Cell-tissue
- Cityscapes
- Zero-Shot sr
- CrossNet
- ConvNeXt
- Graph
- GNN
- ADE20K
- Reference-based SR
- FRFSR
- Referense Super Resoltuion
- Tissue segmentation
- LIIF
- GNN in image
- TRANSFORMER
- graph neural network
- Today
- Total
딥러닝 분석가 가리
Omni Aggregation Networks for Lightweight Image Super-Resolution Review 본문
Omni Aggregation Networks for Lightweight Image Super-Resolution Review
AI가리 2023. 5. 29. 21:31"Omni Aggregation Networks for Lightweight Image Super-Resolution"
Abstract
경령화 된 ViT frame work는 이미지 super-resolution(SR)에서 엄청난 발전을 이루었지만, uni-dimensional, 일차원의 self-attention 모델링 뿐만 아니라 homogeneous aggregation 방법은 effective receptive field(ERF)를 공간 및 채널 차원 모두에서 보다 포괄적인 상호작용을 포함하도록 제한한다. 이러한 단점을 해결하기위해 새로운 Omni-SR 구조에서 두가지 개선된 구성요소를 제안한다. 첫번째, Omni Self-Attention (OSA) block은 dense interaction principle, 밀접한 상호작용 원리에 기반되어 제안된다. Dense interaction princple은 공간과 채널 차원으로 부터 pixel 상호작용을 동시에 모델링해 공간과 채널, omni 축에 걸친 잠재적 상관관계를 마이닝할 수 있다. Mainstream과 결합한 window 분할 전략인 OSA는 낮은 계산량으로 높은 성능을 달성할 수 있다. 두번째, multi-scale interaction 방법은 얕은 모델에서 premature saturation 같은 sub-optimal ERF를 완화하기 위해 제안된다. Multi-scale interaction은 local propagation과 meso/global 상호작용을 용이하게 해 onmi-scale aggregation building block을 랜더링 한다. 실험에서 Onmi-SR이 lightweight SR bench mark에서 고성능을 달성했다.
1. Introduction
Image super-resolution (SR)은 LR 영상을 HR 영상으로 복구하는 것으로 오랫동안 지속된 low-level 문제다. 최근 vision transformer (ViT) 기반의 SR은 이전의 CNN 방법들 보다 좋은 성능을 보였지만, large-scale ViT가 좋은 성능을 보이며 많은 시도가 있고 lightweight ViT (1M parameter 미만)는 여전히 어렵다. Onmi 논문은 lightweight ViT로 SR해 좋은 성능을 내는것에 초점을 둔다.
Lightweight ViT 기반의 SR 모델을 만드는데는 어려운 문제점이 두가지가 있다. 아래와 같은 문제들은 lightweight model은 충분한 layer를 쌓을수 없기 때문에 lightweight model을 악화시킨다.
- Uni-dimensional aggregation operator (spatial only or channel only)은 self-attention의 잠재적인 측면을 구속한다.
- 일반적인 self-attention은 너비와 높이의 공간 뱡향의 교차 공분산을 계산해 픽셀 간의 상호작용을 실현하고 channel 분리 방식으로 context 정보를 교환한다.
- 하지만, 최근의 분석과 저자의 실현은 공간적 self-attention 보다 계산적으로 더 조밀한 channel 차원의 self-attention이 low-level task에서 중요하다고 한다.
- Homogeneous aggregation 방법은 SR에서 필요한 multi-scale의 풍부한 texture pattern을 무시한다.
- Single operator은 단일 scale의 정보에만 민감하다.
- Self-attention은 long-term 정보에만 민감하고 local 정보는 거의 사용하지 않는다.
- Homogeneous operator를 쌓는것은 비효율적이고 상호작용 범위에서 premature saturation의 어려움을 겪는다.
이러한 문제를 해결하고 높은 성능을 보장하기 위해 새로운 onmi-dimension feature aggregation scheme인 Omni Self-Attention (OSA)를 제안한다. OSA는 spatial과 channel 축의 정보를 동시에 exploit하는 방법으로 higher-order receptive field 정보를 제공한다. OSA는 그림 1과 같다. Scalar-based (a group of important coefficient) channel 상호작용과 달리 OSA는 spatial/channel 차원간 상호 공분산 행렬 계산을 계산식으로 수행해 정보의 전파를 이해할 수 있다. 제안된 OSA 모듈은 어떠한 self-attention, Swin이나 Halo같은, 에도 부착될수 있으며, 이는 중요한 encoding의 미세한 입상도를 제공해 상황별 contextual aggregation 능력을 향상시킨다. 게다가, 다양한 크기의 texture pattern의 맞춤형 인코딩을 달성하기 위해 multi-scale 계층 aggregation 블럭인 Omni-Scale Aggregation Group (OSAG)가 제공된다. 특히 OSAG는 3개의 cascaded aggregators, Local detail을 추출하기 위한 local convolution, mid-scale의 pattern을 처리하기 위한 meso self-attention, global context의 이해를 위한 global self-attention을 설계한다. Omni-scale (local, meso, global을 동시에) feature는 추출 기능을 랜더링 한다. Homogenized feature 추출 방법과 비교했을 때, OSAG는 정보 entropy가 높은 feature를 생성하는 풍부한 정보를 mining할 수 있다. 위의 두가지 설계를 결합해 만든 Omni-SR이라고 불리는 새로운 ViT 기반의 lightweight SR 모델은 729K와 같이 모델 파라미터가 적으면서 더 큰 상호작용 범위를 커버할 뿐만 아니라 고성능의 복원 성능을 보인다.

2. Methodology
2.1 Attention Mechanisms in Super-Resolution
Spatial Attention
Spatial attention은 anisotropic selection 과정으로 간주되어질 수 있다. Spatial self-attention과 spatial gate가 주로 적용된다. 그림 2와 같은 spatial self-attention은 spatial 차원을 따라 cross-covariance를 계산하고 spatial gate는 channel-separated mask를 생성한다. 이 방법 둘다 channel 간에 정보를 전송할 수 없다.
Channel Attention
Channel attention에 있는 두가지 전략인 scalar-based와 covariance-based는 channel 재보정 혹은 channel 간 pattern 전송을 수행하도록 제안되었다. Channel attention은 그림 2와 같이, scalar-based는 서로 다른 channel의 weight를 측정하는 importance scalars 그룹을 예측하고, covariance-based는 channel re-weighting과 정보 전송을 동시에 가능하게 하기 위해 cross-covariance 행렬을 계산하다. Spatial attention과 비교했을때 channel attention은 spaital 차원을 isotropically 처리하므로 복잡성이 현저히 줄어들고 aggregation의 정확도도 감소한다.

여러번의 시도로 spatial attention과 channel attention이 SR에 유익하고 서로 보완적이란것이 입증되었고, 그에 따라 계산적으로 compact한 방식으로 통합하면 표현 능력에서 주목할 만한 이점을 얻을 수 있다.
2.2 Omni Self-Attention Block
Latent variables에 숨겨진 모든 상관관계를 마이닝 하기 위해 새로운 self-attention paradigm인 Omni Self-Attention (OSA) block을 제안한다. Spatial self-attention 같이 기존에 존재하는 uni-dimensional 처리만 하는 self-attention과 다르게 OSA는 spatial과 channel context를 동시에 처리한다. 획득한 2-dimensional 관계는 lightweight model에서 필요하고 유익하다. 반면에 네트워크가 깊어질수록 중요한 정보는 서로 다른 channel로 분산되어 있어 이를 시기에 맞게 처리하는것이 중요하다. 다른 한편으로는 비록 spatial self-attention이 covariance를 계산할 때 channel dimension을 활용할 지라도, 각 channel 간 정보를 전송할 수 없다. 이러한 조건을 고려할 때, OSA는 spatial과 channel dimensional 정보를 모두 compact 방법으로 전송할 수 있게 설계했다.

제안된 OSA는 순차 행렬 연산 과 회전을 통해 spatial과 channel 방향에 해당하는 score 행렬을 계산한다. 이는 그림 3과 같다. 먼저, input feature X는 linearly projection을 통해 Q, K, V 임베딩 된다. Spatial attention map의 크기 HW×HW를 구하기 위해 Q와 K의 production을 계산한다. 그런 다음 self-attention을 수행해 중간 aggregated 결과를 얻는다. 이때, window strategy는 resource overhead를 충분히 줄이기 위해 사용된다. 다음 단계에서는 transpose된 Q, K를 얻기 위해 입력된 Q, K를 회전하고 channel-wise self-attention을 위해 V 또한 회전해 V를 얻는다. 이때 회전하기 전의 Q, K, V는 HW×C 이며 회전 후의 Q, K, V는 C×HW 이다. 획득한 C×C 크기의 channel-wise attention map은 channel-wise 관계로 모델링 한다. 마지막으로, channel attention 출력을 다시 inverse rotation 하여 최종 aggregated 출력을 얻는다. OSA의 전체적인 과정을 식으로 나타내면 다음과 같다.
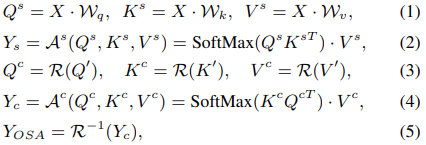
X는 input feature, W는 linear projection matrices, Q', K', V'은 channel-wise self-attention의 입력 임베딩 metrices, spatial self-attention 앞에서 임베딩 되거나 Q^s, K^s, V^s에서 복사된다. R은 spatial 축을 중심으로한 rotation 연산, R^-1은 inverse rotation. 일부 normalization은 단순성을 위해 생략된다. 특히 이러한 설계는 두 행렬 연산 spatial, channel matrix 연산의 요소별 결과를 통합해 onmi 축 상호작용을 가능하게 할 수 있는 특성을 보여준다. 제안된 OSA paradigm은 Swim attention block을 더 적은 parameter로 더 높은 성능으로 drop-in replacement 할 수 있다. Channel attention map의 작은 attention map의 크기의 이점을 활용해 제안된 OSA는 Swin의 cascade shifted-window self-attention에 비해 계산 양이 적다.
CBAM, BAM과 같이 이전의 하이브리드 channel, spatial self-attention과 비교할 때, scalar-based self attention weight는 내부 픽셀간의 정보 교환 없이 상대적인 중요도만 방영해 제한된 모델링 기능으로 이어진다. 최근 channel attention 과 spatial attention을 통합하는 연구도 있지만, 이러한 시도는 channel 재보정을 위해 scalar weights에만 의존하는 반면 OSA는 channel-wise 상호작용을 통해 omni 축의 잠재적 상관관계를 마이닝 할 수 있다.
2.3 Omni-Scale Aggregation Group
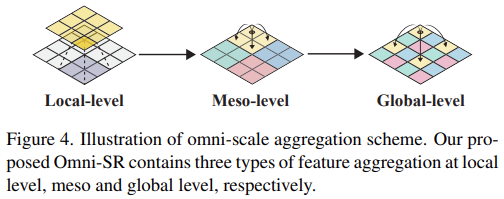
제안된 OSA를 활용해 고성능 compact network를 구축하는 방법도 핵심 주제이다. 비록 swin 같은 windows-based self-attention을 계층적으로 쌓는것이 주류가 되었지만, 다양한 연구에서 window-based paradigms이 너무 넓은 범위의 상호작용으로 얕은 네트워크에서는 매우 비효율적이다. 넓은 범위의 상호작용은 영상 복원 성능을 향상시키는데 중요한 효율적인 receptive field를 제공할 수 있다는 부분에 지적할 가치가 있다. 불행히도, 직접적인 global 상호작용은 자원을 제한하고 local aggregation 기능을 손상시킨다. 이러한 부분들을 고려해, 낮은 계산량으로 점진적인 receptive field feature aggregation을 추구하는 Omni-Scale Aggregation Group (OSAG)를 제안한다. OSAG는 그림 3과 같으며 local, meso, global aggregation 3단계로 구성된다. 특히, 제한된 overhead로 local pattern 과정을 수행하기 위해 channel attention의 개선된 반전 bottle neck이 도입된다. 제안된 OSA paradigm을 기반으로 meso와 global 정보의 상호작용과 aggregation을 담당하는 두가지 instance Meso-OSA와 Global-OSA를 도출한다. 제안된 omni self-attention은 다른 목적으로 사용될 수 있다. Meso-OSA는 non-overlap patches 그룹 내에서 attention을 수행하고, 이는 Meso-OSA가 meso-scale pattern만을 이해하도록 제한한다. Global-OSA는 atrous 방법으로 전체 feature에 걸쳐 데이터 포인트를 sparse하게 샘플링하므로 Global-OSA는 compelling cost로 global 상호작용을 달성할 수 있다.
Meso-OSA와 Global-OSA의 차이점은 그림 4와 같이 window partition 전략이다. Meso-scale의 상호작용을 성취하기 위해 Meso-OSA는 input feature X를 크기가 P×P인 non-overlapping block으로 분할한다. Window partition 후에, block의 차원은 spatial 차원으로 모인다. 이는 -2축 기준으로 다음과 같다:
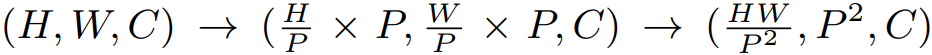
Global-OSA가 input feature를 균일한 G×G grid로 나누는 동안, 각 grid는 H/G×W/G의 adaptive 크기를 가진다. Meso-OSA와 유사하게 grid 차원도 spatial 축으로 모인다. -2축 기준으로 다음과 같다:
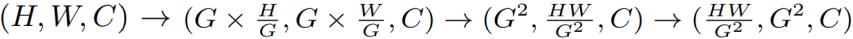
2.4 Network Architecture
Overall Structure
OSA paradigm과 OSAG에 기반해 SR에서 고성능을 달성한 lightweight Omni-SR 모델을 개발한다. 전체적인 구성도는 그림 3과 같다. Omni-SR은 총 3가지, shallow feature extraction, deep feature extraction, image reconstruction으로 구성된다. LR 입력이 주어지면 3×3 conv로 shallow feature를 추출한다. 다음, K개의 OSAG와 1개의 3×3 conv layer를 cascade 방법으로 사용해 deep feature를 추출한다. 마지막으로 HR 영상을 만들기위해 shallow and deep feature를 aggregatoin 한다. 이 과정을 수식으로 나타내면 다음과 같다:
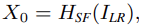
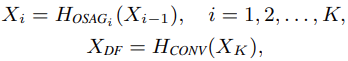
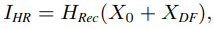
OMni-Scale Aggregation Group (OSAG)
OSAG는 local convolution block (LCB), meso-OSA, global-OSA 그리고 ESA block을 가지고 전체 과정은 다음과 같다:
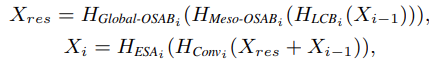
Convolution layer로 맵핑한 후 window-based self-attention을 위한 Meso-OSAB와 더 나은 정보 aggregation을 위해 receptive field를 넓힌 Global-OSAB를 사용한다. OSAG가 끝나면 ESA를 사용한다.
구체적으로 LCB는 channel-wise feature를 adaptive하게 re-weight 하기 위해 CA모듈을 사이에 두고 point-wise and depth-wise convolutoin을 쌓아 구현한다. 이 LCB는 local contextual 정보를 aggregate하는것 뿐만 아니라 네트워크의 학습 능력을 향상 시키는것이 목적이다. 두 종류의 OSA block은 다른 지역으로 부터 상호작용을 한다. Window partition 전략인 Meso-OSA는 inner-block 상호작용을 찾고 Global-OSA는 global mixing을 목적으로 한다. OSA block은 전통적인 transformer와 LayerNorm으로 구성된다. 기존의 self-attention과 다른점은 OSA 연산으로 대체된 점 이다. Feed forward network로는 GDFN을 사용하고 이를 OSAG와 결합한다. 그리고 ESA를 사용해 fused feature를 더욱 세분화 한다.
Optimization Objective
이전의 방법들과 동일하게 loss function은 L1을 사용한다.
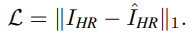
3. Experiments
3.1 Experimental Setup
Dataset and Metrics
- Train : DIV2K, DF2K(DIV2K + Flickr2K), DF2K로 훈련한 모델은 † 표시를 함
- Test : Set5, Set14, B100, Urban100, Manga109를 사용
- YCbCr 공간에서 Y channel의 PSNR과 SSIM으로 성능을 측정
Implementation Details
- 훈련동안 데이터를 90/270도 수평 방향 회전으로 증강, LR은 HR을 bicubic으로 보간
- OSAG 수는 5, network channel은 64, Meso-OSA와 Global-OSA의 attention head 수와 window size는 4와 8
- Optimizer는 Adam, batch size는 64, iteration은 800K, Learning_rate는 1e-4 부터 200K 마다 절반으로 감소
- 각 training batch마다 64×64 크기로 LR patch의 랜덤한 부분을 crop해서 입력으로 사용
- Deep learning framwork는 Pytorch, GPU는 V100 한 장 사용
3.2 Comparsion with the SOTA SR methods
Quantitative results
기존의 lightweight model과 비교한 결과는 표 1과 같다. 비스한 model-size를 가진 다른 모델드로가 비교했을때 가장 좋은 성능을 보이며, SwinIR이나 ESRT와 비교했을때에도 더 좋은 성능을 보인다. 이러한 결과는 OSA에 의해 도입된 omni 축 (spatial + channel) 상호작용이 모델의 contextual aggregation 기능을 효과적으로 향상시켜 더 명확한 SR 영상을 만든다. DF2K 데이터를 사용한 경우 Urban100에서 SR 성능이 더욱 향상되었다. 이는 Urban100에서 영상에 유사한 패치가 많고 장기적인 관계가 있어 OSAG가 세부적은 부분의 복원에 큰 이점을 줄 수 있다. 더 중요한 것은 SwinIR(50G) 보다 Onmi-SR(36G)이 계산 복잡성을 28% 감소시켰다.
Visual comparison
다른 lightweight SR 방법들과 4배 SR 한 결과를 비교한 것은 그림 6과 같다. 'img_012'에서 Omni-SR만 HR과 유사하게 세부적인 texture까지 복원했다. 시각적 결과 또한 OSA paradigm이 omni 축에서 pixel-wise 상호작용 모델링을 수행 할 수있어 효율적임을 검증했다.

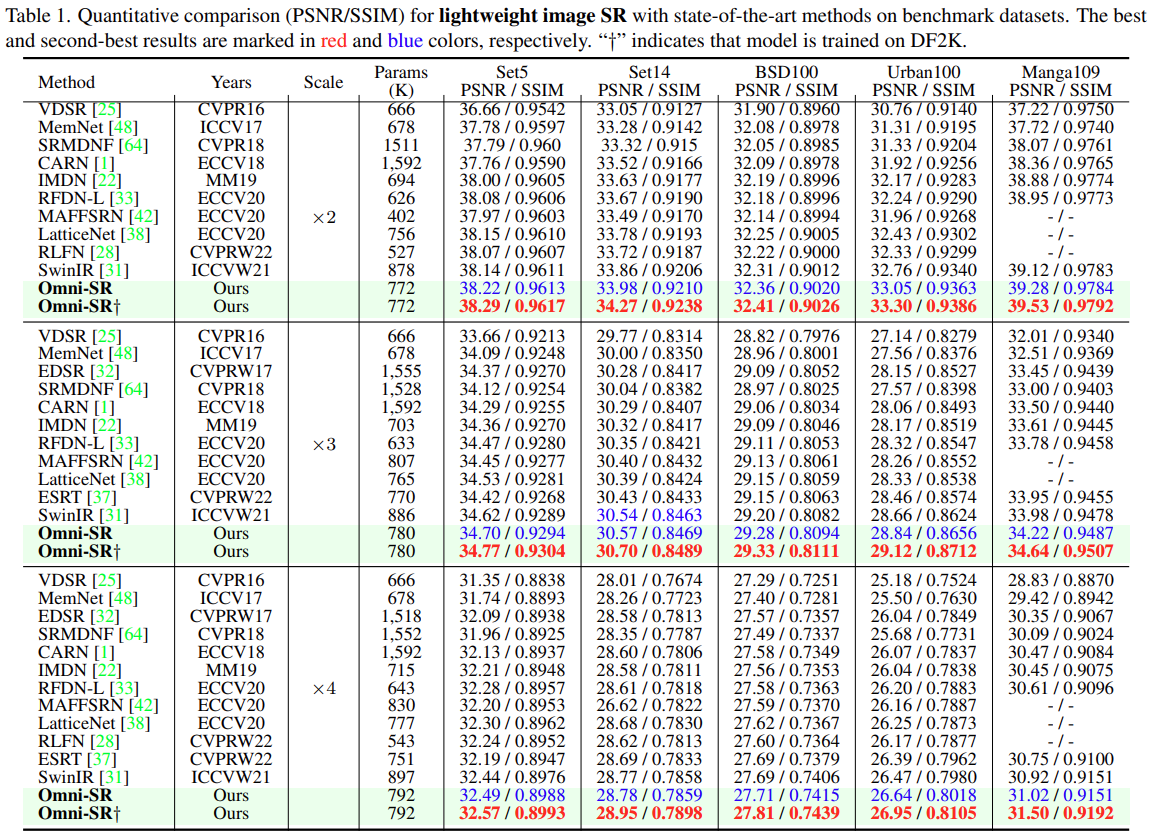
Trade-off between Model Size and Performance
OSAG의 갯수와 모델 사이즈를 계산해 다른 방법들과 비교한다. OSAG 갯수에 따른 성능결과와 다른 모델들과 비교한 모델 크기별 PSNR은 그림 5와 같다. OSAG의 수를 늘릴수록 학습이 안정적이게 되어 성능이 향상된다. 또한 Omni-SR은 다른 모델들과 비교했을때 파라미터 수가 적더라도 가장 높은 PSNR을 보인다.
3.3 Analysis of Omni Self-Attention & Ablation Study
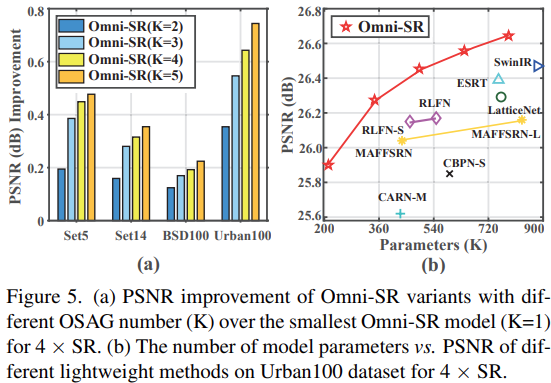
Analysis of Omni Self-Attention
이 절에서는 OSA의 최적화 기능을 설명하고 추가적인 기능을 밝혀낸다. 그림 7은 OSAG의 기능에 따른 성능 그림 이다. Onmi-SR은 점진적인 feature aggregation을 추구하기 위해 local-meso-global 상호작용 방법을 제안한다. Onmi-SR의 효율성을 증명하기 위해 Sparated, Mixed, 그리고 제안하는 방법인 Omni 방법인 3가지 다른 구조를 설계해 비교한다. 비교 결과는 그림 7(a)와 같다. Separated 에서는 Local 방법의 성능이 가장 열등하고 Global이 Meso에 비해 낮은 성능을 보인다. 이는 global self-attention의 빈약한 최적화 특성 때문이다. Mixed 에서는 학습이 좀 더 안정적으로 진행되어 성능이 향상 된다. Meso와 Global을 같이 사용한 방법이 두번째로 성능이 좋으며 3가지 모두 사용한 Omni는 local, meso, global 상호작용을 모두 활용했기 때문에 성능이 가장 좋다. 이러한 실험 결과로 various-scale 상호작용을 도입함으로 써 명백히 성능 이득을 얻을 수 있다. 또한, OSAG가 실현가능하고 효율적인것을 보여준다.
Self-attention은 low-bias 연산으로 최적화 하기 어렵고 많은 학습 반복횟수를 요구한다. 이러한 단점의 해결법으로 channel-wise 상호작용을 추가한다. 그림 7(b)에서 spatial, channel, omni self-attention에 대한 training loss curve를 보여준다. OSA 방법이 수렴 속도가 가장 빠른것을 보여준다. 좀 더 중요한것은 마지막 epochs의 결과도 가장 좋다는 것이다. 이러한 현상은 OSA가 우수한 최적화 특성을 가지고 있다는것을 보여주며 channel-wise 상화작용이 이러한 개선을 이끈다.
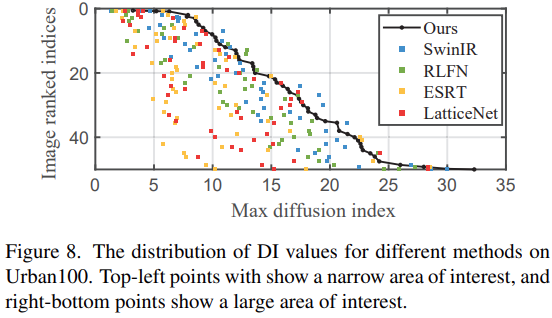
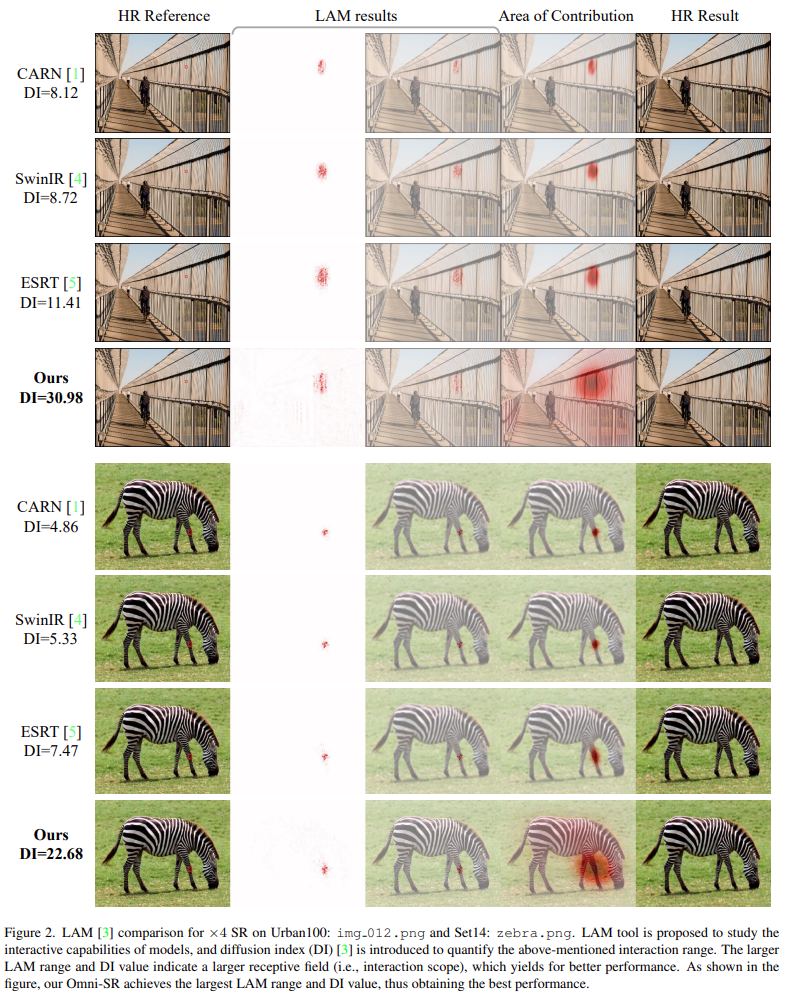
위의 세가지 computational primitves로 구성된 네트워크의 hidden layer feature의 normalized entropy를 계산한다. Entropy 결과는 그림 7(c)와 같다. 모든 outgoing layer에서 OSA-encoded feature가 더 높은 entropy를 보여 OSA가 더 풍부한 정보를 인코딩 한다는것을 나타낸다. 더 많은 정보가 다양한 scales로 부터 제공될 수 있고, 이러한 정보는 정확한 세부 정보를 더 빠르게 재구성하는데 도움을 줄 수 있다. 이것이 OSA가 더 나은 최적화 속성을 보여주는 이유라고 추측한다. 또한, 이전 연구에 이어서 LAM 분석에도 의존한다. DI 방법은 모델의 가장 먼 상호작용 거리를 측정할 수 있다. 그림 8에서 Omni-SR이 일반적으로 다른 방법보다 max diffusion index가 가장 높다는것을 관찰할 수 있으며, 이는 OSA가 장거리 상호작용을 효과적으로 포착할수 있음을 보여준다.
Ablation Study
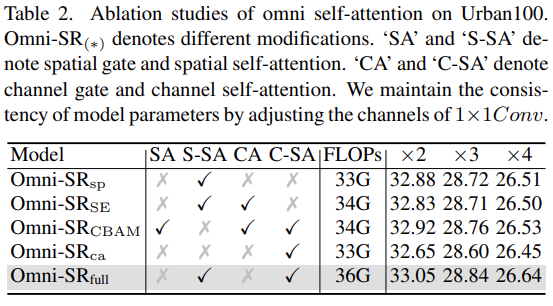
제안하는 방법의 핵심 아이디어는 기본 self-attention을 channel-wise 관계를 활용해 확장시켜 omni 축의 pixel-wise 상호작용을 설계하는것이다. Omni-SR에 기반해 몇가지 다양한 모델을 설계하고 이것에 대한 SR 결과를 표 2에 나타낸다. 먼저 channel-wise 구성요소를 제거해 spatial 전용 변형 Omni-SR_sp를 만든다. 이는 전체 모델에 비해 0.13dB 저하된다. 이러한 차이는 channel 상호작용이 중요시 된다는것을 정당화 한다. 마찬가지로 spatial self-attention을 제거한 channel self-attention 변형인 Omni-SR_ca를 만든다. 이는 상당히 많은, 0.4dB 성능 저하를 초래한다. 또한 가장 많이 사용된 SE와 CBAM을 사용해 channel 및 spatial aggregatoin을 수행한다. 두 가지 결과는 전체 모델에 비해 각 0.22dB, 0.15dB 만큼 성능이 저하된다. 이 결과로 특정 상호작용 paradigm(scalar-based, covariance-based)이 똑같이 중요하다는 것을 보여주며, 공분산 행렬을 기반으로 한 channel 상호작용은 큰 이점을 보여준다.
4. Conclusion
- SR을 위한 lightweight framwork인 Omni-SR을 제안
- Omni 축 전체의 모든 잠재적 상관관계를 마이닝 하며 동시에 spatial and channel 상호작용을 위한 Omni Self-Attention paradigm을 제안
- 계산 복잡성이 낮은 receptive field를 효과적으로 확장하기 위해 omni scale aggregation 방법을 제안
- 이는 점진적인 계측정 방식으로 contextual 관계를 인코딩
- 실험적 결과에서 기존의 방법들보다 개선된 SR 성능을 보임
5. Supplementary Material
5.1 Detailed Network Architecture
Feedforward network와 LayerNorm을 사용해 전통적인 Transformer를 설계해서 OSA를 만든다. 기존의 것과 OSA의 차이점은 self-attention 연산이 OSA 연산으로 대체된것이다. FFN으로는 GDFN을 사용하고 OSA 블럭의 세부적인 사항은 아래 그림과 같다.
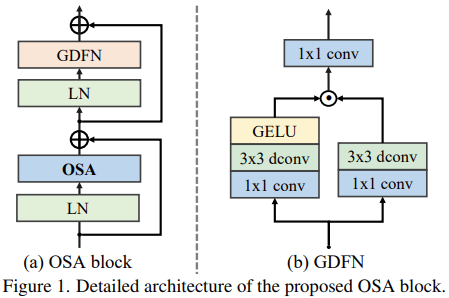
Omni-scale aggregation인 OSAG를 설계하기 위해 local-conv block, Meso-OSA block, Global-OSA block를 사용한다. OSAG는 총 5번 반복하며 그 크기는 5에서 1까지 792, 647, 502, 356, 211K 이다.
5.2 Impack of aggregation order
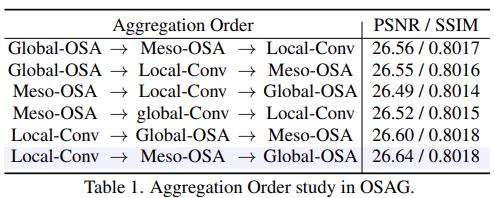
Local 부터 global까지 omni-scale 정보를 aggregation 하기 위해 3가지 다른 상호작용을 가진 모듈, local, meso, global을 가진 OSAG를 설계한다. 가장 효율적인 결합 방법을 찾기 위해 Urban100 데이터셋에서 4배 SR한 결과를 비교한다. 비교한 결과는 아래 표와 같다. 비교한 결과 local conv를 앞에 두는것이 다른 모델에 비해서 높은 성능을 보인다. 이는 local feature aggregation을 global aggregation 보다 먼저하는것이 효율적인것을 증명한다. 성능을 비교한 결과 Local, Meso, Global 순으로 feature를 aggregation하는것이 가장 높은 성능을 보인다.
5.3 LAM comparison
Omni-SR의 효율을 검증하기 위해 4배 SR하여 다른 lightweight 방법인 CARN, ESRT, SwinIR과 LAM 결과를 비교한다. 모델의 상호작용 능력을 연구하기 위해 LAM이 제안되고 상호작용 범위를 정량화 하기 위해 확산지수 DI를 사용한다. LAM 범위와 DI 값이 클수록 모델의 receptive field가 커지므로 성능이 향상된다. 비교한 그림은 아래 그림과 같다. Omni-SR이 CNN 기반 또는 transformer 기반 모델에 비해 가장 큰 LAM 범위 및 DI 값을 가져 제안된 omni-dimensional과 onmi-scale aggregation 방법의 효과를 검증했다.
Paper & Supplementary
'딥러닝 논문 리뷰' 카테고리의 다른 글
| The StarCraft Multi-Agent Challenge Review (0) | 2023.06.05 |
|---|---|
| LDC: Lightweight Dense CNN for Edge Detection Review (0) | 2023.06.01 |
| Adversarial Text Image Super-Resolution Using Sinkhorn Distance Review (1) | 2023.04.20 |
| Graph Neural Network in Image (3) (0) | 2023.04.19 |
| Graph Neural Network in Image (2) (0) | 2023.04.05 |



