
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- DIINN
- FRFSR
- Feature reuse
- implicit representation
- LIIF
- TAAM
- Cell-tissue
- Graph
- arbitrary scale
- ConvNeXt
- Zero-Shot sr
- deep learning
- TRANSFORMER
- GNN
- GNN in image
- Reference Super-Resolution
- INR
- hypergraph
- SISR
- Cityscapes
- Cell detection
- graph neural network
- SegFormer
- Referense Super Resoltuion
- Reference-based SR
- ADE20K
- Tissue segmentation
- CrossNet
- Super-Resolution
- session-based recommendation
- Today
- Total
딥러닝 분석가 가리
The StarCraft Multi-Agent Challenge Review 본문
"The StarCraft Multi-Agent Challenge"
Abstract
지난 몇 년동안 deep multi-agent reinforcement learning (RL)은 주목 받는 연구분야 이다. 이 분야에서 특히 어려운 문제는 부분적으로 관찰가능하고, 협력적인 multi-agent 학습이여야 한다. 에이전트 팀은 개인적인 관찰에만 의존하며 행동을 조정하는 방법을 배워야 한다. 이러한 문제는 많은 실제 시스템과 관련이 있고 일반-합 문제보다 평가하기 쉽기 때문에 매력적인 연구분야 이다.
ALE나 MuJoCo 같은 표준 환경은 single-agent RL이 toy 영역을 넘어 grid world 같은 곳으로 이동하는것을 허락한다. 하지만, 협력적인 multi-agent RL에 비교할만한 benchmark가 없다. 결과적으로 이분야의 대부분의 논문들이 one-off toy 문제를 사용하므로, 실제 progress를 측정하기가 어렵다. 그래서 본 논문에서는, 이러한 문제를 해결하기 위해 StarCraft Multi-Agent Challenge (SMAC) benchmark를 제안한다. SMAC는 인기있는 실시간 전략게임인 StarCraft II에 기반하고 local 관찰에 기반해 행동하는 독립적인 agent로 통제되는 각 유닛들을 미세하게 관리하는 것에 초점을 둔다. 다양한 challenge 시나리오를 제공하고 가장 최적의 행동과 평가를 제공한다. 또한, SotA 알고리즘은 포함한 deep multi-agent RL 학습 프레임워크를 제공한다. SMAC가 향후 몇년동안 표준적인 benchmark 환경을 제공할것이라 믿는다. SMAC 시나리오중 best agent는 다음 유트브 링크에서 확인할 수 있다.
Code is available at https://github.com/oxwhirl/smac
GitHub - oxwhirl/smac: SMAC: The StarCraft Multi-Agent Challenge
SMAC: The StarCraft Multi-Agent Challenge. Contribute to oxwhirl/smac development by creating an account on GitHub.
github.com
Code is available at https://github.com/oxwhirl/pymarl
GitHub - oxwhirl/pymarl: Python Multi-Agent Reinforcement Learning framework
Python Multi-Agent Reinforcement Learning framework - GitHub - oxwhirl/pymarl: Python Multi-Agent Reinforcement Learning framework
github.com
Youtube demo link : https://youtu.be/VZ7zmQ_obZ0
Introduction
Deep reinforcement learning (RL)은 임의의 순차적인 결정 문제를 해결하기 위해 확장 가능한 접근 방법을 보장하며, 사용자가 원하는 행동을 표현하는 reward function을 지정해야 한다고 요구한다. 하지만, RL로 다뤄질 수 있는 많은 실제 세계의 문제는 본질적으로 multi-agent 이다. 예를들어, 자율주행, 드론 자율주행, multi-robot 시스템은 점점 더 중요해지고 있다. 네트워크 traffic routing, 센서 분배, 에너지 분배, 다른 논리적인 문제 또한 본질적으로 multi-agent이다. 그래서 분산된 제약을 처리하고 기하급수적으로 증가하는 많은 에이전트의 공동 작업 공간을 처리할 수 있는 multi-agent RL (MARL)의 개발은 필수적이다.
부분적으로 관찰가능하고, 협력적인 multi-agent learning 문제는 특별한 관심을 받고 있다. 협력적인 문제는 종합 게임에 있는 평가상의 어려움을 피한다. 협력적인 문제는 또한 분산 시스템을 관리하는 단일 사용과 전체 목표를 지정할 수 있는 많은 중요 문제들에 잘 대응된다. 예를들어 이러한 문제는 traffic이나 다른 비효율을 최소화 하는것 이다. 대부분의 real-world 문제는 노이즈가 있거나 제한된 센서의 입력에 의존하므로 부분적인 관찰 가능성에도 효율적이여야 한다. 이것은 종종 학습된 정책의 분산된 실행을 필요로 하는 의사소통에서 한계를 가진다. 하지만, 일반적으로 훈련 중에 추가적인 정보에 접근할 수 있고, 이는 제어된 조건 혹은 상황에서 수행될 수 있다.
최근 연구들은 이러한 문제점들을 해결하기 시작했다. 하지만, 연구와 평가를 위한 표준화된 benchmark가 부족하다. 대신에, 연구자들은 종종 지나치게 단순하거나 제안된 알고리즘에 맞춰 조정될 수 있는 one-off 환경을 제안한다. Single-agent RL의 Arcade Learning Environment (ALE)나 계속적인 제어를 위한 MuJoCo같은 표준화된 환경은 큰 발전을 가능하게 했다. 본 논문에서는, 이러한 성공적인 모델을 따라 deep MARL를 위한 challenging standard benchmark를 제공하고 전체에 걸쳐 보다 엄격한 실험 방법론을 용이하게하는것을 목표로 한다. Multi-agent 체제를 위한 몇가지 testbed가 등장했지만, 위에서 설명한 중요한 집합을 위한 challenging하고 표준적인 testbed에서 분명한 격차를 식별한다.
이러한 차이를 메우기 위해 StarCraft Multi-Agent Challenge (SMAC)를 소개한다. SMAC는 실시간 전략 게임인 StarCraft II에 기반하고 SC2LE 환경을 사용해 만든다. 중앙 집중식 제어로 StarCraft의 전체 게임을 해결하는 대신 그림 1처럼 분산된 미세적인 관리 문제에 초점을 맞춘다. 이 challenge에서 각 유닛은 독립적으로 제어되고, 상대편 유닛이 손으로 코딩된 AI에 의해 제어되는 동안 학습된 agent는 local 관찰에 기반한다. 알고리즘이 고차원 입력과 부분적 관찰 가능성을 처리하고 완전히 분산된 실행으로 제한되는 경우에도 조정된 행동을 학습하도록 challenge 알고리즘인 다양한 시나리오를 제공한다.

StartCraft: BroodWar와 StarCraft II 는 이미 RL 환경에 사용되었다. DeepMind의 AlphaStar는 최근 중앙 집중식 제어를 사용한 인상적인 수준의 플레이를 보여주었다. 대조적으로, SMAC는 StarCraft II 게임 전체에서 사용할 agent를 훈련하기 위한 환경으로 의도되지 않았다. 제한된 분산과 local partial 관찰 가능성을 소개하는것 대신에, 학습의 nonstationarity, multi-agent 신뢰 조정, 공동 행동 값 표현의 어려움과 같은 독특한 challenge를 가져다주는 rich cooperative multi-agent 문제의 새로운 집합을 설계하기 위해 StarCraft II 게임 엔진을 사용한다.
이 분야의 연구를 더욱 유용하게 하기 위해, 또한 다른 연구자의 출발점이 될 수 있는 몇가지 주요 MARL 알고리즘의 구현을 포함하는 학습 framework인 PyMARL을 공개한다. PyMARL은 모듈식이고 확장 가능하며 PyTorch 기반으로 구축, 그리고 실제 deep MARL의 고유한 문제를 처리하기 위한 template 역할을 한다. QMIX와 몇가지 기본 알고리즘을 사용하는 SMAC 환경의 결과를 포함하고, communtity가 지금까지 좋은 성능이 미치지 못하는 어려운 환경에서 진전을 이루도록 한다. 또한, 표준화된 성능 metrics, 샘플 효율성 및 계산적인 요구사항(Appendix B)을 포함해 benchmark를 사용한 평가에서 가이드라인을 제공한다.
Multi-Agent Reinforcement Learning
SMAC 에서는 agent의 팀이 공통적 목표를 달성하기 위해 협업 하는것을 목표로 하도록 초점을 맞춘다. Dec-POMDPs와 같은 fully cooperative multi-agent task의 형식주의를 간단히 평가하지만 reader에게 더 완전한 그림을 위해 Onlinehoek & Amato를 참조한다.
Dec-POMDPs
RL에서 agent는 주어진 환경에서 행동을 하고 행동에 대한 결과를 보상으로 받는다. Decentralized Partially Observale Markov Decision Processes (Dec-POMDPs)는 환경이 여러개의 agent로 구성되어 있을 때, agent들이 서로에게 영향을 주면서 행동하는 상황을 모델링 한것이다. Dec-POMDPs에서는 각 agent는 다른 agent가 수행한 행동에 대해서 미리 알 수 없고, agent가 관측한 환경에 대해서도 불완전한 정보를 가지기 때문에 partially observable한 성격을 가진다.
Dec-POMDPs는 multi-agent 시스템에서 각 agent가 개별적으로 자신의 상태와 행동을 선택하면서 그 결과를 통해 최적의 결정을 내리는 프레임워크로 이는 tuple G = <S, U, P, r, Z, O, n, γ>를 사용한다. 각 요소는 다음과 같다.
- S : State(상태) 집합으로, 환경의 실제 상태를 s ∈ S 로 나타낸다.
- U : Action(행동) 집합으로 각 agent a ∈ A ≡ {1 ~ n}는 행동 u^a ∈ U를 선택하여 합동 행동 u ∈ U ≡ U^n을 만든다.
- P : State Transition Function(상태 전이 함수)로, P(s'|, u) : S × U × S → [0, 1]는 합동 행동 u가 주어졌을 때, 상태 s에서 상태 s'로 전환될 확률을 나타낸다.
- r : Team Reward Function(팀 보상 함수)으로, r(s, u) : S × U → R는 모든 에이트가 공유하는 보상 함수입니다. γ ∈ [0, 1)는 할인 계수이다.
- Z : Observation(관측) 집합으로, 각 에이전트는 각 시간 스텝마다 z_a ∈ Z 관측 값을 가진다.
- O : Observation Function(관측 함수)로, O(s, a) : S × A → Z는 각 에이전트가 각 time step마다 관측하는 관측치 z_a를 결정한다.
- n : 에이전트 수로, 전체 에이전트의 수를 나타낸다.
- γ : Discount Factor(할인 계수)로, 각 에피소드의 미래 보상을 현재 시간에 할인하여산하는데 사용된다.
이러한 요소를 바탕으로, 각 agent는 자신의 action-observation 이력 τ a ∈ T ≡ (Z × U) * 을 바탕으로 확률적 정책 π a (u a |τ a ) : T × U → [0, 1]을 만든다. 여기서 *는 Kle star(클레인 스타)로 가능한 모든 순열과 길이의 벡터 집합이다. 결국 joint 정책인 π는 action-value 함수 Qπ (st, ut) = Est+1:∞,ut+1:∞ [Rt|st, ut]를 생성하며, Rt = P∞ i=0 γ i rt+i는 할인된 반환값이다. 이를 통해 최적화를 시도한다.
Centralized training with decentralized execution
Centralised training with decentralised execution (CTDE)는 강화 학습 알고리즘에서 주로 사용되는 전략으로 학습이 시뮬레이션 혹은 환경에서 진행되는 경우, centralized 학습이 이루어지는데, 이는 multi agent가 학습 중에 모든 local 정보와 global 상태를 공유 할 수 있게 해주는 방법이다. 그러나 각 agent의 실행은 decentralized 방식으로 진행되어, 학습된 각 agent의 정책은 자신만의 local 관측에만 의존한다. 즉, 알고리즘 훈련 중에는 모든 agent의 관측정보를 이용하고 실험 과정에서는 각 agent 자신의 관측 정보만을 이용해 실행하는것이다.
만약 학습이 StarCraft II 또는 실험실 에서 수행되는것 처럼 시뮬레이션에서 진행되는 경우, 일반적으로 centralized 방식으로 수행될 수 있다. 이는 planning community에서 잘 연구된 CTDE를 야기한다. 비록 훈련이 centralized 이지만, 실행은 decentralized 이다. 즉, 학습 알고리즘은 모든 local action-observatoin history τ 및 global 상태 s 에 접근할 수 있지만, 각 agent의 학습된 정책은 오직 자신의 action-observation history τ^a 에만 조건을 붙일수 있다.
최근 많은 SotA 알고리즘은 decentralized 정책의 학습 속도를 높이기 위해 centralized 훈련에서 사용할 수 있는 추가적인 정보를 사용한다. 이중 COMA는 특별한 multi-agent critic baseline을 가진 actor-critic 알고리즘이고, QMIX는 Q-learning 계열이다.
SMAC
SMAC 는 인기있는 실시간 전략 게임인 StarCraft II에 기반한다. StarCraft II는 한 명 이상의 인간이 자원을 모으고, 건물을 짓고, 상대를 물리치기위해 유닛 군대를 구축하는 게임으로 서로 또는 내장된 AI와 경쟁한다. 대부분의 실시간 전략과 유사한 StarCraft는 게임 플레이에 있어 두가지 주요 요소인 macromanagement와 micromanagement가 있다. Macromanagement는 경제 및 자원 관리와 같은 높은 수준의 전략적 고려사항이고 Micromanagement는 유닛들을 세밀하게 제어하는 것이다. StarCraft는 AI 그리고 최근에는 RL의 연구 플랫폼으로 사용되고 있다. 일반적으로 게임은 경쟁적인 문제로 구성된다. Agent는 인간 플레이어의 역할을 맡아 macromanagement를 하고 중앙 집중식 제어에서 micromanagement를 해 개별 유닛에 명령을 내린다.
Rich multi-agent testbed를 구축하기 위해 단지 micromanagement에만 초점을 맞춘다. Micro는 StarCraft 게임 플레이의 중요한 측면으로 높은 기술 상한선이 있으며 아마추어와 프로선수로 나눠진다. SMAC의 경우, decentralized 제어를 위해 설계된 문제의 수정된 버전을 제안해 micromanagement의 자연스러운 multi-agent 구조를 활용한다. 부분적으로, 그림 2 처럼 각 유닛이 제한된 지역 중심으로 local 관측에만 조건을 두는 독립적인 agent에 의해 제어되어야 한다. 이 agent의 그룹은 어려운 전투 시나리오를 해결하기위해 훈련되어져 게임에 내장된 scripted AI의 centralized 제어하에 상대 군대와 싸워야 한다. 전투중 유닛의 적절한 미세한 움직임은 적 유닛에 주는 데미지를 극대화 하고 동시에 받는 피해를 최소화하고 다양한 스킬을 필요로 한다. 예를 들어, 가장 중요한 기술은 집중 공격이다. 즉, 유닛들이 차례로 적 유닛들을 공동으로 공격하는 명령이다. 다른 일반적인 micro 기술은 유닛을 armour 유형에 따라 대형으로 조립하는것, 아군 유닛이 피해를 거의 입지 않도록 적 유닛과 충분한 거리를 유지해 피해를 입히는것, 다른 방향에서 공격할 유닛의 위치를 조정하거나 지형을 이용하는것이 있다.

그래서 SMAC는 MARL 알고리즘의 효율성을 검증하기위해 편리한 환경을 제공한다. 시뮬레이션된 StarCraft II 환경과 조심스럽게 설계된 시나리오는 어려운 task의 부분적인 관측가능한 지점에서 협력적인 행동을 배우는것을 요구한다. 시뮬레이션된 환경은 또한 전체 맵에 있는 모든 유닛의 정보와 같은 훈련 동안 추가적인 상태 정보를 제공한다. 이것은 facilitating 알고리즘에서 MARL 방법의 모든 측면을 평가하고 centralized 훈련 체제를 최대한 활용하기 위해서 중요하다. SMAC는 부분적인 관찰 가능성, challenging dynamic 그리고 고차원의 관측 공간의 요소를 함께 제공하는 질적으로 어려운 환경이다.
Scenarios
SMAC는 독립적인 agent들이 complex task를 해결하기 위해 협력하는것을 어떻게 잘 배우는지를 평가히는것에 목적을 둔StarCraft II micro 시나리오의 집합으로 구성된다. 이러한 시나리오들은 적을 제거하기 위해 하나 이상의 micromanagement 기술을 학습해야 할 정도로 신중하게 설계되었다. 각 군대의 초기 위치, 수, 유닛 종류는 시나리오에 따라 다르며, 상승하거나 통과할 수 없는 지형의 유무도 다르다. 위의 그림 1은 SMAC micro 시나리오의 몇가지를 캡쳐한 사진이다.
첫번째 군대는 학습된 allied agent에 의해 제어된다. 두번째 군대인 적 유닛은 수작업으로 만들어진 학습되지 않은 휴리스틱을 사용하는 내장 게임 AI에 의해 제어되고 구성된다. 각 에피소드의 시작은 게임 AI가 유닛들에게 scripted 전략을 사용해 allied agent가 공격하도록 지시한다. 에피소의 끝은 한 군대의 모든 유닛이 죽었거나 지정된 시간 제한에 도달했을 때이다. 제한 시간에 도달했을 때는 allied agent의 패배로 간주된다. 학습의 목표는 승률을 최대하 시키는것 이다. Challenge는 표1과 같고, SMAC의 더 많은 시나리오와 환경 세팅은 부록 A.1과 A.2에 나타난다.

State and Observation
각 timestep 마다, agent는 그들이 field에서 본 local 관측을 받는다. 이것은 위의 그림 2와 같이 각 장치 주변의 원형 영역 내에서 반경이 시야 범위와 동일한 맵에 대한 정보가 포함된다. 시야 범위는 각 agent의 관점에서 환경을 부분적으로 관찰할 수 있도록 한다. Agent는 다른 agent가 활성 상태이고 시야 범위 내에 있는 경우에만 관찰할 수 있다. 따라서 agent는 죽은 팀원과 멀리 떨어져있는 팀원들을 구별할 방법이 없다.
Feature vector는 시야 범위 내의 각 agent가 포함되는 팀원과 적 둘의 속성(distance, relative x, relative y, health, shield, unit type)을 관찰한다. Shield는 유닛의 health에 데미지를 주기 전에 제거해야하는 추가적인 보호요소이다. 모든 Protos 유닛은 shield를 가지고 있고 데미지를 받고있지 않다면 이것은 재생된다. 추가적으로 agent는 시야에 있는 allied 유닛의 마지막 행동에 접근할 수 있다. 마지막으로, agent는 지형 특성, 특히 높이와 보행성을 나타내는 고정된 반경의 8개 지점의 값을 관찰할 수 있다.
Global 상태, agent가 centralized 학습 중에만 접근가능한, 는 맵에 있는 모든 유닛의 정보를 포함한다. 구체적으로, 상태 vector는 관측지에 존재하는 unit feature와 함께 맵의 중심에 상대적인 모든 agent의 좌표를 포함한다. 또한, 상태는 Medivacs의 에너지와 나머지 allied unit의 cooldown을 저장하고 이는 공격 사이의 최소 지연을 나타낸다. 마지막으로, 모든 agent의 마지막 행동은 중앙 상태에 연결된다.
상태와 개별 agent의 관찰 둘다에서 모든 feature는 최대값에 의해 정규화 된다. 시야 범위는 모든 agent에 대해 9로 설정된다.
Action Space
Agent가 수행할 수 있는 개별 작업은 동, 서, 남, 북 4방향으로 이동, 공격 및 멈춤 그리고 죽은 agent에 대한 no-op 행동이 있다. 힐러 유닛인 Medivacs는 공격 대신 heal 작업을 사용한다. 시나리오에 따라 최대 action 수는 7에서 70사이 이다. 작업의 decnetralization을 보장하기 위해 agent는 사격 범위 내에 있는 적에 대해서만 공격을 할 수 있다. 이것은 추가적으로 멀리 있는 적들에게 내장된 attack-move macro-action을 사용하는 장치의 능력을 제한한다. 모든 agent들의 사격 범위를 6으로 설정했다. 사격 범위 보다 시야가 넓기 때문에 agent는 사격 하기 전에 이동 명령을 사용해야 한다.
Rewards
각 battle 시나리오에서 승률을 최대화 하는것이 목표이다. 기본 세팅은 전투에서 승리한 경우 특별 보너스와 함께 적중한 대상 및 사망한 적 유닛에 대한 보상을 생성하는 shaped reward를 사용한다. 이러한 이벤트의 각 정확한 값과 척도는 flag 범위를 사용해 설정할 수 있다. 공평한 비교를 하기 위해 모든 시나리오에 대해 이러한 기본 reward 함수를 사용한다. 또한 에피소드에서 승리시 +1, 패배시 -1을 부여하는 다른 sparese reward 옵션을 제공한다.
PyMARL
SMAC를 위해 좀 더 쉬운 알고리즘을 개발하기 위해, PyMARL이라는 sw 엔진을 공개한다. PyMARL은 deep MARL을 염두에 두고 명시적으로 설계되었으며 추후 실험 및 개발이 가능하다. PyMARL의 코드 베이스는 새로운 알고리즘의 신속한 개발을 가능하게 할 뿐만 아니라, benchmark할 현재의 deep MARL 알고리즘의 구현을 제공하기 위해 module 식으로 구성된다. PyTorch 위에 구축되어 deep neural network의 빠른 실행과 훈련을 용이하게 하고 주변에 구축된 rich ecosystem의 이점을 활용한다. PyMARL의 모듈화로 쉽게 확장할 수 있으며 구성 요소를 테스트 목적으로 쉽게 분리할 수 있다.
Deep MARL 알고리즘의 구현 및 개발은 single agent deep RL에 의해 제기되는것 이상의 많은 추가적인 과제를 수반하기 때문에 간단하고 이해할 수 있는 코드를 가지는것이 중요하다. 코드의 가독성을 개선하고 데이터 처리를 단순화 하기 위해 PyMARL은 버퍼에 저장된 모든 데이터를 사용하기 쉬운 데이터 구조로 캡슐화 한다. 이 캡슐화는 PyTroch Tensor의 조작을 방해하지 않으면서 deep MARL 알고리즘에서 데이터를 처리하는데 필요한 인터페이스를 제공한다. 또한, PyMARL은 추론 또는 학습을 수행할 때 데이터 배치를 최대화 하여 보다 단순한 구현에 배해서 상당한 속도 향상을 제공하는것이 목표이다. PyMARL은 다음과 같은 알고리즘이 구현되어 있다: QMIX, QTRAN, COMA, VDN, IQL.
Results
이 세션에서는 SMAC 시나리오에 대한 결과를 나타낸다. 이 결과의 제시는 논문에서 선택한 MARL 방법들인 현재 SotA 방법의 성능을 증명한다. Agent가 decentralized 방식으로 greedily action 선택을 수행할 때 32개의 test 에피소드가 실행되는 기간 동안 10,000회 단계마다 훈련이 일시 중지된다. Agent가 허용된 시간 내에 모든 적 유닛을 제거하는 에피소드의 비율을 테스트 승률 이라고 한다. 구조 및 훈련에 대한 자세한 사항은 Appendix C에 나타난다. Appendx D에 있는 표 A는 결과 표 이다. 개별 실행 데이터는 SMAC repo 에서 확인할 수 있다. (https://github. com/oxwhirl/smac)
그림 3은 전체 SMAC의 알고리즘을 비교하기 위해 모든 시나리오에서 평균 테스트 승률의 중위수를 표시한것이다. 또한 가장 가까운 적 유닛을 선택하고 (부분적인 관찰 가능성을 무시) 그 유닛이 죽을때 가지 팀 전체와 함께 공격하는 간단한 휴리스틱 AI의 성능을 보여준다. 이것은 기본적인 foucs-firing으로 micromanagement 시나리오에서 좋은 성능을 달성하기 위한 중요한것이다. 휴리스틱 AI의 상대적으로 낮은 성능을 보여주는 SMAC 시나리오는 가까운 적을 순진하게 집중 사격하는것 보다 더 복잡한 행동을 필요로 한다는것을 보여주며, 이는 흥미롭고 challenging한 benchmark가 된다.

QMIS는 가장 높은 테스트 승률을 달성하며 훈련중 최대 8개의 시나리오에서 최고의 성능을 발휘 한다. 또한 IQL, VDN 및 QMIX는 모두 COMA를 크게 능가해 정책에 따른 가치기반 방법이 정책에 따른 gradient방법에 비해 더 뛰어난 샘플 효율성을 보여준다. 결과를 바탕으로 시나리오를 알고리즘을 기반으로한 Easy, Hard, Super-Hard 3가지 카테고리로 분류한다.
그림 4는 Easy 시나리오 중 IQL과 COMA가 어려움을 겪고 있는것을 보여주며 총 5개의 시나리오중 4개의 시나리오에서 낮은 성능을 보인다. 이는 centralized 이지만 factored centralized인 Q_tot 학습의 이점을 보여준다. 심지어 QMIX는 5개 시나리오 모두 95% 이상의 테스트 승율을 달성하지만, 새로운 알고리즘을 구현하고 테스트할때 sanity(건정성) 검사로서 benchmark에서 중요한 역할을 한다.

그림 5의 Hard 시나리오는 알고리즘의 독특한 문제를 나타낸다. 2c_vs_64zg는 오직 2개의 allied agents를 포함하지만 64개의 적 유닛이 agent의 action space를 다른 시나리오 보다 더 크게 만든다. bane_vs_bane는 많은 수의 allied와 적 유닛을 포함 하지만, 결과는 IQL이 다른 모든 방법보다 쉽게 성공 전략을 찾을수 있다. 5m_vs_6m은 비대칭 시나리오로 지속적인 승리를 위해 정밀한 제어가 필요하며, QMIX와 VDN이 좋은 성능을 내었다. 마지막으로 3s_vs_5z은 3개의 allied agnet가 에피소드 동안 적을 카이팅 해야하고 이는 보상의 지연 문제로 이어진다.

그림 6에 표시된 Super Hard 시나리오는 모든 알고리즘의 성능이 좋지않고, 그중 QMIX만 5개 중 2개에서 의미있는 성능을 보인다. 저자는 탐사가 이러한 많은 시나리오에서 병목현상이며, 이 영역에서 향후 연구를 위한 좋은 testbed를 제공한다고 가정한다.

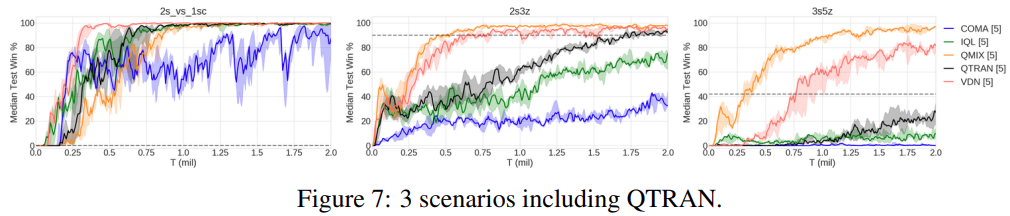
또한 QTRAN을 3개의 Easy 시나리오에서 테스트하고 이는 그림 7에 나타난다. QTRAN은 3s5z에서 좋은 성능을 달성하는것을 실패 했고, 2s3z에서는 VDN과 QMIX과 비슷해지기 위해 많은 시간이 걸렸다. 예비 실험에서 QTRAN-Base 알고리즘이 QTRAN-Alt 보다 약간 더 성능이 좋고 안정적 이라는것을 발견했다. 하이퍼 파라미터와 구조에 대해서 더 자세한 설명은 부록에 있다.
또한, 그림 8에서 RNN이 있는 agent network와 없는 agent network의 성능을 비교해 agent의 action-obsertation history를 사용할 필요성을 비교한다. 3s5z의 Easy 시나리오에서 RNN이 이전 timestep의 action-observation 정보를 사용할 필요가 없는것을 알 수 있지만, 3s_vs_5z의 Hard 시나리오 에서는 kite를 효과적으로 배우는것이 중요하다.

Conclusion and Future Work
- 이 논문은 SMAC를 협력적인 MARL benchmark 문제 집합으로 제시
- 실시간 전략 게임인 StarCraft II를 기바으로 SMAC는 decentralized micromanagement 작업에 초점을 맞추고 부분적인 관찰 가능성과 고차원적인 입력을 처리하기 위한 MARL 방법에 challenge하는 14가지 다양한 전투 시나리오를 특징으로 함
- 표준화된 성능 metrics을 사용한 평가서의 권장 사항을 제공하고 QMIX와 COMA와 같은 SotA MARL 알고리즘에 대한 report와 논의를 제공
- 추가적으로, Deep MARL 알고리즘 설계 및 분석을 위한 framework인 PyMARL을 제공
- 미래에 더 다양한 유닛 세트를 특징으로 하고 agent간의 더 높은 수준의 조정이 필요한 새로운 challenge 시나리오를 가진 SMAC로 확장하는것이 목표 (더 다양한 스킬과 풍부한 지형을 활용할 수 있도록)
- 더 어려운 multi-agent 조정 문제로 기존 MARL 접근 방식의 격차를 탐색하고 특히 multi-agent 탐색 및 조정과 같은 영역에서 이 영역의 추가 연구에 동기를 부여한느것이 목표
Appendix
A. SMAC
A.1 Scenarios
아마 가장 간단한 시나리오는 같은 유닛으로 구성된 두 군대가 싸우는 대칭적 시나리오다. 몇개의 challenge, 어떠한 유닛이 다른 적에게 매우 효율적인것을 보이는(countering) 특히 흥미롭다. 이러한 환경에서 allied agents는 게임의 이런 속성을 추론하고 특정 적의 공격에 취약한 팀원을 보호하기 위한 지능적인 전략을 설계해야 한다. SMAC는 또한 더 challenging한 시나리오를 포함한다. 예를들어, 적군이 아군을 하나 이상의 유닛이 더 많은 경우이다. 이러한 비대칭 시나리오에서는 원하는 상대를 효과적으로 겨냥하기 위해 적의 health를 고려하는것이 필수적이다.
마지막으로 SMAC는 더 높은 수준의 협력과 적을 물리치기위한 micro-trick을 요구하는 흥미로운 micro-trick challenge를 제공한다. 이러한 시나리오는 그림 1c와 같다. 여기서 6명의 우호적인 질럿이 24마리의 저글링을 마주하는데, 이는 agent가 지형적 특징을 효과적으로 활용해야 한다는것이다. 특히, agent는 서로 다른 방향에서 적의 공격을 차단하기 위해 choke point(지도의 좁은영역)을 일괄적으로 차단해야 한다. 3s_vs_5z 시나리오에서는 그림 1b와 같이 3개의 Stalker에게 대항하는 5명의 질럿이 있는것이 특징이다. 질럿이 stalker의 카운터이기 때문에 allied 유닛이 이기기위한 전략은 맵을 따라 kite하며 적을 죽이는것이다. Micro-trick challenge중 일부는 블리자드가 출시한 StarCraft Master challenge mission에 영감을 받았다.
A.2 Environment Setting
SMAC는 StarCraft II 학습 환경(SC2LE)과 통신하기 위해 StarCraft II 엔진을 사용한다. SC2LE는 게임에서 명령을 보내고 관찰을 수신할 수 있도록 게임을 완전히 제어한다. 하지만, SMAC는 SC2LE의 RL 환경과는 개념적으로 다르다. SC2LE의 목표는 StarCraft II의 풀 게임을 배우는것이다. 이는 centralized RL agent가 RGB 픽셀을 입력으로 받아 인간 플레이어와 유사한 플레이어 수준 제어로 macro와 micro 모두 수행하는 경쟁 작업이다. 반면에, SMAC는 각 학습 agent가 single military 유닛을 제어하는 일련의 multi-agent micro challenge를 나타낸다.
SMAC는 SC2LE의 raw API를 사용한다. Raw API의 관찰은 어떠한 그래픽적인 요소가 없고 상태, 위치 좌표 등과 같은 지도 상의 단위에 대한 정보가 포함된다. Raw API를 사용하면 장치 ID를 사용해 개별 장치에 작업 명령을 전송할 수 있다. 이 설정은 인간이 실제 게임을 하는 방식과는 다르지만 decentralized multi-agent learning task을 설계하는데 편리하다.
게다가 agent가 자체적으로 흥미로운 micro 전략을 탐색하도록 장려하기 위해, agent에 대한 StarCraft AI의 영향을 제한한다. StarCraft II 에서는 idle 유닛이 공격을 받을 때마다 명시적인 명령 없이 자동으로 공격하는 적 유닛에 대한 응답 공격을 한다. 두가지 속성이 수정된 기종 장치의 정확한 복사본인 새 장치를 만들어 근접한 위치에 있는 적 공격이나 적 유닛에 대한 이러한 자동 응답을 비활성화 한다. 이러한 필드는 아군에게만 적용되며 적군 유닛은 변경되지 않는다.
시야 및 사격 범위 값은 일부 StarCraft II 장치의 내장 시야 또는 사격 범위 속성과 다를수 있다. 목표는 원래의 전체 StarCraft II 게임을 마스터 하는것이 아닌 decentralized 제어를 위한 MARL 방법을 benchmark 하는것 이다. 게임 AI는 7 단계로 설정 : very difficult. 그러나 실험은 이 설정이 내장된 휴리스틱의 유닛 micromanagement에 상당한 영향을 미친다.
B. Evaluation Methodology
SMAC를 사용해 MARL 방법을 검증하는 방법을 제시한다. 결과의 비교가능함과 challenge를 공평하게 보장하기 위해, 성능은 표준적인 조건 아래에서 검증된다. 정책 평가에 사용되는 환경을 변경해서는 안된다. 이것은 관찰과 상태 공간, 행동 공간, 게임 메커니즘, 그리고 환경 설정이 포함된다. StarCraft II의 맵을 수정하거나 게임 AI의 난이도를 변경해서는 안된다. 또한 각 시나리오의 에피소드 제한도 변경되지 않아야 한다. SMAC는 훈련된 모델의 실행을 분산화 하도록 제한한다. 즉, 테스트 중 각 에이전트는 자신의 action-observation 이력에만 기반해야 하고 global state나 다른 agent의 관찰을 사용할 수 없다. 하지만, decentralized 정책을 centralized 훈련에 사용하는것은 허용된다. 특히, agent는 훈련중 개별 관찰, 모델 매개변수 그리고 gradient를 교환할 수 있을 뿐만 아니라 전역 상태를 활용할 수 있다.
B.1 Evaluation Metrics
주된 평가 방법은 훈련 과정에서 관찰된 환경 단계의 함수로써 평가 에피소드의 평균 승률이다. 이러한 progress는 탐색 행동이 비활성화된 상태에서 고정된 수의 평가 에피소드(32)를 주기적으로 실행해 추적할 수 있다. 각 실험은 여러 개의 독립적인 훈련의 실행을 사용해 반복되며 결과 그림에는 중위수와 25~75% 백분위수가 포함된다. 통계적 유의성과 계산 요구사항 사이의 균형을 맞추기 위해 이 목적의 독립적인 실행 5가지를 사용한다. 이상치의 영향을 피하기 위해 평균대신 중위수를 사용하는것을 추천한다. 훈련에 사용된 환경 단계 뿐만 아니라 독립적인 실행의 수를 보고한다. Nvidia Geforce GTX 1080 Ti를 사용하는 경우 각각의 독립 실행은 정확한 시나리오에 따라 8시간에서 16시간이 걸린다.
연산용 자원을 사용하는 것과 각 실험의 실행 시간을 측정하는것을 포함하는것은 다른 연구자에게 도움이 될 수 있다. SMAC는 무료로 사용 가능한 클라이언트를 사용해 볼 수 있는 StarCraft II 재생을 저장하는 기능을 제공한다. 결과 비디오를 사용해 관찰된 흥미로운 행동에 대해 설명할 수 있다.
C Experimental Setup
C.1 Architecture and Training
모든 agent 네트워크의 구조는 fully-connected layer 전과 후에 64개의 차원을 가진 GRU로 구성된 DRQN이다. Exploration은 각 agent가 입실론 greedy 행동 선택을 수행하는 독립적인 입실론 greedy 행동 선택을 사용하는 훈련동안 수행된다. 훈련 동안 입실론을 선형적으로 1.0 부터 0.05까지 50K 번째 time step 마다 낮추고 남은 학습동안 그 값을 유지하도록 한다. 모든 실험에 discount factor는 0.99로 설정한다. Replay buffer는 최근 5000번의 에피소드를 포함한다. Replay buffer에서 32개의 에피소드의 배치를 균일하게 샘플링 하고, 모든 에피소드가 끝난 후 single gradient descent를 수행해 완전히 전개된 에피소드에 대해 훈련한다. Note : 이는 8회 마다 한 번씩 교육을 받은 SMAC의 이전 베타 릴리즈와는 다르다. Target 네트워크는 200회 교육 에피소드 마다 업데이트 된다.
학습 속도를 향상시키기 위해, 모든 agent를 따라 agent의 네트워크의 파라미터를 공유하도록 한다. 이러한 이유는 agent id의 one-hot 인코딩이 각 agent의 관찰과 연결되기 때문이다. 모든 신경망은 learning rate 5 × 10^-4를 사용한 RMSprop로 훈련된다. Mixing 네트워크는 ELU를 사용해 32 unit을 가진 single hidden layer로 구성된다. Hypernetwork는 ReLU를 가지고 64unit를 가진 single hidden layer로 구성된다. Hypernetwork의 출력은 absolute 함수를 통과한 다음 적절한 크기의 matrix 로 크기가 조정된다.
COMA critic 의 구조는 128개의 unit을 가진 fully-connected 신경망을 feedforward하고 마지막 layer는 |U| unit을 따른다. λ는 0.8로 설정한다. Agent의 정책을 위해 선형적으로 입실론이 0.5부터 0.01까지 100K timestep 마다 낮아지는 same 입실론-floor 방법을 사용한다. COMA를 위해 8개의 에피소드를 roll-out하고 그 에피소드를 훈련한다. Critic은 첫번째 업데이트때 에피소드에서 각 timestep 마다 gradient descent step을 수행한다. 이를 처음부터 최종 단계까지 수행한다. 그런 다음 agent 정책은 모든 8개 에피소드의 데이터에 대해 single gradient descent step으로 업데이트 된다.
QTran의 centralized Q 구조는 다음과 비슷하다 (?). Agent hidden state (64 unit)은 그들이 선택한 |U| unit과 연결되고 한개의 hidden layer 와 ReLU를 통해 agent-action 임베딩 (64+|U| unit)을 생성한다. 이 네트워크는 모든 agent 간에 공유 된다. 임베딩은 모든 agent에서 합산 된다. state의 연결과 임베딩의 합은 Q 네트워크를 통과한다. Q 네트워크는 ReLU와 64개의 unit을 가진 2개의 hidden layer로 구성된다. 네트워크 V는 state를 입력으로 사용하고 ReLU와 64개의 unit으로 구성된 2개의 hidden layer로 구성된다. λ_opt = 1 and λ_nopt_min = 0.1로 설정한다. 또한, state와 one-hot 벡터로 인코딩 된 joint-action을 입력으로 사용하는 COMA 스타일 구조와 비교했다. 두 네트워크를 3개의 hidden layer로 수정에 테스트 한다. 두 네트워크 크기와 구조 변형에 대해 λopt = 1 and λnopt_min = {0.1, 1, 10}에서 3개의 QTran 맵 중 최상의 성능을 제공하는 모든 설정을 선택했다.
C.2 Reward and Observation
모든 실험은 모든 시나리오에서 기본 보상을 사용한다. 각 timestep에서 agent는 대상의 체력 데미지에 해당하는 긍정적이 보상과 각 적 유닛을 죽이고 시나리오을 이긴 경우 10점과 200점의 보너스를 받는다. 보상은 각 시나리오에서 달상할 수 있는 최대 누적 보상이 약 20개가 되도록 조정한다.
실험에 사용된 agent 관측에는 연합 유닛의 마지막 동작, 지형 높이 및 보행성을 제외한 SMAC절의 모든 기능이 포함된다.
D Table of Results
표 2는 테스트된 알고지므의 최종 중앙값 성능을 보여준다. 휴리스틱 기반의 AI에 대한 1000개 에피소드에 걸친 평균 승률도 표시된다.

'딥러닝 논문 리뷰' 카테고리의 다른 글
| SegFormer Review (0) | 2023.07.03 |
|---|---|
| OCELOT: Overlapped Cell on Tissue Dataset for Histopathology Review (0) | 2023.06.27 |
| LDC: Lightweight Dense CNN for Edge Detection Review (0) | 2023.06.01 |
| Omni Aggregation Networks for Lightweight Image Super-Resolution Review (1) | 2023.05.29 |
| Adversarial Text Image Super-Resolution Using Sinkhorn Distance Review (1) | 2023.04.20 |



