
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Referense Super Resoltuion
- SegFormer
- Reference Super-Resolution
- TAAM
- implicit representation
- Cityscapes
- FRFSR
- INR
- hypergraph
- ConvNeXt
- GNN in image
- graph neural network
- deep learning
- GNN
- SISR
- Graph
- Tissue segmentation
- LIIF
- DIINN
- CrossNet
- Cell detection
- Reference-based SR
- Feature reuse
- ADE20K
- arbitrary scale
- Cell-tissue
- Super-Resolution
- session-based recommendation
- Zero-Shot sr
- TRANSFORMER
- Today
- Total
딥러닝 분석가 가리
Activating More Pixels in Image Super-Resolution Transformer Review 본문
Activating More Pixels in Image Super-Resolution Transformer Review
AI가리 2023. 3. 11. 00:30"Activating More Pixels in Image Super-Resolution Transformer "
Abstract
Transformer 기반의 image super-resolution 같은 low-level vision task는 좋은 성능을 보였다. 하지만, Transformer 기반의 네트워크는 attribution 분석을 통해 제한된 공간 범위의 입력 정보만 사용한다. 이러한 것은 transformer의 잠재력이 여전히 기존 네트워크에 비해 완전히 활용되지 않는다는것을 의미한다. 그래서 더 많은 입력 픽셀을 활성화 하기 위해 HAT(Hybrid Attention Transformer)를 제안한다. HAT는 CA(Channel Attention)과 self-attention을 결합해 서로 상호보완적인 장점을 이용해서 만들었다. 게다가 Cross-window information을 더 잘 통합하기 위해 이웃한 window feature 간의상호작용을 향상 시키기 위해 overlapping cross-attention 모듈을 도입한다. 그리고 훈련단계에서는 성능을 개선시키기 위해 same-task pre-training 전략을 사용한다. 실험 결과에서는 제안한 모듈이 효율적인것을 보여주며 다른 SotA 방법보다 1dB 더 높았다.
1. Intorduction
SR(single image Super-Resolution)은 computer vision과 image processing에서의 고전적인 문제이며 LR(Low Resolution) 이 주어졌을때 HR(High Resoltuion)을 만드는것이 목표이다. SR은 최근 몇년 동안 CNN을 접목하면서 좋은 성능을 보였고, 최근에는 transformer를 사용하고 있다. High-level vision task에 대해 빠른 진전을 이룬 이후, transformer 기반의 방법은 SR 뿐만 아니라 low-level vision에서도 개발되고 있다.
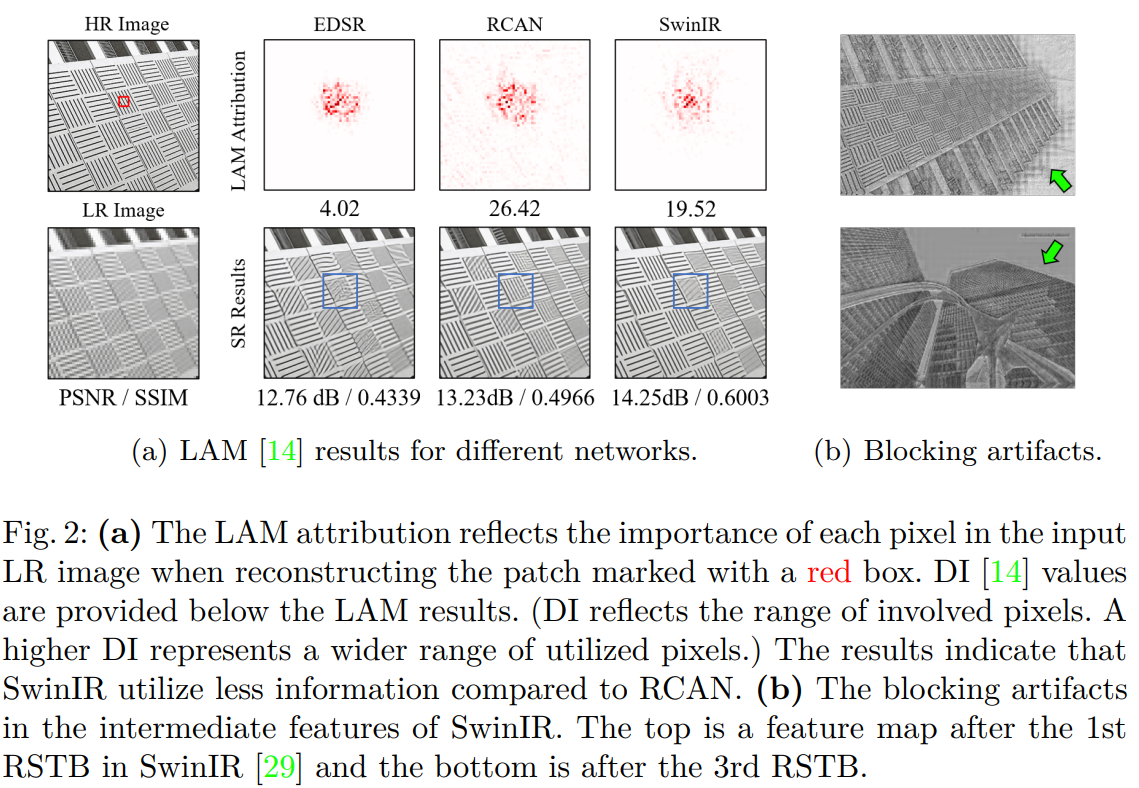
하지만 이러한 성공에도 불구하고, "Transformer가 CNN보다 나은 이유"는 여전히 미스테리로 남아있다. 직관적인 설명은 이러한 종류의 네트워크가 self-attention mechanism으로 부터 이익을 얻고 long-range 정보를 활용할수 있다는 것이다. 하지만 LAM에서 transformer 기반의 SwinIR이 CNN 기반의 방법보다 입력 픽셀을 덜 사용했다(그림 2(a)). 이러한 점에 의해 SwinIR이 RCAN 보다 정량적 결과는 좋을수 있지만, 정성적 결과에서는 더 안좋을수도 있다. 그래서 이러한 현상은 transformer가 local information을 모델링하는 능력이 더 강하지만 활용되는 정보의 범위를 확장할 필요가 있음을 보인다.
이러한 문제점을 해결하기 위해 HAT(Hybrid Attention Transformer)를 제안한다. HAT는 global information을 이용하는 channel attention과 powerful representative ability를 사용하기 위해 self-attention을 결합한다. 또한, Cross-window information을 더 잘 통합하기 위해 overlapping cross-attention module을 도입하고, same-task pre-training 전략을 사용한다. Same-task pre-training은 multi-related-task pre-training보다 더 나은 결과를 보였다. 그림 1은 제안하는 모델이 SotA보다 0.3dB ~ 1.2dB더 높은 성능을 보인다.

Contribution
- 더 많은 input information을 사용하기 위해 channel attention을 도입함
- Cross-window information을 더 잘 통합하기 위해 overlapping cross-attention 모듈을 제안함
- Same-task pre-training 전략을 사용함
2. Method
2.1 Motivation
Swin Transformer는 SR에서 좋은 성능을 낸다는것을 입증했고, CNN보다 더 나은 성능을 보였다. Transformer의 작동 mechanism을 밝히기 위해 SR을 위해 설계된 attribution 방법인 LAM 진단도구를 사용한다. 그림 2(a)의 붉은 점은 재구성하는데 기여한 유용한 픽셀인다. 직관적으로 더 많은 정보를 사용했을때 더 좋은 성능을 보이지만, transformer 기반의 SwinIR은 RCAN보다 더 적은 범위를 표시한다. 이러한 부분은 상식과 모순되지만, 또한 추가적인 통찰력을 제공해준다. 그림 2(a)의 파란 박스 안의 재구성한 결과는 SwinIR이 RCAN보다 poor 하다. 이러한 점은 CA가 RCAN보다 더 많은 픽셀을 보도록 할 수 있다.
- SwinIR은 CNN보다 더 강한 mapping capability을 가져 적은 정보량으로도 더 좋은 성능을 발휘함
- SwinIR은 더 많은 입력 픽셀의 정보를 사용함으로 성능의 개선 여지가 보임
그림 2(b)에서는 SwinIR의 중간 feature map에서 blocking artifacts가 관찰된다. 이러한 artifacts는 window partition mechanism으로 발생하며, shifted window mechanism이 cross-window connection을 구축하는데 비효율적이라고 한다. 몇몇 high-level vision tasks들은 windows를 따라 connection을 강화시키면 window-based self-attention 방법을 개선할수 있을 것이라고 한다. 그래서 이 두 관점을 기반해 Transforemr-baesd 모델의 channel attention을 연구하고 window-based SR Transformer에 대한 cross-window 정보를 더 효과적으로 집계할 overlapping cross-attention 모듈을 제시한다.
2.2 Network Architecture
The Overall Structure.
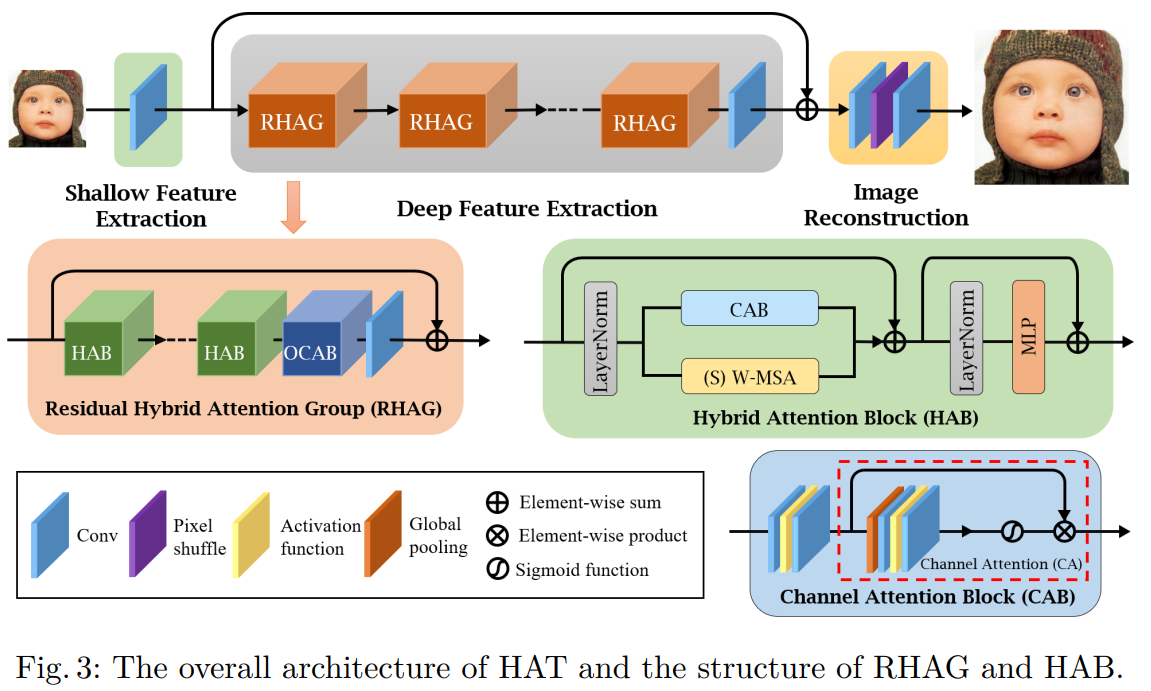
전체 네트워크는 그림 3과 같이 Shallow Feature Extraction, Deep Feature Extractino, Image Reconstruction으로 구성된다. Shallow Feature Extraction은 3x3 conv로 shallow feature를 추출한다. 이때 channel 수는 3에서 96이 된다. Shallow feature extraction은 각 픽셀 토큰에 대한 고차원 임베딩을 달성하는 동시에 저 차원에서 고차원 공간으로 input을 mapping할 수 있다. 또한, 초기 convolutional layer는 더 나은 visual representation을 학습하도록 돕고 안정적인 최적화로 이어지게 할 수 있다.
Deep Feature Extraction은 N개의 RHAG(Residual Hybrid Attention Groups)와 중간 feature를 점진적으로 처리할 수 있는 1개의 3x3 Convolutional layer로 구성된다. RHAG에서 또한, deep feature 정보를 더 잘 통합하기 위해 RHAG 끝 부분에 3x3 Convolutional layer를 도입한다. 이후 shallow feature와 deep feature를 혼합하기 위해 global residual connection(Element-wise sum)을 수행한다.
Image Reconstruction은 HR 영상을 재구성하기 위한 모듈로 3x3 Conv, Pixel-shuffle method, 3x3 Conv를 한다. 이때 Pixel-shuffle 방법으로 혼합된 feature를 up-sample 한다. 파라미터를 최적화 하기 위해 L1 loss를 사용한다.
Residual Hybrid Attention Group (RHAG)
그림 3에 나타나듯이 RHAG 모듈은 M개의 HAB(Hybrid Attention Blocks)와 1개의 OCAB(Overlapping Cross-Attention Block) 그리고 3x3 Convolutional layer로 구성된다. HAB들로 mapping 후, OCAB를 삽입해 window-based self-attention에 대한 receptive field를 확장하고 cross-window informatoin을 더 잘 집계하도록 한다. 마지막에 Convolutional layer를 사용하게 되면 Transformer-based network에 있는 conv 연상의 귀납적 편향을 가져올 수 있고, shallow와 deep 한 feature를 통합하기 위한 더 나은 기반을 만들수 있다. 또한 training process를 안정화 하기 위해 residual connection을 추가한다.
Hybrid Attention Block (HAB)
그림 2(a)에 나온것 처럼 channel attention weights를 계산하기 위해 global information이 포함되기 때문에, channel attention을 채택할 때 더 많은 픽셀이 활성화 된다. 게다가 많은 연구는 Convolution이 Transformer가 더 나은 visual representation을 얻거나 더 쉽게 최적화를 달성하는데 도움이 될 수 있다고 한다. 그래서 네트워크의 representation ability를 강화시키기 위해 channel attention-based convolution block을 Transforemr block에 통합한다. 그림 3에 나타나듯이 LN(Layer Norm) layer 이후, standard Swin Transformer block에 삽입된 CAB(Channel Attention Block)와 W-MSA(Window-based Multi-head Self-Attention)이 있다. SW-MSA(Shifted Window-based Self-Attention)은 Swin Transformer와 비슷하게 연속적인 HABs의 간격으로 채택된다. 최적화 및 시각적 representation에 대한 CAB와 MSA의 connflict 가능성을 피하기 위해 작은 상수 α를 CAB 출력에 곱한다. HAB의 연산은 아래와 같다.
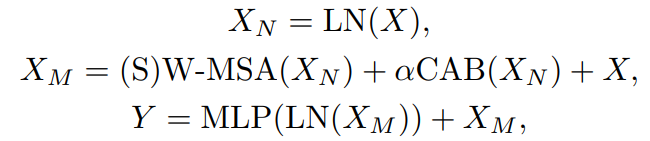
Self-attention 모듈은 입력 feature의 크기가 HxWxC일때 처음에 HW/M^2로 분할되어 (local window size가 MxM) 각 window마다 self-attention이 계산된다. Local window feature X_W ∈ R^(M^2xC)의 경우, query, key and value 행렬은 Q, K, V로 linear mapping을 통해 계산된다. Window-based self-attention 수식은 아래와 같다.
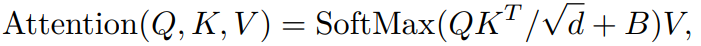
d 는 qurey / key의 차원을 나타낸다. B는 relative position encoding으로 각 위치의 상대적인 위치 정보를 인코딩해 attention 계산에 활용하는 방법이다. B는 Attention is All you Need에서 제시된 방법으로 계산된다. 이를 통해 모델은 입력 시퀀스 내의 각 위치가 다른 위치와 어떤 관계에 있는지를 학습할 수 있다. 또한, 인접한 non-overlapping windows 사이의 연결을 구축하기 위해, shifted window partition 접근법을 사용하고 sifted size를 window size의 절반으로 설정한다.
CAB는 CA 모듈 앞에 Conv layer와 GELU activation function을 사용한다. Transformer 기반의 구조는 종종 토큰 임베딩을 위해 많은 채널을 필요로 하기 때문에, 일정한 폭의 conv를 직접 사용하는것은 큰 계산 비용을 초래한다. 따라서 channel number를 두 conv layer 사이의 상수 β로 압축한다. 첫번째 conv layer에서는 channel을 β만큼 나누어 압축하고 두번째 conv layer에서는 다시 원본 채널 수로 팽창한다.
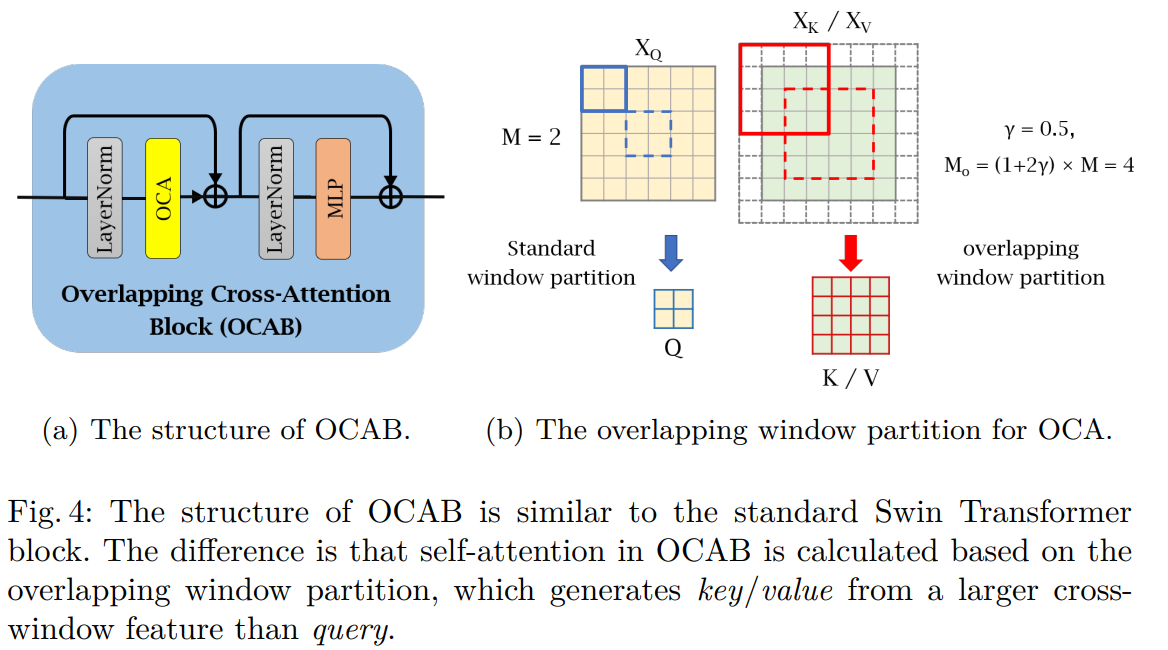
Overlapping Cross-Attention Block (OCAB)
OCAB는 Swin Transformer 기반의 모델에서 window간의 연결성을 향상시키기 위해 제안된 모듈이다. 즉, Cross-window connection을 직접적으로 구축하고 window self-attention을 위해 representative 능력을 강화한다. OCAB는 Swin Transformer block 처럼 OCA와 MLP로 구성된다. 하지만 OCA의 경우 그림 4처럼 다른 window size를 사용해 투영된 feature를 분할한다. OCA layer는 input feature의 다른 window size 간의 attention을 계산해 window간의 정보를 더 잘 집계할 수 있도록 한다. 구체적으로, Q, K, V가 input feature X에 포함된다고 할때, Q는 window size가 MxM인 HW/M^2 non-overlapping으로 분할되고, K, V는 크기가 MoxMo인 HW/M^2 overlapping으로 펼쳐진다. 식은 아래와 같다.
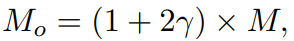
γ는 overlapping size를 조절하는 상수이다. 이 연산을 더 쉽게 이해하기 위해, standard window partition은 kernel size와 stride가 window size M가 동일한 sliding partition으로 고려되어질 수 있다. 대조적으로 overlapping window partition은 kernel size가 Mo와 같은 sliding partition 볼수 있으며, stride는 M과 같다. Overlapping window의 size 일관성을 보장하기 위해 γM 크기의 Zero padding을 사용한다. Attention matrix는 위의 attention식처럼 계산된다. OCA는 q,k,v가 같은 window feature에서 계산되는 WSA와는 다르게, q에 더 유용한 정보를 활용할 수 있는 더 큰 field에서 k/v를 계산한다. MOA(Multi-resolution Overlapped Attention)이 overlapping window partition과 비슷하게 수행하지만 MOA는 window feature를 토큰으로 사용해 global attention을 계산하는 반면 OCA는 픽셀 토큰을 사용해 각 window feature 내부의 cross-attention을 계산하기 때문에 MOA는 OCA과 다르다.
2.3 Pre-training on ImageNet
Low-level task에서 pre-training이 중요한 역할을 한다는 최근 연구 결과 IPT, EDT를 바탕으로 Swin Transformer에도 이 를 적용한것이다. 본 논문에서 사용하는 pre-training 방법은 대규모 데이터셋인 ImageNet을 기반으로 하여 특정 작업에 대한 모델을 사전훈련 하는것이다. 예를들어 4배 SR을 한다고 하면 ImageNet으로 4배 SR을 학습하고 다음 다른 데이터셋으로 fine-tuning을 한다. 이러한 전략을 same-task pre-training이라고 이름 지었으며 다양한 low-level 작업에서 높은 성능을 보이며, 특정 작업에 대해서도 더 나은 성능을 보이게 한다. 저자는 이러한 이유에 대해 Transformer가 일반적인 지식을 학습하기 위해 더 많은 데이터와 반복을 필요로 하지만 특정 데이터셋에 과적합 되지 않도록 미세 조정을 위한 작은 learning rate가 필요하기 때문이라고 생각한다.
3. Experimetns
3.1 Experimental Setup
- DIV2K와 Flicker2K를 합친 DF2K 데이터를 사용하고 pre-training으로는 ImageNet 데이터를 사용함
- HAT 구조에서 RHAG와 HAB block의 수는 3으로, 전체 네트워크의 channel 수는 180으로 설정함
- (S)W-MSA와 OCA 모두 attention head는 6, window size는 16으로 설정함
- CAB의 (α), (β), (γ)는 각각 0.01, 3 그리고 0.5로 설정함
- HAT-L 모델은 HAT에 비해 RHAG의 수를 6에서 12로 늘림
- 평가는 Y channel 기준으로 PSNR과 SSIM을 평가함
3.2 Effects of different window sizes
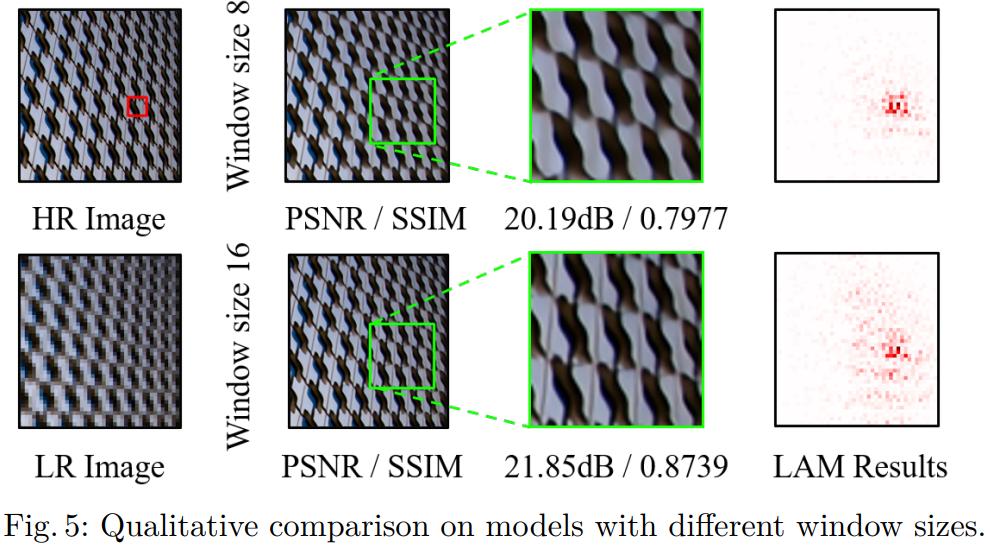
2.1에서 논의한것과 같이 SR에서 더 많은 픽셀을 활성화 하는것이 더 좋은 성능을 이끌어 낸다. 그래서 직관적인 방법으로 window size를 확대해서 실험한다. EDT는 다른 window size에 대한 효과를 조사한다. EDT에서는 shifted cross local attention 방법을 사용해 실험 했으며, window size를 12x12까지 탐색했다. 본 연구에서는 더나아가 window size 에 따라서 self-attention이 representation ability에 어떻게 영향을 미치는지를 연구한다. 정량적 결과는 표1, 정성적 결과는 그림 5에 나타냈다. 실험 결과 window size가 클수록 성능이 향상되는것을 확인했다. 이 결과에 따라 window size의 크기를 16으로 설정한다.

3.3 Ablation Study
Effectiveness of OCAB and CAB
제안된 OCAB와 CAB의 효과를 증명하기위해 실험한다. Urban100 데이터셋에 대해 x4 SR한 정량적 결과는 표 2에 나타난다. 아무것도 사용하지 않은 baseline 보다 OCAB, CAB 두 모듈중 하나를 사용하면 0.1dB 더 높고 두 모듈 모두 사용하면 0.16dB 더 높은 성능을 나타냈다. 또한 이 실험에 대한 정성적 결과를 그림 6에 나타냈다. OCAB를 사용한 모델이 사용된 픽셀의 범위가 더 크고 더 잘 재구성 된 결과를 생성한다는것을 관찰할 수 있다. CAB를 사용하면 사용된 픽셀이 전체 이미지로 확장 된다. 또한 OCAB와 CAB를 사용한 방법의 결과는 가장 많은 입력 픽셀을 활용했다.


Effects of the overlapping size.
γ 값으로 OCAB의 overlapping size를 조절하여 실험한다. Overlapping size를 조절하기 위해 γ 값을 0부터 0.75까지 실험한다. 결과는 표3에 나타나며 γ 가 0 일때는 기본 Transformer block을 말한다. γ 가 0.5일때 성능이 가장 좋았다. 대조적으로 γ 가 0.25거나 0.75일때, 성능의 개선이 없고 오히려 떨어졌다. 이는 부적절한 overlapping size가 인접 window의 상호 작용에 도움이 될 수 없을을 보여준다.

Effects of different designs of CAB.
CAB 구조를 변형하며 성능을 평가한다. 먼저, convolution의 설계와 channel attention의 영향을 조사한다. 결과는 표 4에서 보여지며, depth-wise convolution을 사용했을때 성능이 떨어진다. 이는 depth-wise convolution이 CAB에서 representative ability가 약하다는것을 의미한다. 게다가, channel attention이 성능을 개선시킨다는것을 알 수 있다. 또한 CAB의 weighting factor인 α의 효과를 실험한다. 2.2 절에서 α는 feature 융합을 위한 CAB feature의 weights를 제어하는데 사용된다. α 값이 클 수록 CAB에 의해 추출된 feature의 weights가 크다는 것을 의미하며 0에 가까울 수록 CAB는 사용하지 않는것을 의미한다. 결과는 표 5와 같으며 α가 0.01일때 성능이 가장 좋았다.

3.4 Comparison with State-of-the-Art Methods
Quantitative results.
제안하는 방법인 HAT를 EDSR, RCAN, SAN, IGNN, HAN, NLSN, RCAN-it, pre-training 방법인 IPT, EDT와 비교해 표 6에 나타낸다. 실험결과 다른 모델들보다 우수한 성능을 보였으며 특히, Urban100 데이터 셋에서 다른 모델에 비해 높은 성능 차이를 보였다. 또한, ImageNet에서 pre-training한 모델을 사용하는 경우, 성능이 더욱 개선되는것으로 나타났다.

Visual comparison.
그림 7은 다른 모델들과 정성적 결과를 비교한 결과이다. 제안하는 방법은 lattice content를 성공적으로 복구할 수 있었다. 대조적으로 다른 방법들은 blur한 결과를 나타냈다.

3.5 Effectiveness of the same-task pre-training
표 6에 나타난 바와 같이, same-task pre-training 전략을 사용하는 모델은 pre-training을 사용하지 않는 모델보다 상당히 높은 성능을 보여준다. EDT는 또한 SR에 대한 다양한 pre-training 전략 효과를 연구한다. 이것은 Multi-related-task 즉, x2, x3, x4에 대한 SR 모델을 사전훈련한 것에 기반한 ImageNet pre-training이 single-task pre-training 즉, x4 SR에 대한 x2 SR setup 전략 보다 더 효과적인것을 입증한다. 제안하는 same-task pre-training이 EDT의 pre-training 보다 우수하고 효과적인것을 증명하기 위해 EDT의 전략을 제안하는 모델에 적용해서 비교한다. 표 7은 x4 SR에 대한 모델 결과이다. Same-task pre-training이 pre-training 뿐만 아니라 fine-tuning 과정에서도 더 좋은 결과를 나타낸다. 특정 작업에 대한 pre-training에 비해 multi-task pre-training은 더 좋지 않은 성능을 보인다. 이러한 관점에서 '사전 훈련이 효과가 있는 이유'가 task간의 상관관계 대신 데이터의 다양성에 기인한다고 보는 경향이 있다.

4. Conclusion
- SISR을 위해 HAT(Hybrid Attention Transformer)를 제안함
- Channel attention과 self-attention을 결합해 HR 결과를 재구성하기 위해 더 많은 픽셀을 활성화 함
- Cross-window information을 더 잘 집계하기 위해 window size가 다른 feature간의 attention을 계산하는 overlapping corss-attention 모듈을 제안함
- Same-task pre-training을 제안해 모델의 잠재력을 더욱 활성화 시킴
- 실험에서는 HAT가 SotA 방법들의 성능을 크게 능가함
Paper
https://arxiv.org/abs/2205.04437
Activating More Pixels in Image Super-Resolution Transformer
Transformer-based methods have shown impressive performance in low-level vision tasks, such as image super-resolution. However, we find that these networks can only utilize a limited spatial range of input information through attribution analysis. This imp
arxiv.org
'딥러닝 논문 리뷰' 카테고리의 다른 글
| Graph Neural Network in Image (1) (0) | 2023.04.02 |
|---|---|
| IGNN(Internal Graph Neural Network) Image Super-Resolution Review (0) | 2023.03.29 |
| CSPNet Review (1) | 2023.03.02 |
| Non-local Neural Networks Review (0) | 2023.02.19 |
| RZSR with Depth Guided Self-Exemplars Review (0) | 2023.02.02 |



